java集合类有哪些
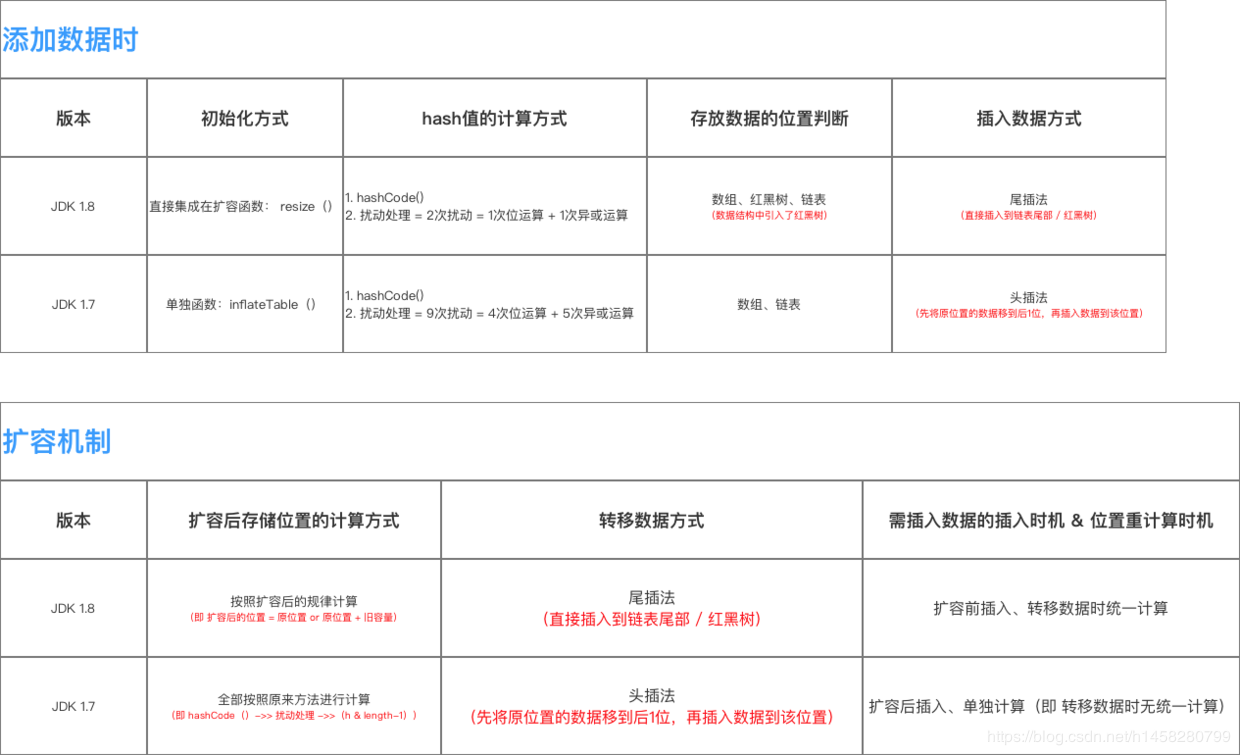
Hashmap中1.7和1.8主要区别
HashMap是我们开发中经常使用到的集合,jdk1.8相对于1.7底层实现发生了一些改变。1.8主要优化减少了Hash冲突 ,提高哈希表的存、取效率。
底层数据结构不一样,1.7是数组+链表,1.8则是数组+链表+红黑树结构(当链表长度大于8,转为红黑树)。
JDK1.8中resize()方法在表为空时,创建表;在表不为空时,扩容;而JDK1.7中resize()方法负责扩容,inflateTable()负责创建表。
1.8中没有区分键为null的情况,而1.7版本中对于键为null的情况调用putForNullKey()方法。但是两个版本中如果键为null,那么调用hash()方法得到的都将是0,所以键为null的元素都始终位于哈希表table【0】中。
当1.8中的桶中元素处于链表的情况,遍历的同时最后如果没有匹配的,直接将节点添加到链表尾部;而1.7在遍历的同时没有添加数据,而是另外调用了addEntry()方法,将节点添加到链表头部。
1.7中新增节点采用头插法,1.8中新增节点采用尾插法。这也是为什么1.8不容易出现环型链表的原因。
1.7中是通过更改hashSeed值修改节点的hash值从而达到rehash时的链表分散,而1.8中键的hash值不会改变,rehash时根据(hash&oldCap)==0将链表分散。
1.8rehash时保证原链表的顺序,而1.7中rehash时有可能改变链表的顺序(头插法导致)。
在扩容的时候:1.7在插入数据之前扩容,而1.8插入数据成功之后扩容。
java虚拟机的栈内存
- 是什么?
- 用于作用于方法执行的一块Java内存区域
- 为什么?
- 每个方法在执行的同时都会创建一个栈帧(Stack Framel)用于存储局部变量表(局部变量的位置引用地址)、操作数栈、动态链接(引用其他对象的地址)、方法出口(return返回值)等信息。每一个方法从调用直至执行完成的过程,就对应着一个栈帧在虚拟机栈中入栈到出栈的过程
- 特点?
- 局部变量表存放了编译期可知的各种基本数据类型(boolean、byte、char、short、int、float、long、double)以及对象引用(reference 类型)
- 如果线程请求的栈深度大于虚拟机所允许的深度,将抛出 StackOverflowError 异常
什么情况下发送内存溢出,什么情况下发送栈内存溢出
哪些对象可能会被gc回收
数据库中如何解决不可重复读的发生
聚合索引
聚集索引和非聚集索引的根本区别是表记录的排列顺序和与索引的排列顺序是否一致,聚集索引表记录的排列顺序与索引的排列顺序一致,优点是查询速度快,因为一旦具有第一个索引值的纪录被找到,具有连续索引值的记录也一定物理的紧跟其后。聚集索引的缺点是对表进行修改速度较慢,这是为了保持表中的记录的物理顺序与索引的顺序一致,而把记录插入到数据页的相应位置,必须在数据页中进行数据重排,降低了执行速度。建议使用聚集索引的场合为:
a.此列包含有限数目的不同值;
b.查询的结果返回一个区间的值;
c.查询的结果返回某值相同的大量结果集。
非聚集索引指定了表中记录的逻辑顺序,但记录的物理顺序和索引的顺序不一致
,聚集索引和非聚集索引都采用了B+树的结构,但非聚集索引的叶子层并不与实际的
数据页相重叠,而采用叶子层包含一个指向表中的记录在数据页中的指针的方式。非
聚集索引比聚集索引层次多,添加记录不会引起数据顺序的重组。建议使用非聚集索
引的场合为:
a.此列包含了大量数目不同的值;
b.查询的结束返回的是少量的结果集;
c.order by 子句中使用了该列。
redis有哪些常见数据结构
redis中有序集合的底层实现是什么
数据库事务的特点
spring中的IOC和AOP
tcp和udp的区别
TCP和UDP都是传输层协议,但是两者具有不同的特性和应用场景
| TCP | UDP | |
|---|---|---|
| 可靠性 | 可靠 | 不可靠 |
| 连接性 | 面向连接 | 面向无连接 |
| 报文 | 面向字节流 | 面向报文 |
| 效率 | 低 | 高 |
| 双工性 | 全双工 | 一对一、一对多、多对一、多对多 |
| 流量控制 | 滑动窗口 | 无 |
| 拥塞控制 | 慢开始、拥塞避免、快重传、快恢复 | 无 |
| 传输速度 | 慢 | 快 |
| 应用场景 | 对效率要求低,对准确度要求高或者要求有连接的场景。比如:电子邮件(SMTP)、万维网(HTTP)、文件传输(FTP) | 对效率要求高,对准确度要求低的场景。比如:域名转换(DNS)、远程文件服务器(NFS) |
名词解释:
1 面向报文和面向字节流
面向报文的传输方式是应用层交给UDP多长的报文,UDP就发送多长的报文,即一次发送一个报文。因此应用程序必须选择大小合适的报文。报文太长,则IP层需要分片,降低效率。
面向字节流的传输方式是应用程序和TCP的交互是一次一个数据块(大小不等),TCP把这些数据块看成是一连串无结构的字节流。TCP有一个缓冲,当应用程序传送的数据块太长,TCP就会把它分割成多块传送。
2 双工性
全双工:是指在发送数据的同时也能够接收数据,两者同步进行,这好像我们平时打电话一样,说话的同时也能够听到对方的声音。目前的网卡一般都支持全双工。
半双工:所谓半双工就是指一个时间段内只有一个动作发生,举个简单例子,一条窄窄的马路,同时只能有一辆车通过,当目前有两量车对开,这种情况下就只能一辆先过,等到头儿后另一辆再开,这个例子就形象的说明了半双工的原理。
tcp的三次握手和四次挥手
慢开始和拥塞控制原理
数据库索引,索引的数据结构