目的
总结一下常用的输入输出格式。
输入格式
Hadoop可以处理很多不同种类的输入格式,从一般的文本文件到数据库。
开局一张UML类图,涵盖常用InputFormat类的继承关系与各自的重要方法(已省略部分重载)。
DBInputFormat
- DBInputFormat,用来处理数据库输入的一种输入格式。KEY为LongWritable格式,表示包含的记录数;VALUE为DBWritable格式,需要根据自己的表结构继承、实现DBWritable。
- 使用需通过其setInput方法指定输入类、表名、字段集合、查询条件集合和排序条件,或者使用setInput的另一个重载方法直接指定输入类、SQL查询语句、统计数据条数的SQL查询语句。
- 其createDBRecordReader方法会根据Configuration中的数据库类型,返回对应的RecordReader,如OracleDBRecordReader、MySQLDBRecordReader。
- 其分片逻辑为,若已指定mapper数量,则按指定的mapper数等分查询出的数据量(最后一片统收余出的部分),若未指定mapper数,则默认一个分片。
- 由其派生出的DataDrivenDBInputFormat,顾名思义是一种数据驱动的数据库输入格式,与DBInputFormat的区别在于,DataDrivenDBInputFormat能从数据的角度去做分片控制,指定某一列作为边界参考(setBoundingQuery),按mapper数划分分片。
FileInputFormat
- FileInputFormat,所有文件类输入格式的父类。实现了较为通用的方法,如getSplits、isSplitable、listStatus。
- 默认文件可切分
- 默认忽略输入目录中的隐藏文件(文件名以'_'或‘.’开头的文件)
- 默认分片方式为按块分片,并算上1.1的分片溢出值。
TextInputFormat
- TextInputFormat,FileInputFormat的<LongWritable, Text>子类,以当前行偏移字节数为key,当前行内容为value。
- 重载了isSplitable方法,判断方法为通过输入文件后缀判断当前文件所使用的压缩方式是否支持切分。
- 实现了自己的createRecordReader方法,具体逻辑在LineRecordReader。
KeyValueTextInputFormat
- KeyValueTextInputFormat,FileInputFormat的<Text, Text>子类,以当前行内容的分隔符左侧内容为key,当前行内容的分隔符右侧内容为value。
- 可通过属性mapreduce.input.keyvaluelinerecordreader.key.value.separator自定义分隔符,默认分隔符为制表符(\t)。
- 如果该行不存在定义的制表符,则Key为整行内容,Value为空。
- 重载了isSplitable方法,判断方法为通过输入文件后缀判断当前文件所使用的压缩方式是否支持切分。
- 实现了自己的createRecordReader方法,具体逻辑在SplittableCompressionCodec。
NLineInputFormat
- NLineInputFormat, FileInputFormat的<LongWritable, Text>子类,以当前行偏移字节数为key,当前行内容为value。
- 分片方式为,逐文件逐行读取N行作为一个输入分片(有大输入量的情况下,这一步岂不是效率极低?!)
- 行数N由属性mapreduce.input.lineinputformat.linespermap配置或调用其setNumLinesPerSplit方法设置。
- 实现了自己的createRecordReader方法,具体逻辑在LineRecordReader。
SequenceFileInputFormat
- SequenceFileInputFormat,FileInputFormat的针对SequenceFile的子类。
- 重载了getFormatMinSplitSize方法,返回100k。
- 重载了listStatus方法,实现查找SequenceFile中的目录(MapFile)。
- 有两个典型的子类:SequenceFileAsTextInputFormat和SequenceFileAsBinaryInputFormat。前者类似与本类,是其父类的<Text, Text>形式;后者是其父类的<BytesWritable,BytesWritable>形式。
CombineFileInputFormat
- CombineFileInputFormat,FileInputFormat的虚子类,能将多个文件合并到一个输入分片,常用来处理输入为大量小文件的情况。已有的实现子类有CombineTextInputFormat和CombineSequenceFileInputFormat,分别用来处理普通文本文件和SequenceFile的输入。
- 分片有关的三个变量maxSplitSize, minSplitSizeNode, minSplitSizeRack, 须满足关系maxSplitSize >= minSplitSizeRack >= minSplitSizeNode。
- 分片逻辑为:先按已设置的路径过滤器,分别过滤出各自对应的输入文件池,再对各自的输入文件池做分片。
- 分片原则为优先node-local>rack-local>internet,即同一分片内所有的块,优先是位于同一数据节点、其次位于同一机架、再次位于多个机架。
- 针对某一文件池分片具体做法为:1)将同一节点上的所有块汇总后,按maxSplitSize做切分,直至完美切分没有剩余,或最后剩余小于minSplitSizeNode的“节点尾巴”;2)按1)中的做法处理同一机架下所有节点后,汇总所有“节点尾巴”,继续按maxSplitSize切分,直至完美切分或剩余小于minSplitSizeRack的“机架尾巴”;3)按1)和2)中的做法处理完所有机架后,汇总所有“机架尾巴”,继续按maxSplitSize切分直至结束,不留尾巴。
输出格式
与输入格式类似,Hadoop中有分别与之对应的输出格式。常用输出格式类图如下所示: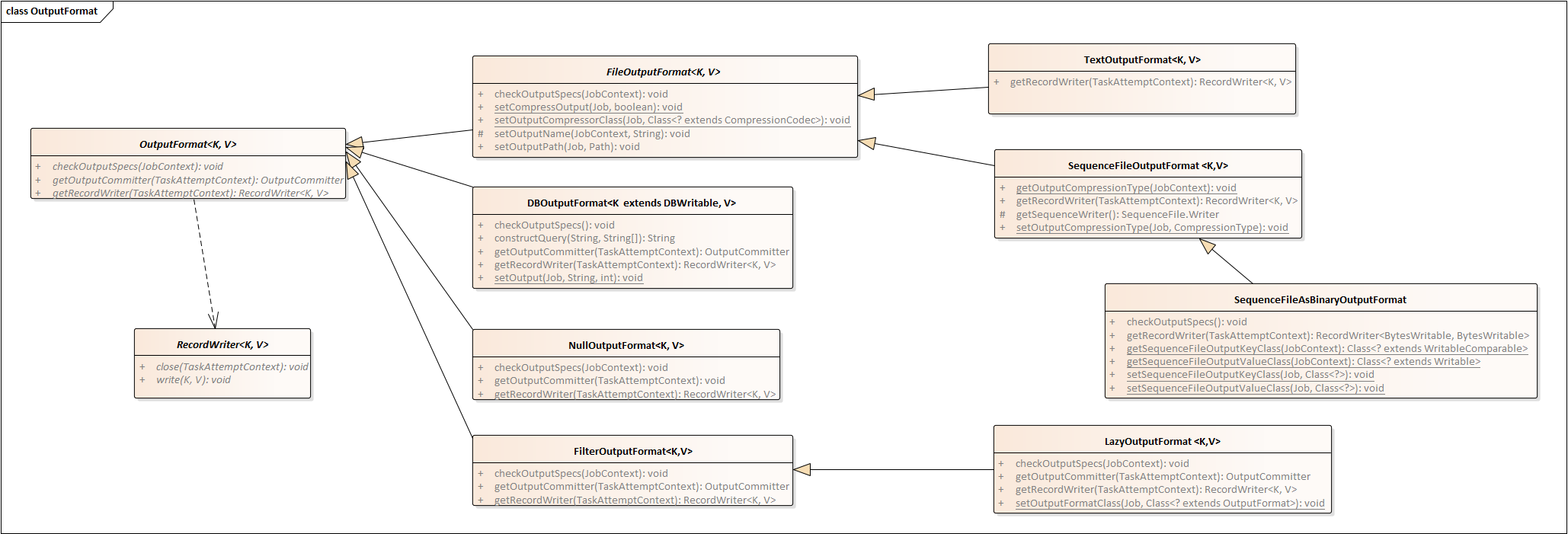
DBOutputFormat
用于将结果输出到数据库表中。可通过其静态方法setOutput设置输出的表名等信息。
NullOutputFormat
OutputFormat的空实现,即实现无任何输出。
LazyOutputFormat
懒惰输出格式,即只有真正产生输出的时候,才创建输出文件。
FileOutputFormat
文件型输出的虚父类,实现了设置/获取压缩格式、检查输出目录、设置/获取输出路径的方法。
TextOutputFormat
将输出写到普通文本文件的输出格式,它把每条记录写成(键\t值)组成的文本行。
SequenceFileOutputFormat
将输出写入顺序文件SequenceFile,其子类SequenceFileAsBinaryOutputFormat则专用于把键/值对作为二进制格式写入到SequenceFile容器中。