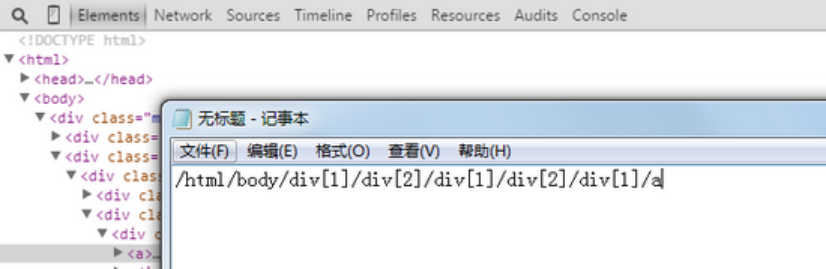
属性描述
XPath 语法支持节点描述,节点描述为一个逻辑真假表达式,任何真假判断表达式都可在节点后方括号里表示,这条件必须在XPath处理这个节点前先被满足。在某一步骤可有多少个描述并没有限制。
对于页面元素, 可用XPath 表示为HTML标签的属性值来定位,以百度首页为例,查看如下几个XPath的表示法:
XPath1: //*[@id="su"]
XPath2: //input[@value="百度一下"]
XPath3: //input[@class="bg s_btn"]
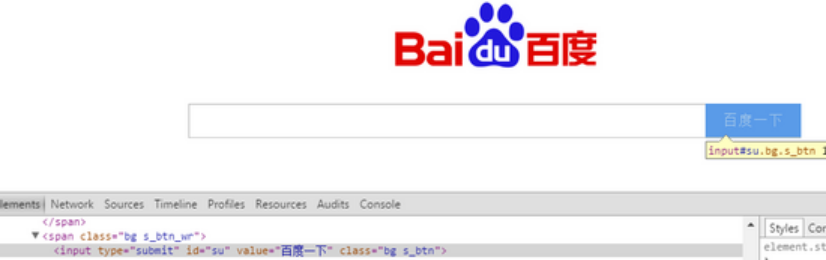
XPath1、2、3 实际上表示的均为“百度一下”这个按钮元素,只是选取的属性值的不同而已。XPath1表示找id为”su”的元素;XPath2表示找value为“百度一下”的input标签元素;而XPath3则表示找class即样式名为”bg s_btn”的input标签元素。
这就解释了开头我所说的XPath同取id、CSS、Name等方式的做法,即可理解为取HTML标签的属性罢了,而且该方式更具灵活性,可做多种及多层的匹配,如单取CSS为”test”,则会取出所有CSS为”test”的元素,而若写成XPath方式,如 //input[@class="test"] ,则取出的是CSS为”test”且仅为input的元素;若可知上层id,如 //div[@id="test"]//*[@class="test"] ,则定位的是id为”test”div下所有class为”test”的元素。甚至有更灵活的模糊匹配方式,如若XPath为 //a[contains(text(),'新')] ,表示为所有包含”新”这一文字的a元素,如“新闻”a标签就会被定位出。
备注:1.开头是两个斜线(//)代表相对路径;2.使用了通配符 * 表示匹配任意
有时要定位多个元素,即需选取一组满足要求的元素组,XPath使用上也是相当方便的,示例如下:
XPath4: //a[@class="mnav"]
XPath5: //a[@class="mnav"][2]
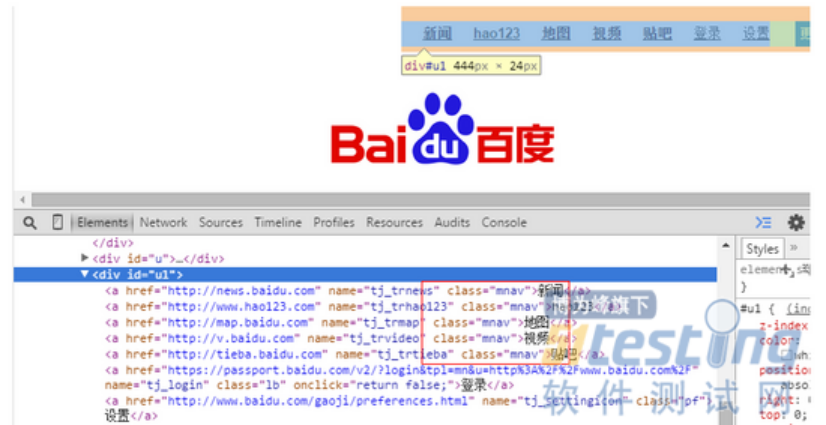
层级定位