| Github项目地址 | |
|---|---|
| 合作同学作业地址 |
Part 1. PSP表格
| PSP2. | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 80 |
| · Estimate | · 估计这个任务需要多少时间 | 60 | 80 |
| Development | 开发 | 700 | 785 |
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 45 |
| · Design Spec | · 生成设计文档 | 30 | 45 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 30 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 25 |
| · Design | · 具体设计 | 40 | 40 |
| · Coding | · 具体编码 | 300 | 400 |
| · Code Review | · 代码复审 | 90 | 80 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 90 | 120 |
| Reporting | 报告 | 90 | 120 |
| · Test Report | · 测试报告 | 30 | 60 |
| · Size Measurement | · 计算工作量 | 30 | 40 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 20 |
| 合计 | 850 | 985 |
Part 2. 计算模块接口的设计与实现过程
一、解题思路
- 字符统计:遍历判断字符是否为空,对不为空的字符进行累加,统计出字符的总数
- 单词统计:先对单词的大小写进行统一,比如说:Word,WORD,Word是同一个单词,我们将大写字母转化成小写字母。再对单词的词数进行统计,将文件中的字符存入一个字符串数组中,对该数组中的字符串进行判断比较找出不同的则次数加1。
- 行数统计:遍历判断是否为空行,对不是空行的行数进行累加,统计出非空的行数。
- 单词频数统计:将单词和该单词的频数存入一个集合中<string,int>,分别表示单词和单词频数。对所有单词的频数进行字典序排序。最终输出一定数量的单词个数以及其频数。
- 词组长度统计:将单词和其长度按照统计单词频数的方法存入一个集合中<string,int>,分别表示单词和词长。当要想得到一个长度的单词时,在其中查找,打印出该长度的所有单词。
所以,在设计过程中我们把本程序功能分为两大类:
1.基本功能。具体分为:
- 统计文件的字符数;
- 统计文件的单词总数;
- 统计文件的有效行数;
- 统计文件中各单词的出现次数;
- 按照字典序输出到文件txt。
2.新增功能。具体分为:
- 统计文件夹中指定长度的词组的词频;
- 输出用户指定的前n多的单词与其数量:
- 参数设定读入的文件路径;
- 参数设定统计的词组长度;
- 参数设定输出的单词数量;
- 参数设定生成文件的存储路径。
二、代码组织
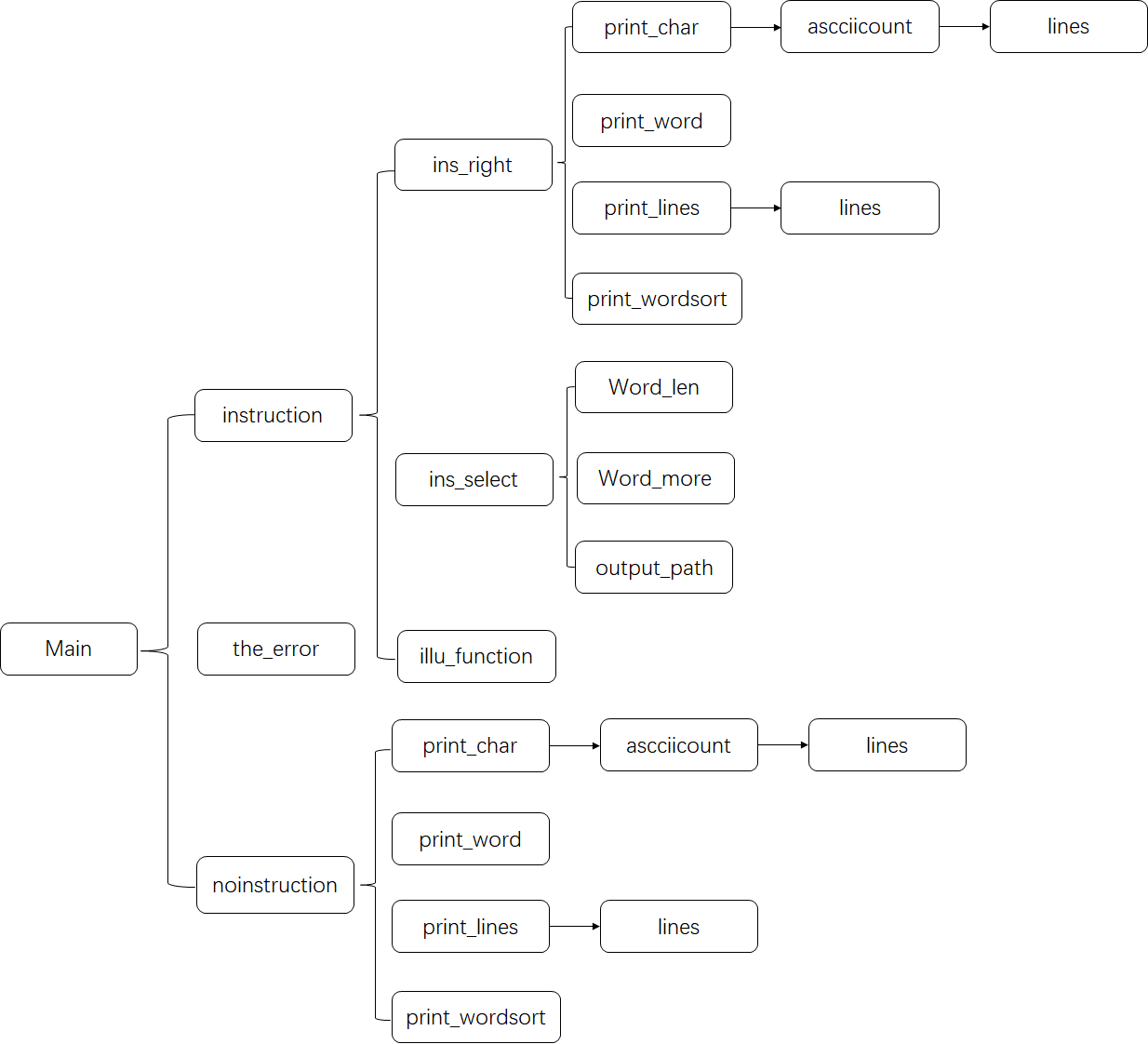
在实现过程中本程序包含了10个类,16个函数,如下表所示:
| 类名 | 函数 | 功能 |
|---|---|---|
| Program | Main | Main:对于用户选择是否需要指令参数进行处理 |
| select_way | instruction nointrction the_error | instruction:对于需要指令参数的情况进行处理。nointrction:对于需要指令参数的情况进行处理。the_error:对于异常情况进行处理 |
| file_path | 无 | 声明输入、输出文件路径变量 |
| result | print_char print_word print_lines print_wordsort print_selectedlong | print_char:输出字符数。print_word:输出单词总数。print_lines:输出有效行数。print_wordsort:输出单词排序。print_selectedlong:查找规定长度的单词。 |
| asccII_count | ascciicount | ascciicount:统计字符的个数 |
| word_count | word_sum word_frequency | word_sum:打印频数高的单词。word_frequency:打印该单词的频数 |
| line_count | lines | lines:统计文件的行数 |
| ins_process | ins_select ins_right | ins_select:对于用户选择的指令参数进行处理。ins_right:对已选择的指令进行相应的赋值 |
| uniform_character | uncharater | uncharater:统一字符大小写 |
函数之间的关系可用下图表示:
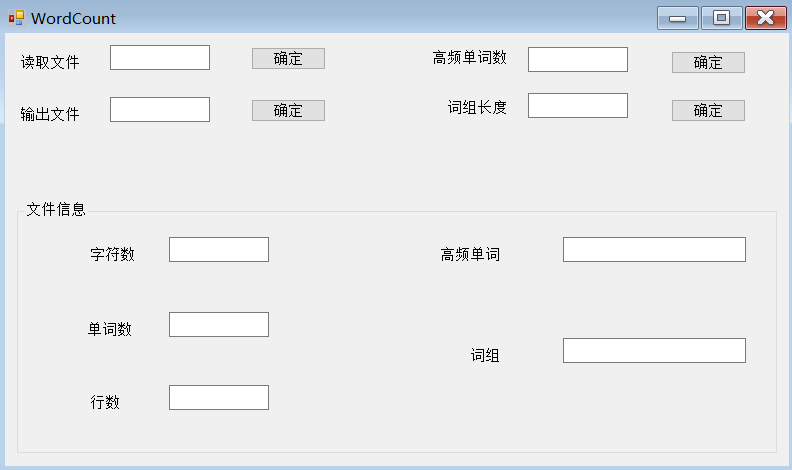
最后,附上用户交互界面:
Part 3.代码复审
一、代码规范
1.命名约定
- 对于类名和变量名,我们都采用“aa_bb”的命名方式,其中aa表示变量名,bb表示操作名。
2.注释约定
- 将注释放在单独的行上,而不是放在代码行的末尾;
3.布局约定
- 使用默认的代码编辑器设置(智能缩进,四字符缩进,制表符另存为空格)。
- 每行只写一条语句;
- 每行只写一条声明;
- 如果连续行没有自动缩进,请缩进一个指标位(四个空格)。
二、代码互审
在代码互审过程中,我主要关注的是具体功能是否能够实现、代码是否符合规范、异常处理以及代码的结构。在代码互审的过程中我们遇到的问题以及改进方法如下:
- 原来版本打开exe文件只能进行无指令操作,经过改进,我们可以进行选择,既能无指令操作又能有指令操作。
- 原来版本的代码结构的方法比较简单,即就几个大的功能的类,没有细分功能的实现,改进后,我们的代码结构更有逻辑性,能容易理解,方便团队协作。
- 原来版本的对异常的处理比较少,对于许多错误指令没有考虑,没有提示,改进后,我们会加入错误指令的提示。
Part 4.计算模块接口部分的性能改进
在改进计算模块性能的过程中,我们发现的问题以及改进思路如下:
1.对统一字符的处理,原来需要对一个单词的每一个字符用for循环来依次判断,再对产生的flag进行判断,而这样的对时间和空间的占用率较高,我们将去到for循环,对一个单词统一判断,减少判断次数和循环次数。提高代码的运行速度。
2.对于使用率较高的word_wore和word_len两个参数,原来是放在一个类里面,导致其他地方调用十分复杂,所以我们对两个参数进行封装重构,减少了代码的臃肿。
使用VS的性能探查器得到的效能分析报告如下图:
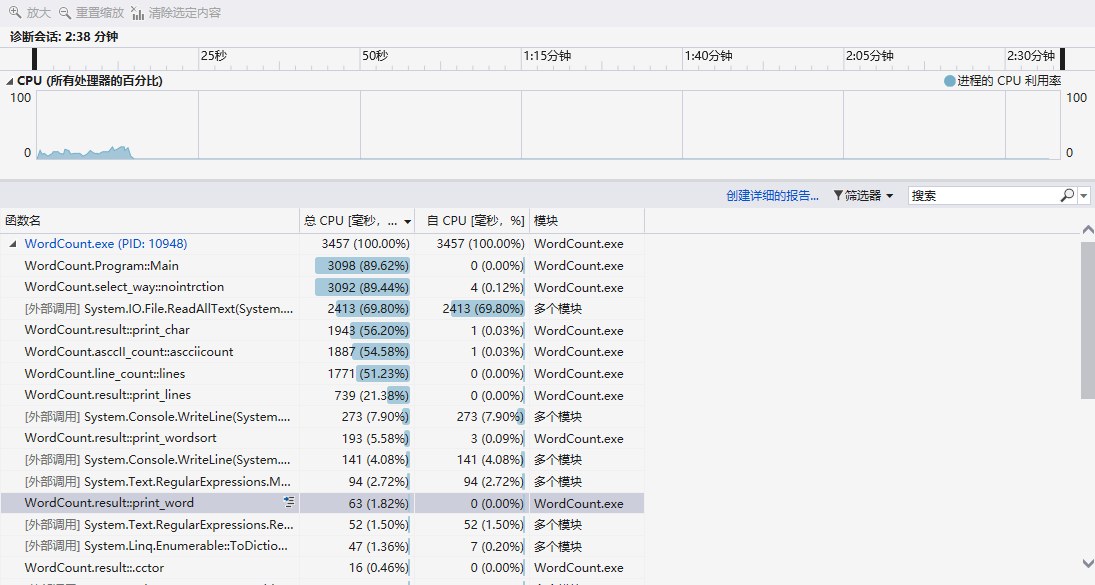
从上图中我们可以看到,result类中的print_char函数在总CPU耗时中占用了56%左右,由于print_char函数只是由打印语句和调用line_count中的lines函数构成,所以在总CPU耗时最多的函数等价为lines函数。
Part 5.计算模块部分单元测试展示
- 对word_count类中的word_sum方法进行测试:新建一个字典集合,向集合中添加一个单词,比较添加后的情况。
public void Test_word_sum()
{
//
// TODO: 在此处添加测试逻辑
//
Dictionary<string, int> frequen = new Dictionary<string, int>();
file_path.output_path=@"E:\GITwrod\WordCount\201731062322\WordCount\UnitTest_WordCount\testoutfile.txt";
string a = "word";
frequen.Add(a, 1);
//frequen.Add("word",1);
Assert.AreEqual(1, word_count.word_sum(frequen));
// Assert.Fail();
}
L%7BY.png)
- 对字符统计的测试:读取文件内容(该文件为空文件),比较文件中的字符数与人工算出的字符数是否相等,相等则测试成功,否则失败。
public void TestMethod1()
{
//
// TODO: 在此处添加测试逻辑
//
file_path.input_path = @"E:\GITwrod\WordCount\201731062322\WordCount\UnitTest_WordCount\testfile.txt";
int num = 0;
Assert.AreEqual(num, asccII_count.ascciicount());
//Assert.Fail();
}
IZGG$XA5V9S1A5JX.png)
3.对行数统计的测试:与测试字符数的方法类似,读取文件内容(该文件为空文件),比较文件中的行数与人工算出的字符数是否相等,相等则测试成功,否则失败。因为本程序是除去了空行的,所以当没有显示的字符(空格不显示)的时候为零行。
public void TestMethod1()
{
file_path.input_path = @"E:\GITwrod\WordCount\201731062322\WordCount\UnitTest_WordCount\testfile.txt";
int x = 0;
Assert.AreEqual(x, line_count.lines());
// Assert.Fail();
}

Part 6.计算模块部分异常处理说明
在本程序中,异常处理主要是针对用户输入的异常处理:
1.在选择是否使用指令参数时的异常处理。如果用户输入了不存在或者错误的选项,则报错:
switch(cmd_num)
{
case 1: select_way.instruction();
break;
case 2: select_way.nointrction();
break;
default: select_way.the_error();
break;
}public static void the_error()
{
Console.WriteLine("the error instruction");
Console.ReadKey();
}2.在输入指令参数是的异常处理。如果用户输入了不存在或者错误的参数,则报错:
else
{
Console.WriteLine("the wrong instruction");
Console.ReadKey();
}3.在没有输入输入文件路径时的异常处理。如果用户没有输入输入文件路径就要进行下一步,则报错:
if(x%2==0)
{
Console.WriteLine("need a input file");
Console.ReadKey();
}Part 7.描述结对的过程


Part 8.心得体会
在项目编写中,我主要负责的功能模块是行数统计和字符统计,代码逻辑不是很复杂,采用的暴力搜索求解,但也由于这个原因,导致我写的这两个功能在占用总CPU耗时方面都是最多的,想要改进却也无从下手,下来应该多多学习。
在合作的过程中,由于是分工行动,两个人产生的分歧不多,在互审时通过同伴的提醒能够发现自己的不足,并加以改进,我认为这是一个人做项目很难自己发现的,而且能一定程度的提高代码的质量。这次的结对编程我认为对以后的团队项目打下了合作的基础,让我意识到该如何高效的合作、和平的合作,毕竟团队合作也能转换为多个一对一合作。
所以我认为:1+1>2。