* -- 匹配所有内容信息
【应用场景一: 找寻数据信息时】
find /oldboy -name "*.txt"
find /oldboy -name "oldboy*"
find /oldboy -name "oldboy*.txt"
【应用场景二: 操作管理数据】
ll /oldboy/oldboy*
rm -rf /oldboy/*
cp -a /oldboy/* /tmp/
rm /oldboy/* --> cd /oldboy rm -rf /*
{} -- 匹配序列内容信息 {01..100} {a..z} {A..Z}
【应用场景一: 生成序列信息】
echo {01..10} --- 生成连续序列
echo {01..10..2} --- 生成等差序列
[root@localhost ~]# echo {a..z}
a b c d e f g h i j k l m n o p q r s t u v w x y z
[root@localhost ~]# echo {a..z..2}
a c e g i k m o q s u w y
[root@localhost ~]# echo {01,03,07,08,09}
01 03 07 08 09
应用场景二: 生成组合序列
echo {01..03}{A..C}
01A 01B 01C 02A 02B 02C 03A 03B 03C
echo A{,B} --> A AB
echo oldboy.txt{,.bak} --> oldboy.txt oldboy.txt.bak
cp /etc/selinux/config{,.bak} --- 快速备份数据方法
echo A{B,} --> AB A
echo oldboy.txt{.bak,} --> oldboy.txt.bak oldboy.txt
cp oldboy.txt{.bak,} --- 快速还原数据方法

正则表达式:
文本匹配模式 处理大量的字符串
注意事项:
a.linux 正则表达式一般以行为单位进行处理
b.alias grep='grep --color=auto',让匹配的内容显示颜色
c.注意字符集。export LC_ALL=C
[root@localhost ~]# export LC_ALL=C
[root@localhost ~]# echo $LC_ALL
C
-【基础正则 BRE】
定位符使用技巧:同时锚定开头和结尾,做精确匹配;单一锚定开头和结尾,做模糊匹配。
定位符 说明
^ 锚定开头 ^a 以a开头 默认锚定一个字符
$ 锚定结尾 a$ 以a结尾 默认锚定一个字符
找出文件/etc/service 以s开头的信息
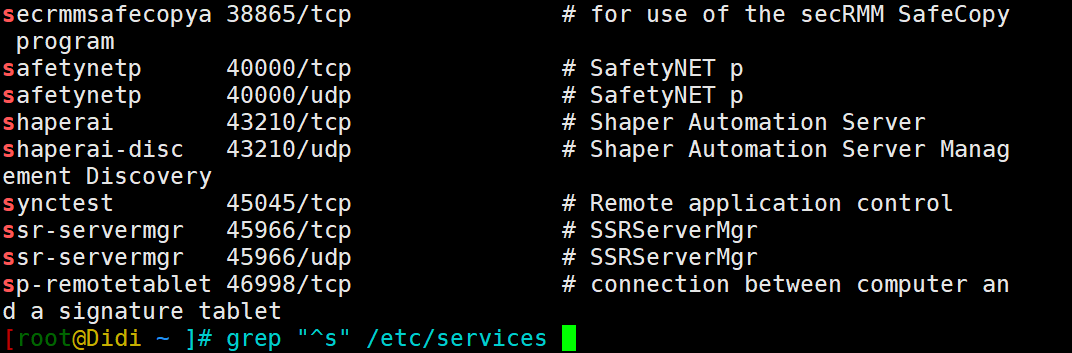
找出/oldboy目录中 文件内容是oldboy开头的文件
老三: grep
grep "^s" /etc/services
[root@localhost oldboy]# grep -r "^oldboy" /oldboy
/oldboy/oldboy.txt:oldboy
/oldboy/oldbaby.txt:oldboy01
/oldboy/oldboy01/oldboy.txt:oldboy
/oldboy/oldboy01/oldbaby.txt:oldboy01
老二: sed
sed -n '/^s/p' /etc/services
老大: awk
awk '/^s/' /etc/services
. --- 匹配任意一个且只有一个字符信息

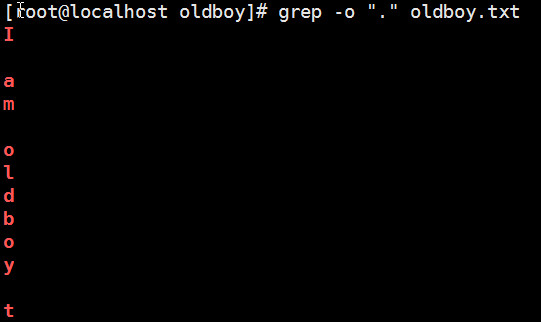
* --- 匹配星号字符前面的一个字符 连续出现0次或者多次的情况

.* --- 匹配所有内容信息
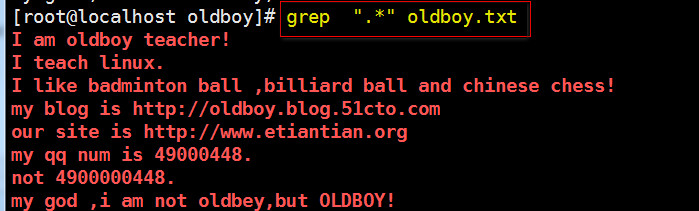

正则符号匹配字符信息时,有贪婪匹配特性
1) 将有特殊意义的符号变得没有意义
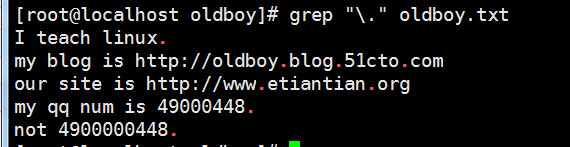
2) 将没有页数意义的字符变得有意义
\n --- 换行字符
\r --- 换行字符
\t --- 制表符

3) 取消别名功能
\rm -rf /oldboy.txt
二、特殊字符
匹配符:匹配字符串,包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为"元字符")。它是一种字符串匹配的模式,可以用来检查一个字符串是否含有某种子串、
将匹配的子串替换或者从某个字符串中取出某个条件的子串
[ ] ---------定义字符类,匹配括号中的一个字符
[abc]: 匹配字符集合内的任意一个字符[a-z,A-Z],[0-9]等
匹配出文件中所有的字母信息(大小写问题)
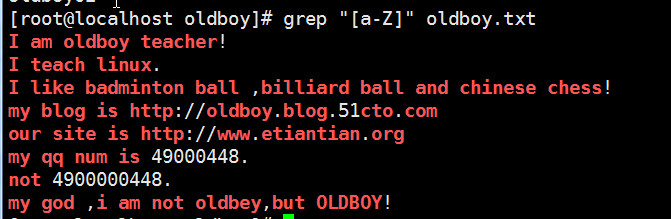
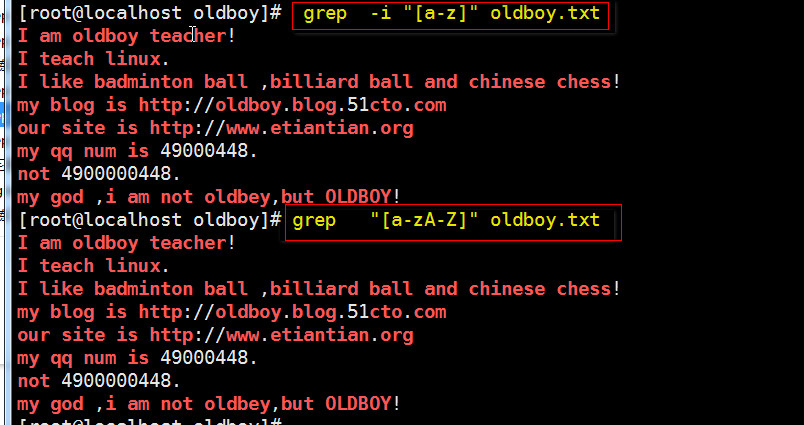
~~~测试文件中以I开头行和以m开头的行都找出来】

[^abc]:匹配不包含^后面的任意一个字符的内容
练习题: 去除文件中所有符号信息
grep "[^0-9a-Z]" oldboy.txt
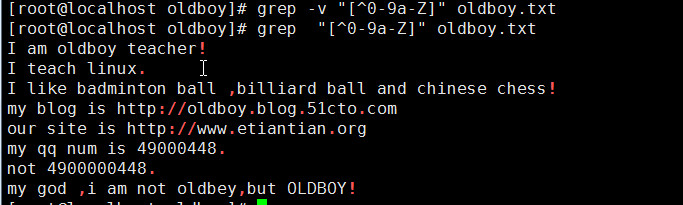
【表示匹配不包含I, ^, o的信息】

[ ^ ] 表示否定括号中出现字符类中的字符,取反。
+ --- 匹配加号字符前面的一个字符 连续出现1次或者多次的情况