1.find 查找到想要的文件或目录
格式:find [path] [-OPTION] [-exec |grep |xargs -ok -print | ……] [command {} \;]
参数:
-type 以类型查找
f 文件
d 目录
-name 以文件名查找
-size 根据问价大小来查找。eg: find /data -size 5M
-perm 根据文件权限查找。 eg: find /data -perm 755
-maxdepth n 显示的最大层数。(这个参数通常放在第一个,否则的话会有警告信息)。 eg: find /data/ -maxdepth 2 -type d
-exec command {} \; 对匹配的文件执行该参数给出的命令。形式为 command {} \;
-ok 与-exec作用相同。区别在于,执行命令之前,都会给出提示,让用户确认是否执行。
-mtime -n/+n 根据修改时间找出对应的文件。-n指n天以内;+n指n天以前。天数前面必须要有加号或减号,否则不会有查找结果。
eg:find -type f -name "*.log" -mtime +7|xargs ls -l 或 ls -l $(find -type f -name "*.log" -mtime 7) 或 find -type f -name "*.log" -mtime 7 -exec ls -l {} \;
! 取反。注意:符号前后至少一个空格。 eg: find /data -maxdepth 2 -type d ! -name "."
find不加任何参数-----显示当前目录下的所有文件(包括子目录及子目录内的文件)
2.grep 过滤。在文件中找到想要的内容
格式:grep 参数 查找用的关键字符 文件名
参数:
-v 排除。 eg:grep -v "num" test.txt 将test.txt文件内,非包含num字符的 行 显示出来
-An 将匹配到的字符所在行显示出来,并显示次行下面的n行。 eg:grep A15 “num” test.txt 将test.txt文本内,匹配到num字符的行显示,并显示此行下面15行
-n 显示匹配到的字符所在的行内容,及其行号。
-o 显示grep的执行过程,即每次匹配到的内容。涉及到正则的话,就是正则每次匹配到的内容。
egrep 支持高级正则。相当于grep -E
3.sed 取行。多用于替换。默认会显示文件的全部内容。也可用于查找内容(这个用的比较少)
格式:sed 参数 匹配行/替换/查找的字符 文件名
参数:
-n 取消默认输出。即取消默认显示全部内容,一般与p搭配使用。
-r 表示支持扩展正则。
-i 修改文件内容
eg:
取行:sed -n '20,30p' test.txt 显示test.txt文件第20行到第30行的内容。
sed -n '20p' test.txt 显示test.txt文件第20行的内容。
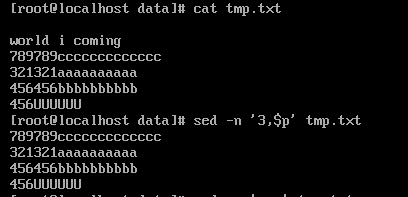
sed -n '3,$p' test.txt 显示第3行到最后一行。
注意:显示前多少行或后多少行,可以用head或tail命令。搭配sed显示具体的某行或区间行。关于行的显示查看就能完全搞定。
替换:sed -i 's#找谁#替换为什么#g' test.txt eg: sed -i 's#nm#DDD#g' test.txt 将test.txt文件内的nm全部替换为DDD
注:替换时sg中间的三个符号,什么都可以,但是一般常用@或#,即s@@@g或s###g
搭配find可替换多个文件内容:
find /data/ -type f -name "*.sh" |xargs sed -i 's#abc#kpl#g' 找出/data文件夹内所有以.sh结尾的文件,替换所有文件内的abc为kpl.
sed -n '2s#abc#123#gp' test.txt 将第2行的abc替换为123,显示出来。 这里若是加-i的话,则会用处理的结果行替换整个文件的内容,如:sed -n '2s#abc#123#gp' test.txt -i ,则会把第2行中的abc全部替换为123后,清空文件,写入第2行内容,见下图:
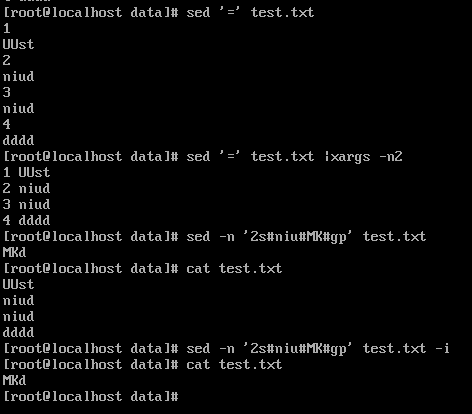 ‘=’表示给每行加行号
‘=’表示给每行加行号
替换具体某一行内容时,不能加p参数,只要-i即可,否则会出错,会多出一行来。这里还需要再研究研究:
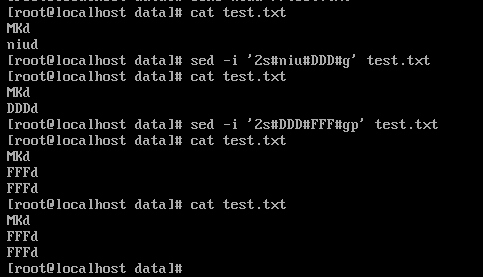
sed -i ‘2s#abc#123#g’ test.txt 这样没有参数p,会正常的将第2行abc替换为123.
sed -i '2s#abc#123#gp' test.txt 这样的有参数p,会在替换后多出一行来,内容和第2行一致.见图:
查找:sed -n '/abc/p' test.txt 将文件内包含abc的行显示.
sed '/abc/d' test.txt 将文件内没有包含abc字符的行,均显示出来(这里如果加-n的话就什么都不显示)。-----一般根据字符查找行用grep,sed这样用起来不方便,也用的少.

4.awk 取列。取行。计算。
格式:awk 参数 取行/取列/查找的字符 文件名
awk ‘找谁{做什么}’ 文件 eg:awk ‘NR==2{print $3}’ test.txt 取出test.txt文件第2行的第3列内容
参数:
-F 指定分隔符(未指定时,默认空格作为分隔符)。 eg:awk -F ”,“ ‘{print $3}’ test.txt 用逗号作为分隔符,显示第3列
-F "[ ,]" 指定多个分隔符。 eg:awk -F "[ ,]" '{print $3,$5}' test.txt 用逗号或者空格作为分隔符,显示第3列和第5列
-F "[ ,]+" 指定多个分隔符。这里的+号表示,以连续出现的空格或逗号作为分隔符。
$n 第n列
$0 表示一整行的内容
NR 表示行号
{print }
取列:
awk ‘{print $3]’ test.txt 显示第3列
awk '{print $2,$6}' test.txt 显示第2列,第6列
awk '{print $2" ,aa"$4}' tets.txt 显示第2列,第4列。大括号内,双引号里的内容会原封不动的输出。
取行:
awk ‘NR==20,NR==30’ test.txt 显示第20行到第30行
awk ‘NR==20’ test.txt 显示第20行
查找:
awk '/123/' test.txt 显示文件内包含123字符的行
awk ‘!/123/’ test.txt 显示文件内不包含123字符的行