Google-Hacking
搜索技巧
Google 基本搜索与挖掘技巧
● 保持简单明了的关键词
● 使用最可能出现在要查找的网页上的字词
● 尽量简明扼要地描述要查找的内容
● 选择独特性的描述字词
● 社会公共信息库查询
● 个人信息:人口统计局
● 企业等实体:YellowPage、企业信用信息网
● 网站、域名、IP:whois 等
Google语法基础
1.查询是不区分大小写(OR在表示布尔含义时一定要大写)
2.*在谷歌搜索的时候只能当做一个单词使用
3.谷歌有32词的搜索限制(当然可以通过*代替某些单词突破这种限制)
4.短语搜索要带上单引号
5.AND对谷歌来说是多余的,谷歌会自动查询你输入的一切
6.谷歌会忽略特别常见的字符,但是前面加上”+”强制搜索(+后面不能有空格)
7.NOT可以使用”-”(减号代替)
8.布尔查询OR/”|”
高级语法
operator:search
注意点:
1.在操作符、冒号、搜索项之间没有空格
2.all运算符(以all开头的运算符)都是有些奇怪的,通常一个查询只能使用一次,而且不能和其他运算符一起使用
allintitle 会告诉谷歌,它后面的每一个单词或者短语都要在标题中出现
allintext 在除了标题、URL、链接以外的任何地方找到某个内容(它后面的每一个单词或者短语都要在内容中出现)
3.intitle:”index of”等价于 intitle:index.of
因为‘.’休止符能够代替任何字符(这个技术也提供了一个无需键入空格和两边引号的短语)
4.intitle:”index of” private 能返回标题中有index of 以及在任何地方有 private的页面(intitle只对其后面第一个搜索项有效)
常见运算符解释
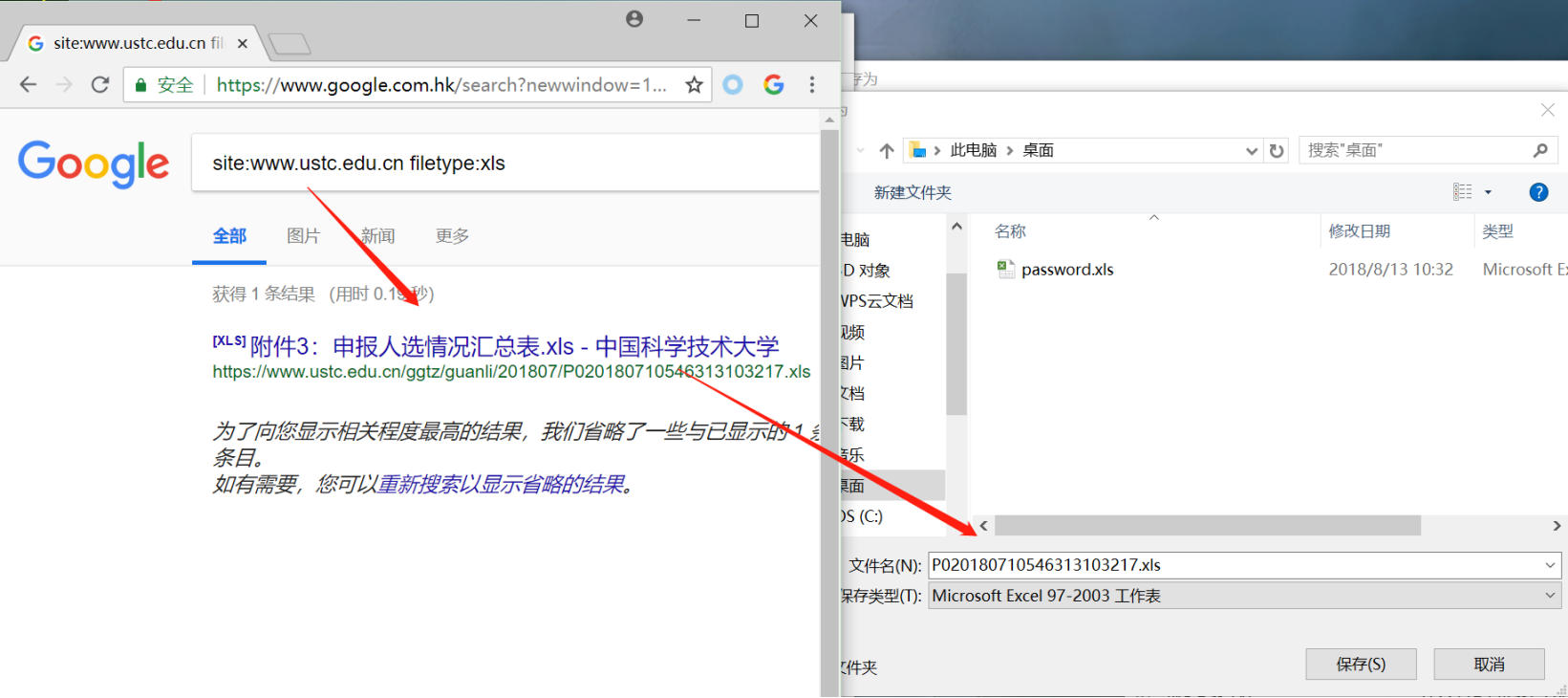
site 把搜索精确到特定的网站
site 允许你搜索仅仅位于一个特定服务器上的或者在一个特定域名里的页面
filetype 搜索特定后缀的文件
搜索以一个特别的文件扩展名结尾的页面,谷歌会以网页快照的形式来将这种格式转换成html页面,但是你直接点击标题就会下载
link 包含指定网页的链接的网页
搜索包含指定网页的链接的网页,link后面跟的是完整的URL可以包含目录名、文件名、参数等,信息量越大查询结果越精确。
/注意/
不要认为 Link能搜索链接中的文本,inanchor才执行的是这个操作,如果输入错误,那么并不会执行link查询而是把[link:短语]当做一个整体直接默认查询
link运算符不能和其他运算符一起使用
inanchor 寻找链接的锚点
inanchor 用于寻找链接的锚点,或者在链接中显示的文本(就是显示在页面上的提供点击的文字)
cache 显示页面的缓存版本
直接跳转到页面的缓存版本
numberange 搜索一个数字
numberange 需要两个参数,一个低位数字,一个高位数字,中间用连字符分割
例如:
为了找到12345 numberange:12344-12346
/注意/
1.这个运算符还有简化版, 12344..12346
2.可以和其他运算符一起使用
daterange 搜索在特定日期范围内发布的页
谷歌每次重新抓取一个网页网页的日期就会刷新
两个参数日期都必须是自公元前4713年1月1日起经过的天数,中间用连字符分割但(不如使用谷歌的高级搜索引擎实现)
info 显示谷歌的总结信息
显示一个网站的总结信息还提供了可能关于该网站的其他搜索链接
/注意/
info不能和其他运算符一起使用
related 显示相关站点
参数是一个URL
/注意/:
1.点击类似网页链接和使用高级搜索引擎能实现相同的功能
2.不能和其他运算符一起使用
define 显示一个术语的定义
常用搜索引擎
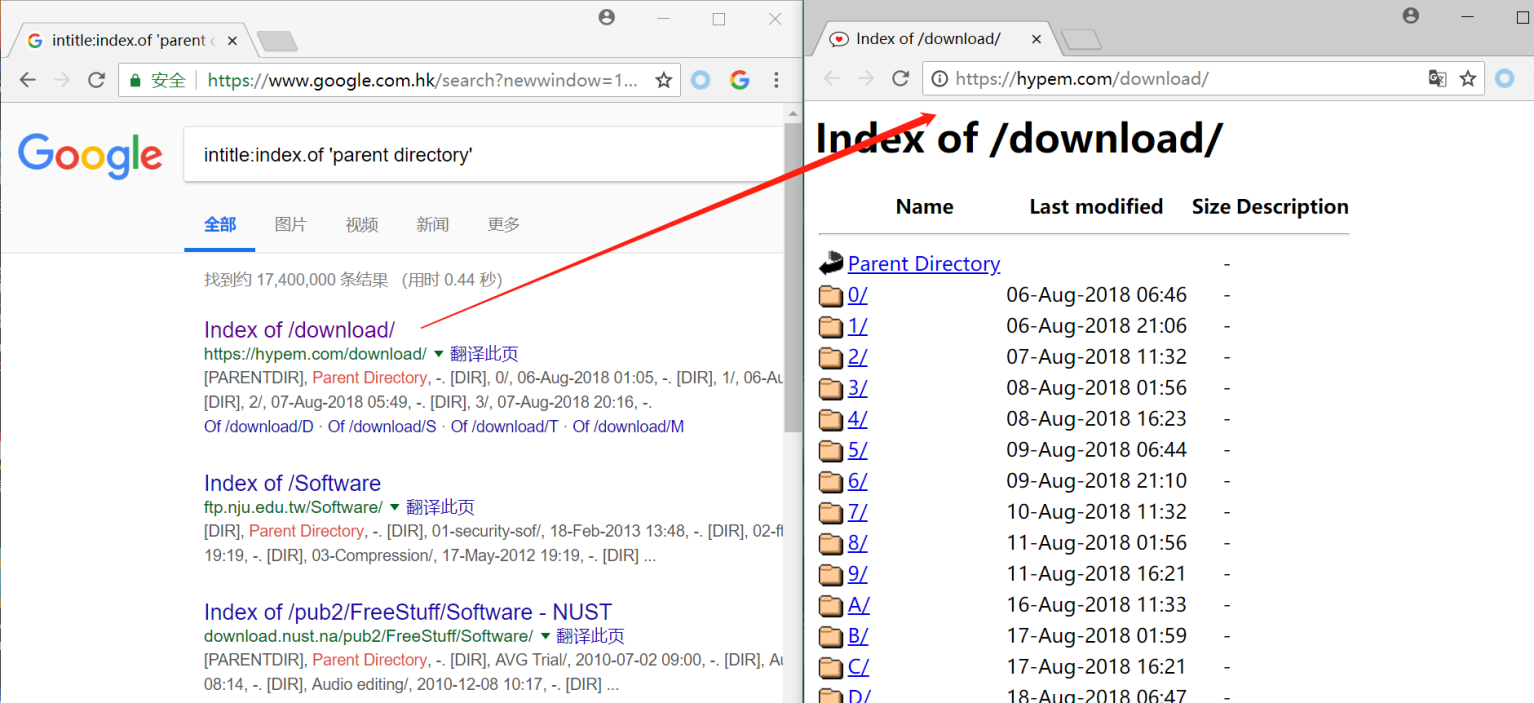
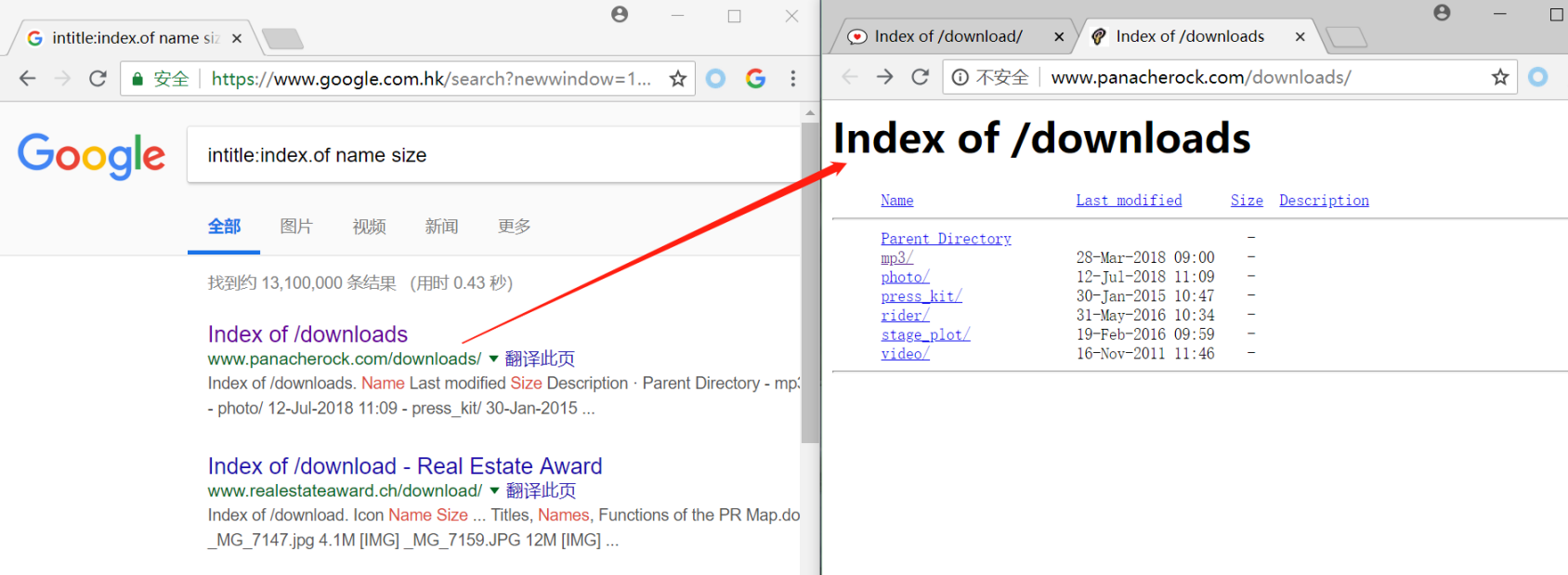
目录列表的查找
目录列表能列出存在于一个web服务器上的文件和目录
查找目录列表
intitle:index.of 'parent directory'
intitle:index.of name size
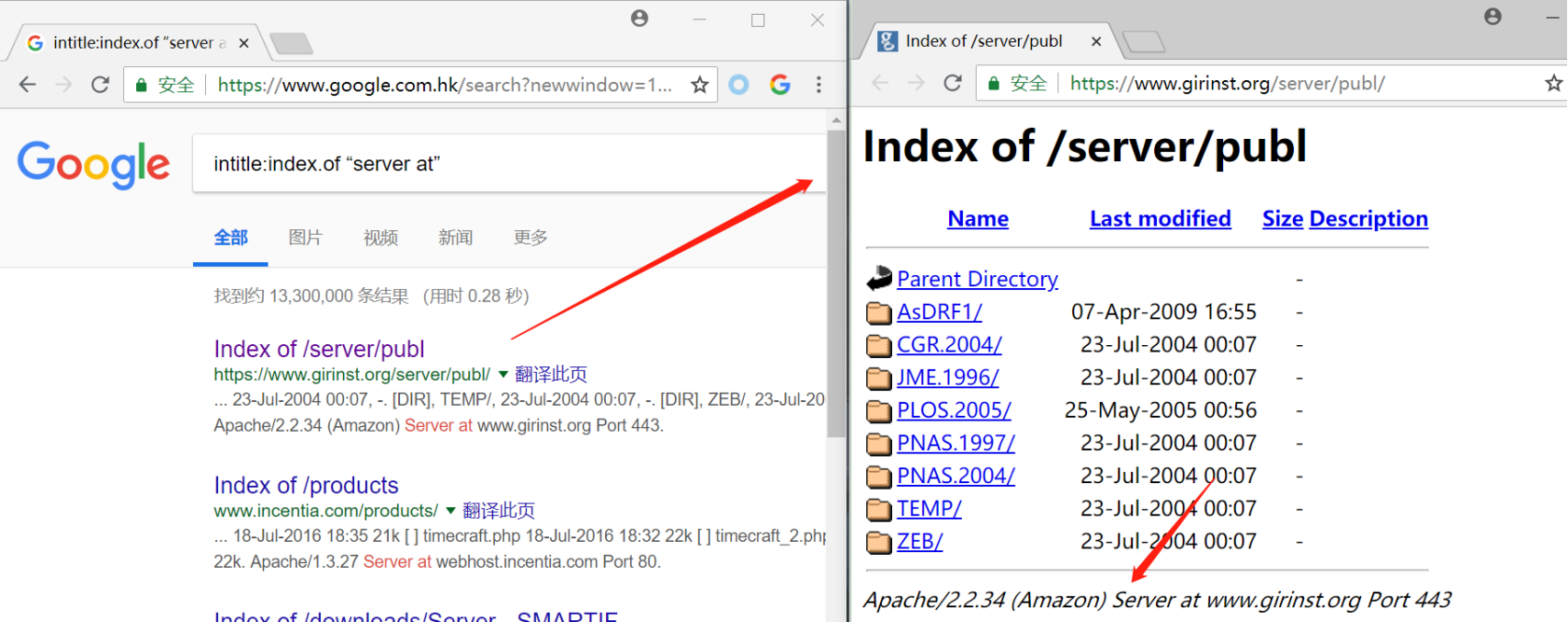
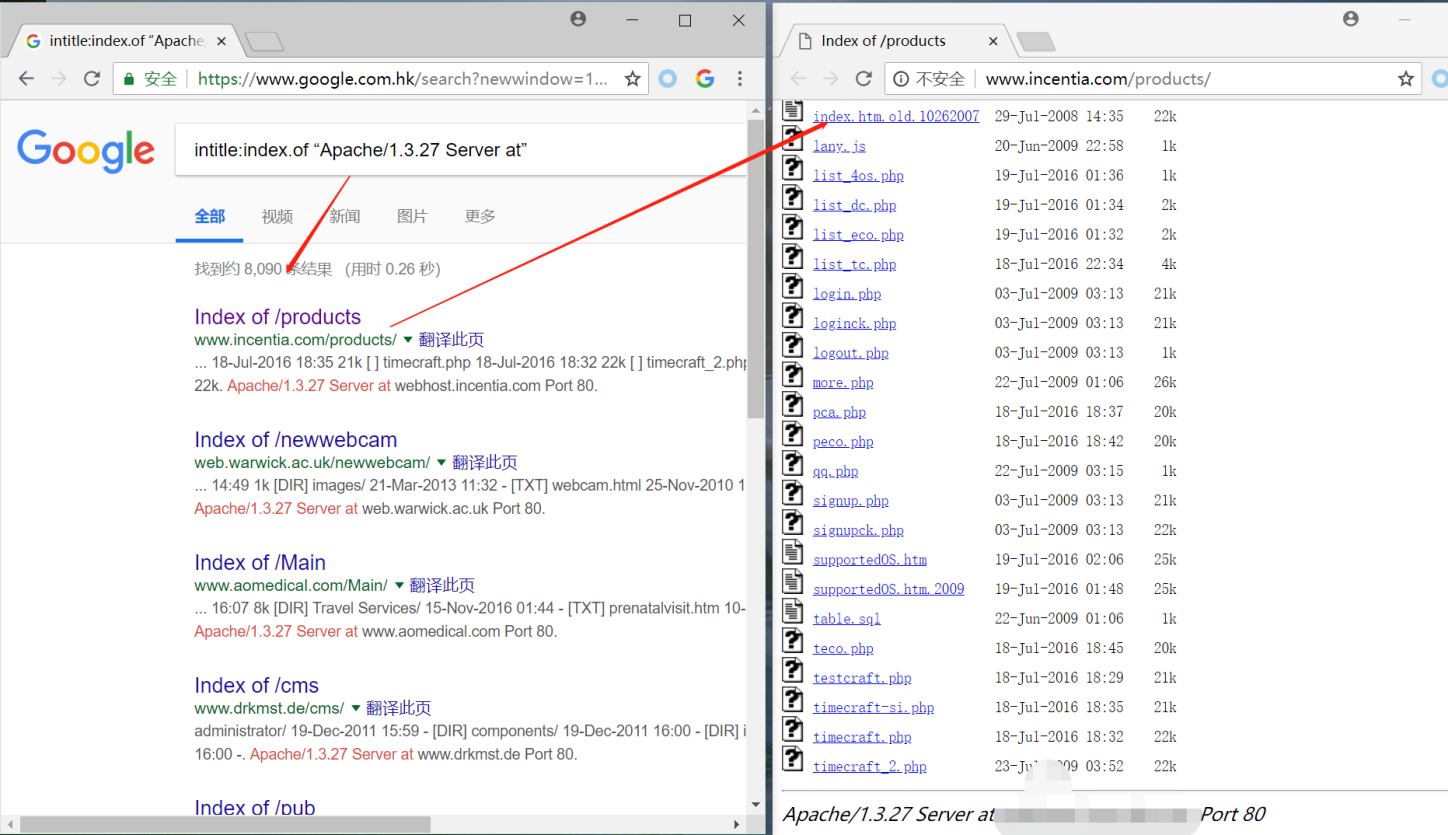
(特定版本的)服务器
能被攻击者用来决定攻击web服务器最佳方法的一小段信息,就是确切的服务器版本
实例:
intitle:index.of “server at”
intitle:index.of “Apache/1.3.27 Server at”
扩展遍历技术
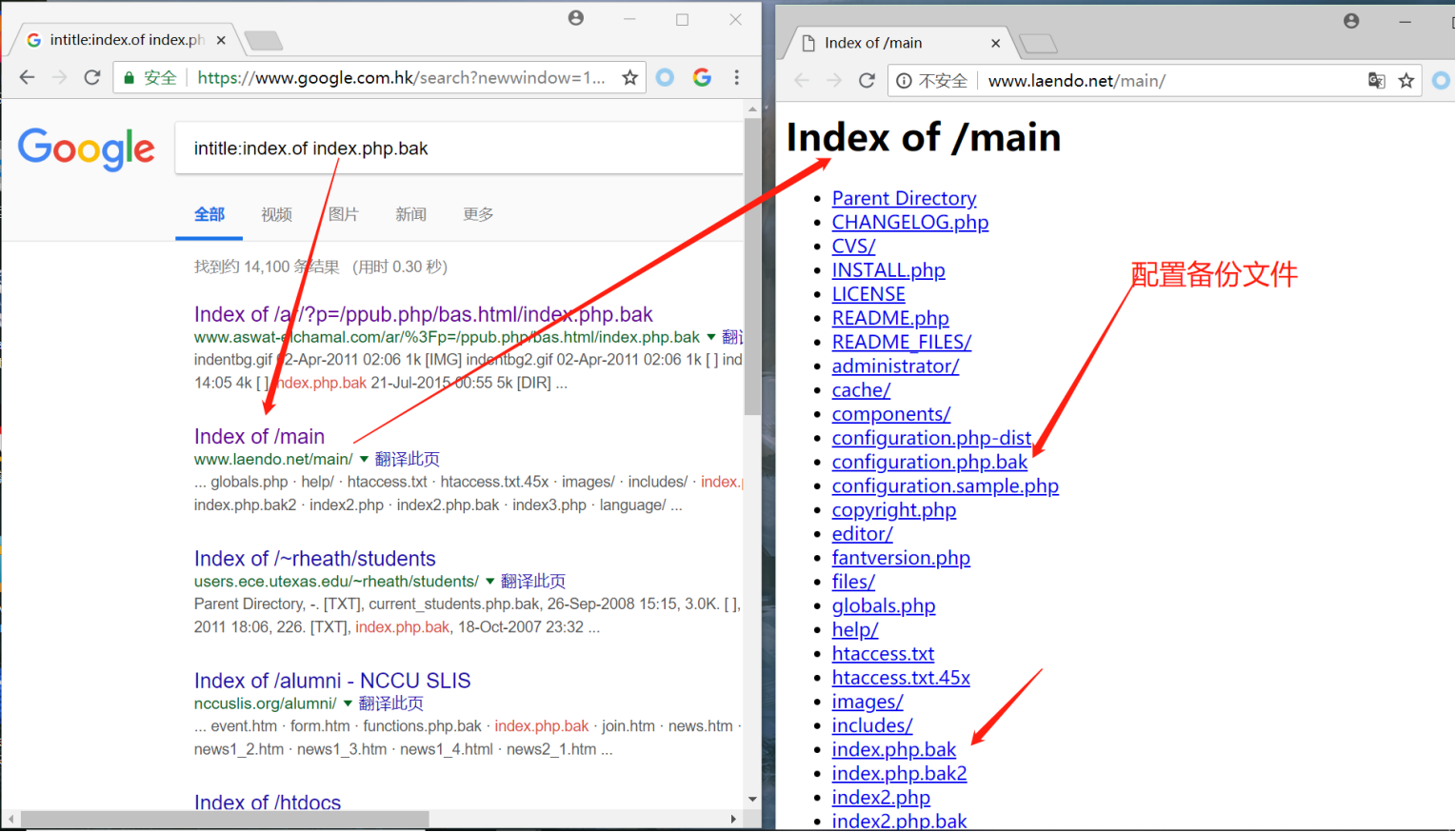
经常会出现web页面的备份文件,他们有泄露源码的倾向。常常在配置错误的时候出现这种问题,把php代码备份到不是以php结尾的文件中,比如bak
实例:
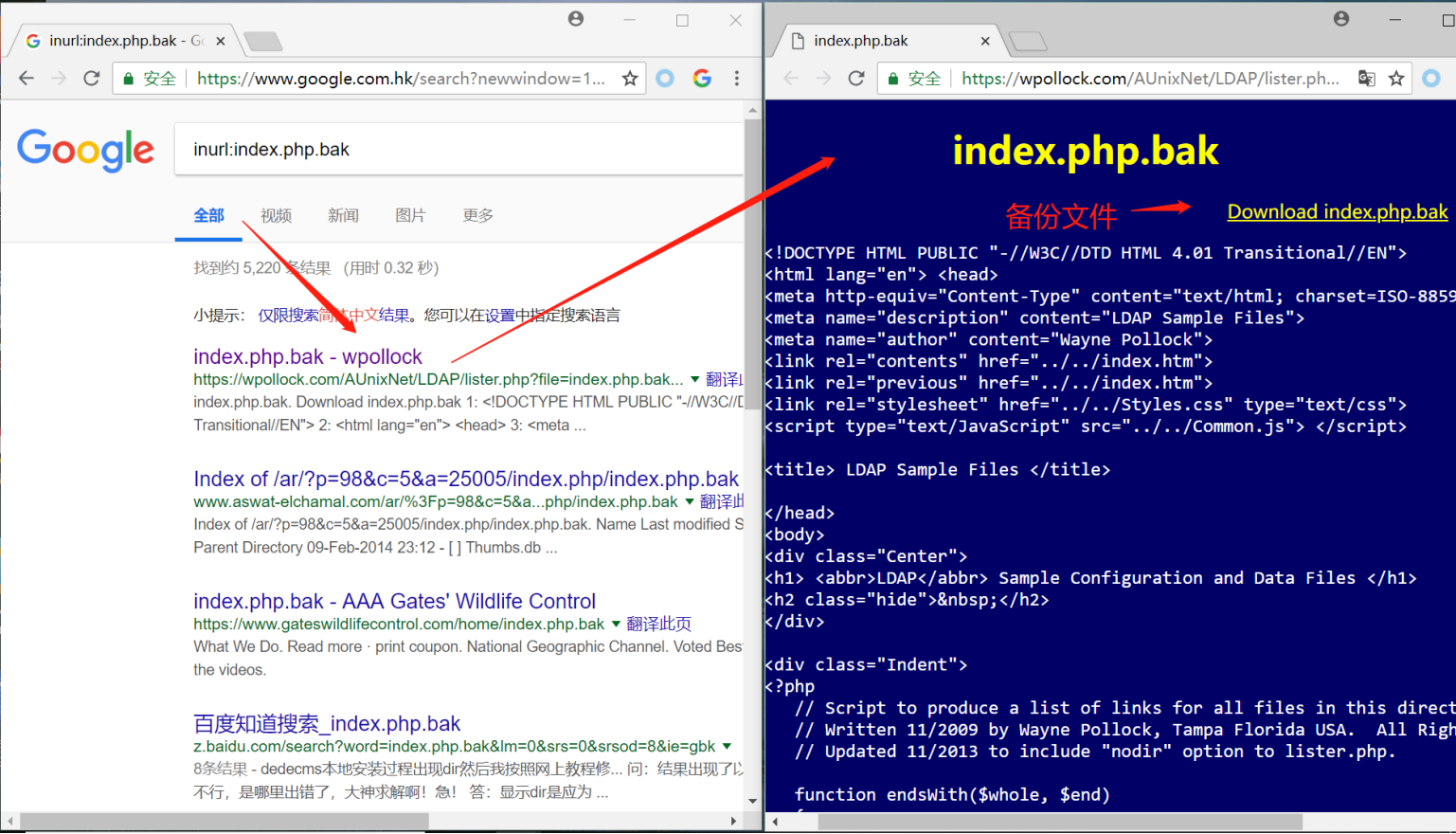
intitle:index.of index.php.bak
inurl:index.php.bak
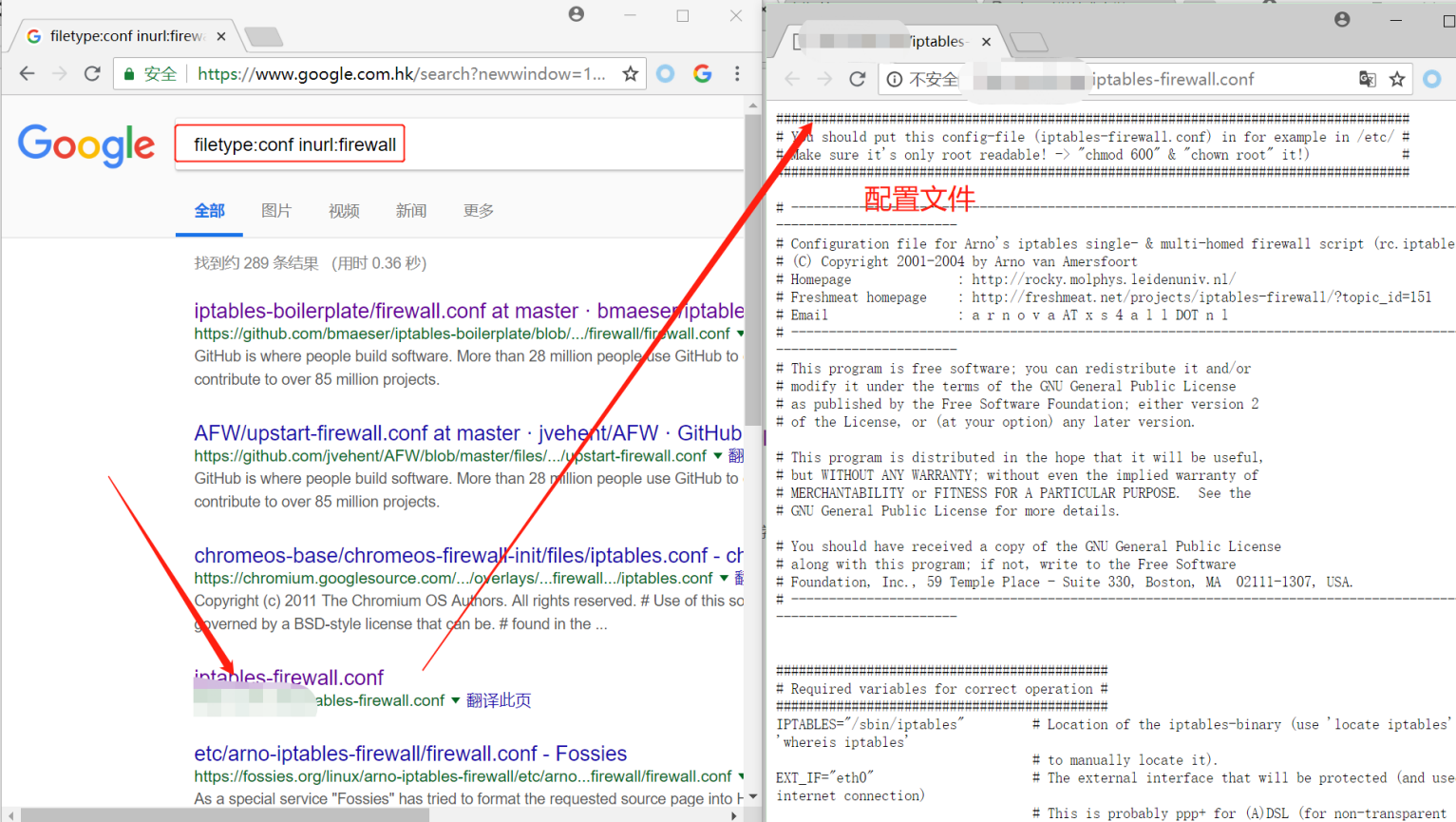
配置文件的查找
配置文件的存在说明服务就在附近
示例:
filetyte:conf inurl:firewall
如果你能知道配置文件的名字也是一个非常好的搜索方式,当然你可以从配置文件中抽取特定的字符串来查询,如果能再配上软件名字的话就效果更好了
注意:
1.除了配置文件名conf的使用,也可以组合其他的通用的命名规则来查找其他等价的命名规则
inurl:conf OR inurl:config OR inurl:cfg
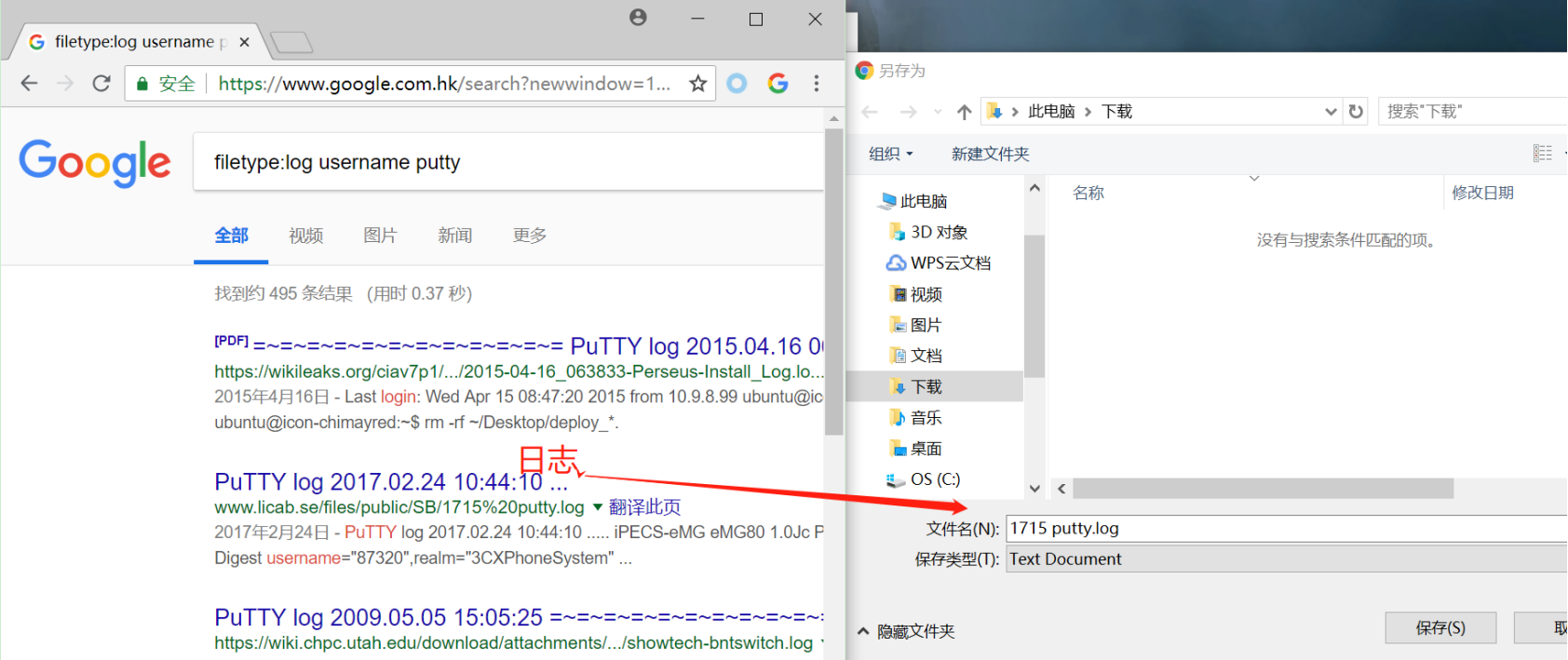
日志文件的查找
日志文件中也记录着日志很多的敏感信息
日志文件也有一个默认的名字可以被我们用作基础的搜索,最常见的扩展名就是log了
实例:
filetype:log inurl:log
ext log log
filetype:log username putty
查找office文档
实例:
filetype:xls inurl:password.xls
filetype:xls username password email
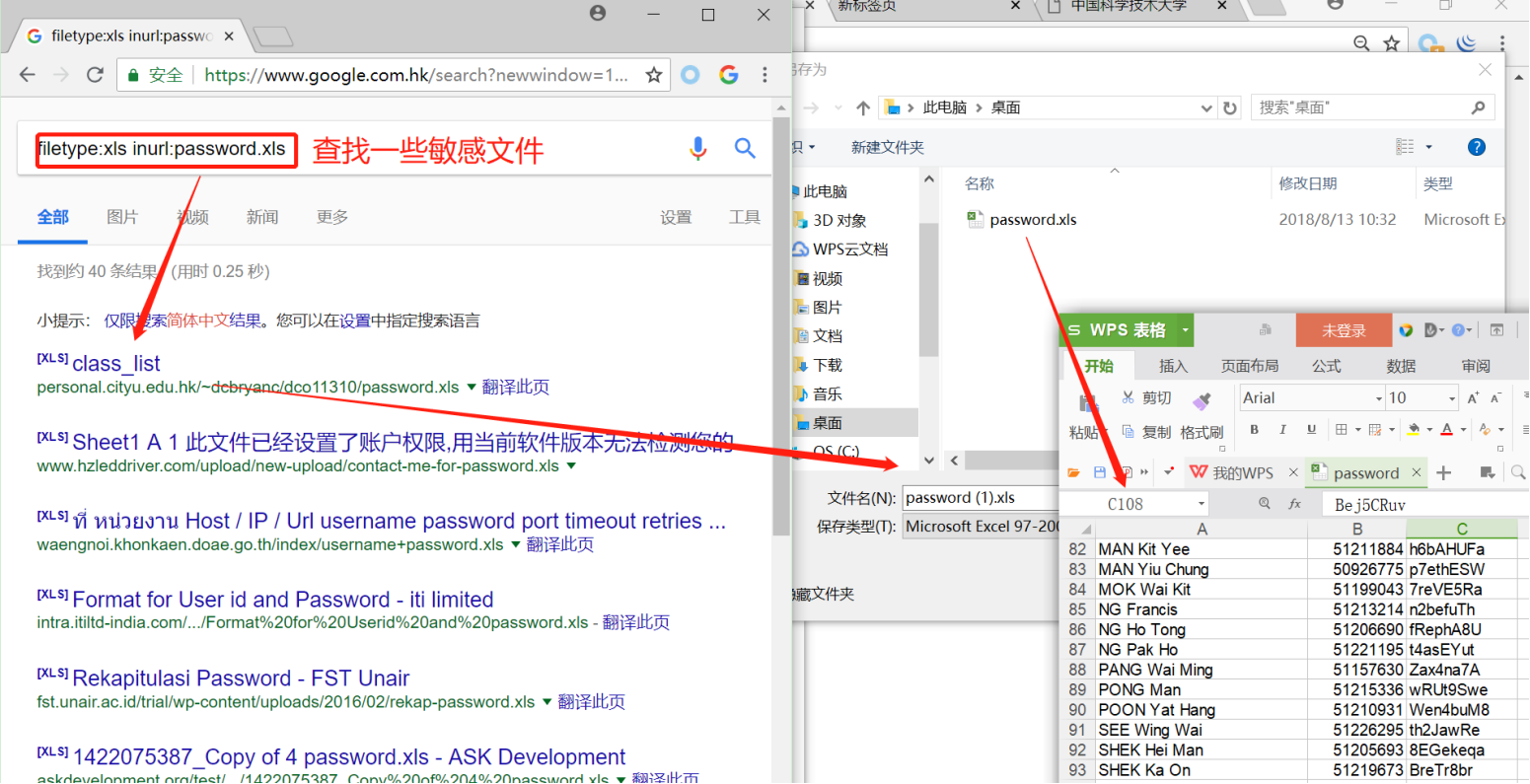
数据库、后台类、登录入口
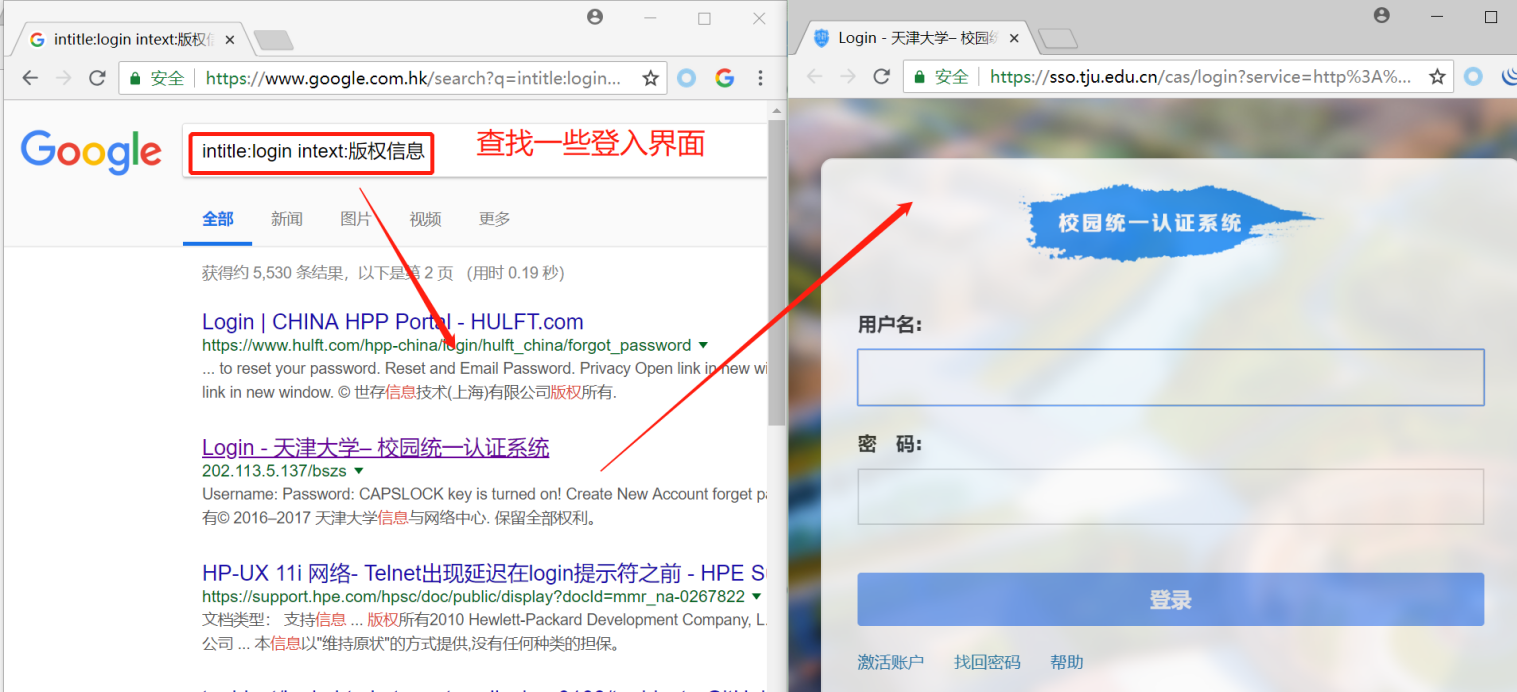
登录入口是第一道防线,很容易泄露软硬件的信息
查找入口一般使用关键字login
大的厂商一般会把版权的注意事项放在页面的底部
实例:
intitle:login intext:版权信息
如何防御Google Hacking
web 服务器的安全防护
一、目录列表和丢失的索引文件
.htaccess 可以来防止目录的内容未授权的访问,但是不当的配置还会让这个文件可见甚至可读
在 apache 的服务器上可以通过 httpd.conf文件中的单词indexs前加一个连字符或者减号来禁止目录列表
二、robots.txt
#`开头的行会被认为是注释,每一个不以#开头的行都会以User-agent 或者是一个disallow 声明开头,表示禁止爬虫爬行的位置,但是也可以允许特定的爬虫访问
三、NOARCHIVE缓存杀手
有时候你希望google住抓取某个页面但是又不希望对页面的副本进行缓存,或者搜索结果中显示缓存链接,这个要求可以通过META实现
<META NAME= "ROBOTS" CONTENT= "NOARCHIVE">
如果你只想阻止谷歌对文件的缓存,可以在HEAD节里使用
<META NAME="GOOGLEBOT" CONTENT="NOINDEX,NOFOLLOW">
四、NOSNIPET 去除摘要
<META NAME="GOOGLEBOT" CONTENT="NOSNIPPET">
另外这个功能还有个副作用,就是谷歌也不能缓存,一举两得。
五、十五条防止信息泄露和服务器入侵的措施
1.检查所有的文档能否被Google搜索到,避免敏感文件能出现在公众的视野中
2.选择一个强大的自动化工具来扫描你网站上是否有信息的泄露
3.不要使用默认的登录入口,以防止登录入口被hacker猜解
4.关闭数据库的远程管理工具
5.删除明显的显示软件版本的信息
6.配置服务器只能下载特定的文件类型(白名单比黑名单要简单有效得多)
7.正确的配置你的服务器,不要抱有侥幸心理,任何的松懈带来的灾难是巨大的
8.不要把源码的备份放在未经授权就能访问的地方,并且及时删除网站上的无用的备份文件
9.不要使用弱密码,防止攻击者轻易攻破后台
10.登录请加上强度相对较高的验证手段,防止攻击者采用爆破的手段
11.关闭服务器不必要的端口
12.请不要使用网站上的任何信息作为密码,否则都属于容易爆破的类型
13.备份的源代码请经过专业的混淆,防止被下载之后轻易读取到内容
14.及时更新服务器的系统,修复潜在的漏洞
15.安装正规的安全防护软件