一、简单的图像压缩
import cv2
'''
====图像压缩=====
CV_INTER_NN - 最近邻插值,
CV_INTER_LINEAR - 双线性插值 (缺省使用)
CV_INTER_AREA - 使用像素关系重采样。当图像缩小时候,该方法可以避免波纹出现。当图像放大时,类似于 CV_INTER_NN 方法..
CV_INTER_CUBIC - 立方插值.
'''
image=cv2.imread(r"C:\Users\xxx\Desktop\piaoju\0190819210415.png")
res = cv2.resize(image, (image.shape[1],image.shape[0]), interpolation=cv2.INTER_AREA)
cv2.imwrite(r"C:\Users\xxx\Desktop\piaoju\0190819210415_2.png",res)
# 使用一张1.2M的图片直接压缩至868KB。(保持原图片分辨率大小)
ImageEnhance模块:https://blog.csdn.net/icamera0/article/details/50753705
- ImageEnhance.Color(image) 颜色增强类:用于调整图像的颜色均衡
- ImageEnhance.Brightness(image) 亮度增强类:用于调整图像的亮度。
- ImageEnhance.Contrast(image) 对比度增强类:用于调整图像的对比度。
一张1.2M的图片依次先执行压缩(868KB),再提升对比度,再转成灰度图
from PIL import Image
from PIL import ImageEnhance
from PIL import ImageFilter
import cv2
image=cv2.imread(r"C:\Users\xxx\Desktop\piaoju\0190819210415.png")
res = cv2.resize(image, (image.shape[1],image.shape[0]), interpolation=cv2.INTER_AREA)
imgE = Image.fromarray(cv2.cvtColor(res,cv2.COLOR_BGR2RGB))
imgEH = ImageEnhance.Contrast(imgE)
# 当参数为1.2 灰度图243KB,当参数为2.8 灰度图124KB.(亮度提升后转灰度图,图片会黑白分化)
gray=imgEH.enhance(1.2).convert("L")
gray.save(r"C:\Users\xxx\Desktop\piaoju\0190819210415_4.png")
#图像增强
# 创建滤波器,使用不同的卷积核
gary2=gray.filter(ImageFilter.DETAIL)
gary2.save(r"C:\Users\xxx\Desktop\piaoju\0190819210415_5.png")
#图像点运算
gary3=gary2.point(lambda i:i*0.9)
gary3.save(r"C:\Users\xxx\Desktop\piaoju\0190819210415_6.png")
依次是原图,enhance(1.2),enhance(2.8)的图片

二、基于机器学习的图像压缩方法
关于PCA降维,SVD理论详情:https://blog.csdn.net/wsp_1138886114/article/details/80967843
SVD图像压缩
import cv2
import numpy as np
def rebuild_img(u, sigma, v, p): # p表示奇异值的百分比
print('sigma.shape', sigma.shape)
print('sum(sigma)', sum(sigma))
m , n= len(u),len(v)
a = np.zeros((m, n)) # 创建空图片
count = (int)(sum(sigma))
curSum = 0
k = 0
while curSum <= count * p:
uk = u[:, k].reshape(m, 1)
vk = v[k].reshape(1, n)
a += sigma[k] * np.dot(uk, vk)
curSum += sigma[k]
k += 1
print('==k===:', k)
a[a < 0] = 0
a[a > 255] = 255
return np.rint(a).astype("uint8")
if __name__ == '__main__':
img = cv2.imread(r'C:\Users\xxx\Desktop\piaoju\caiyao001.jpg')
for p in np.arange(0.1, 1, 0.2):
u, sigma, v = np.linalg.svd(img[:, :, 0])
R = rebuild_img(u, sigma, v, p)
u, sigma, v = np.linalg.svd(img[:, :, 1])
G = rebuild_img(u, sigma, v, p)
u, sigma, v = np.linalg.svd(img[:, :, 2])
B = rebuild_img(u, sigma, v, p)
I = np.stack((R, G, B), 2)
cv2.imshow("svd_" + str(p * 100),I)
cv2.imwrite("C:\\Users\\xxx\\Desktop\\piaoju\\svd_" + str(p * 100) + ".jpg", I)
cv2.imshow("img" , img)
cv2.waitKey(0)
cv2.destroyAllWindows()

图片大小依次为:19.2KB,20.2KB,28.3KB,40.12KB,49.5KB,50.4KB(原图)
- 小结
-
奇异值分解能够有效的降低数据的维数,以本文的图片为例,从450维降到149维后,还保留了90%的信息
虽然奇异值分解很有效,但是不能滥用,一般情况下要求降维后信息的损失度不能超过5%,甚至是1%
Ng的视频中提到常见的错误使用降维的情况,在这里也贴出来:
使用降维解决过拟合问题
不论什么情况,先用降维处理一下数据,即把降维当做模型训练的必须步骤
PCA图像压缩
pca函数实现图像的降维
关于PCA理论详情请点击:https://blog.csdn.net/wsp_1138886114/article/details/80967843
import numpy as np
import cv2
def comp_2d(image_2d,rate):
height,width = image_2d.shape[:2]
# 执行下面这一行报错显示无法广播。我修改了dtype还是报错,不知道为何。
# cov_mat = image_2d - np.mean(image_2d, axis=1) 。
# print("data.type:", image_2d.astype(np.float64).dtype)
# print("mean.type:", np.mean(image_2d, axis=1).dtype)
#
# print("data.shape:", image_2d.astype(np.float64).shape)
# print("mean.shape:", np.mean(image_2d, axis=1).shape)
# 我自己广播代码为如下三行代码
mean_array = np.mean(image_2d, axis=1)
mean_array = mean_array[:, np.newaxis]
mean_array = np.tile(mean_array, width)
cov_mat = image_2d.astype(np.float64) - mean_array
eig_val, eig_vec = np.linalg.eigh(np.cov(cov_mat)) # 求特征值 特征向量
p = np.size(eig_vec, axis=1)
idx = np.argsort(eig_val)
idx = idx[::-1]
eig_vec = eig_vec[:, idx]
numpc = rate
if numpc < p or numpc > 0:
eig_vec = eig_vec[:, range(numpc)]
score = np.dot(eig_vec.T, cov_mat)
recon = np.dot(eig_vec, score) + mean_array
recon_img_mat = np.uint8(np.absolute(recon))
return recon_img_mat
if __name__ == '__main__':
data = cv2.imread(r'C:\Users\xxx\Desktop\piaoju\caiyao001.jpg')
height, width = data.shape[:2]
a_g = data[:, :, 0]
a_b = data[:, :, 1]
a_r = data[:, :, 2]
rates = [30,60,90] #主成分前30,60,90个k值
for rate in rates:
g_recon, b_recon, r_recon = comp_2d(a_g,rate), comp_2d(a_b,rate), comp_2d(a_r,rate)
result = cv2.merge([g_recon, b_recon, r_recon])
cv2.imshow('result_'+str(rate),result)
cv2.waitKey(0)
cv2.destroyAllWindows()
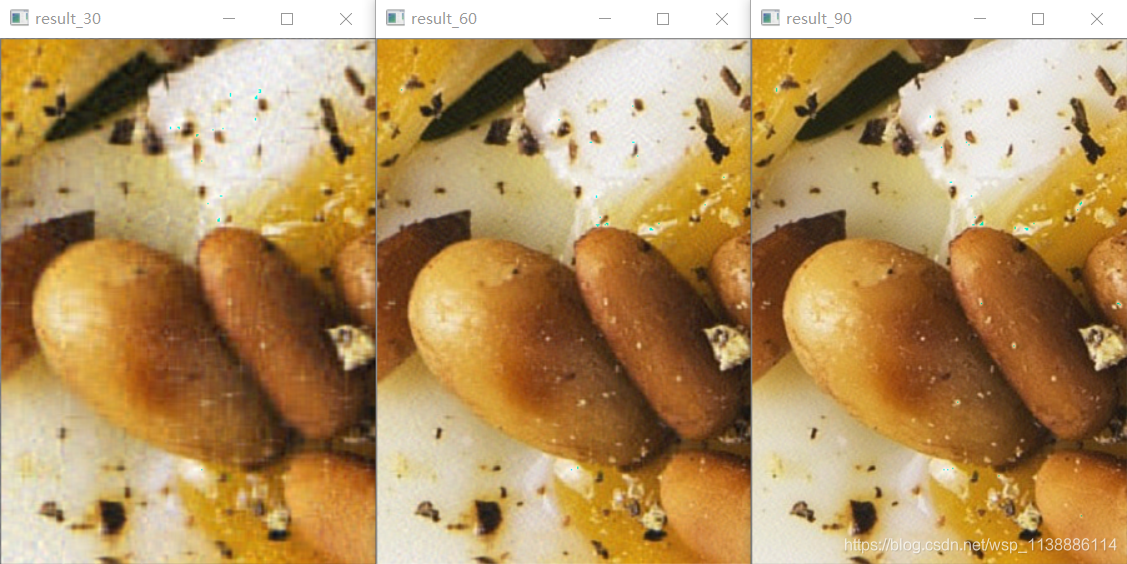
显然,k=30时就包含了矩阵的至少70%的信息含量,当k=90时就包含了矩阵的至少90%信息含量。
代码参考:https://github.com/NourozR/Reconstruction-and-Compression-of-Color-Images/blob/master。
三、基于K-means图像压缩
代码查看请点击:https://blog.csdn.net/wsp_1138886114/article/details/80893941
参考:
https://blog.csdn.net/HHTNAN/article/details/79711046
https://blog.csdn.net/wsp_1138886114/article/details/80893941
https://blog.csdn.net/wsp_1138886114/article/details/80967843
https://github.com/NourozR/Reconstruction-and-Compression-of-Color-Images/blob/master。