1.特殊符号
' ' 所见即所得。原样输出。
" " 特殊符号会被解析运行
` ` 相当于$(),先运行括号里面的命令,把结果留下
> 重定向(先清空文件,再追加内容到文件)
>> 追加重定向(在文件最后追加内容)
2> 错误重定向
2>> 错误追加重定向
~ 当前用户家目录
! 查找并运行历史命令。eg:!sed 查找最近的一条,包含sed的命令并运行。一般不用这个,用:history |grep sed
# 注释或root的命令行提示符
$ 取变量的值 或 普通用户的命令行提示符
* 所有;任何东西
\ 转义字符
&& 前一个命令执行成功,再执行后一个命令。eg:ifdown eth0 && ifup eth0
|| 前一个命令执行失败,再执行后一个命令
2.通配符
通配符是用来查找文件的
* 表示所有,任意
{} 生成序列
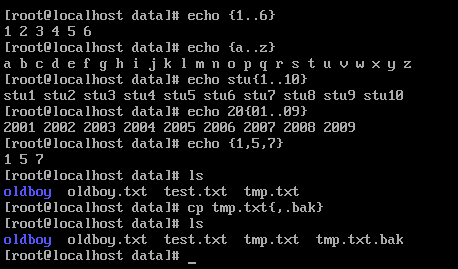
3.正则表达式
通过符号表示文字内容。正则表达式是按照行进行处理的;禁止使用中文符号。
通配符和正则的区别:
通配符--用来匹配查找文件名,linux大部分命令均可使用
正则--在文件中匹配查找内容。grep/sed/awk/find命令支持,java、python这些高级语言内支持。
正则分类:
基础正则:^ . * $ [] [^] basic regular expression BRE
扩展正则:| + {} () ? extened regular expression ERE
^ 行首
.(点) 任何一个字符,不匹配空行
* 匹配前一个字符连续出现0次或1次以上 >=0次。注意:连续出现0次====什么也没有,就会把整个文件内容都显示出来。如:grep "w*" tmp.txt 会将tmp.txt整个文件内容显示出来
$ 行尾
[] [ABC]------匹配A或B或C。中括号相当于一个符号,一次只匹配一个字符。
[^] [^ABC]------排除A或B或C的内容
.* 所有字符,所有符号
| 或者。如:egrep "456|abc" tmp.txt
+ 匹配前一个符号1次或多次 >=1次。可以把连续的东西通过正则匹配出来,一般与 [] 配合使用。
{} g{n,m}--前一个字符最少出现n次,最多m次;g{n}--前一个字符出现了n次;g{,m}--前一个字符最多出现m次;g{n,}--前一个字符最少出现n次。
() 括号中内容相当于是一个整体。用于后向引用(反向引用)。常用于sed。eg:sed -r 's#.(.)..(..)#\2#g' test.txt sed -r 's#(.*)#\1#g' test.txt egrep "gr(a|e)y" test.txt
? 前一个字符连续出现0次或1次
支持基础正则 基础+扩展正则
grep egrep或grep -E
sed sed -r
awk awk