数据存储服务器集群的伸缩性对数据的持久性和可用性提出了更高的要求。
缓存的目的是加快数据读取速度并减轻数据存储服务器的负载压力,因此部分缓存的丢失不影响业务的正常处理,因为数据还可以从数据库等存储服务器上获取。
而数据存储服务器必须保证数据的可靠性存储,任何情况下都必须保证数据的可用性和正确性。
6.4.1 关系数据库集群的伸缩性设计
关系数据库集群的伸缩性设计也是要基于关系数据库提供的基本的数据复制功能,才能保证数据的正确性。
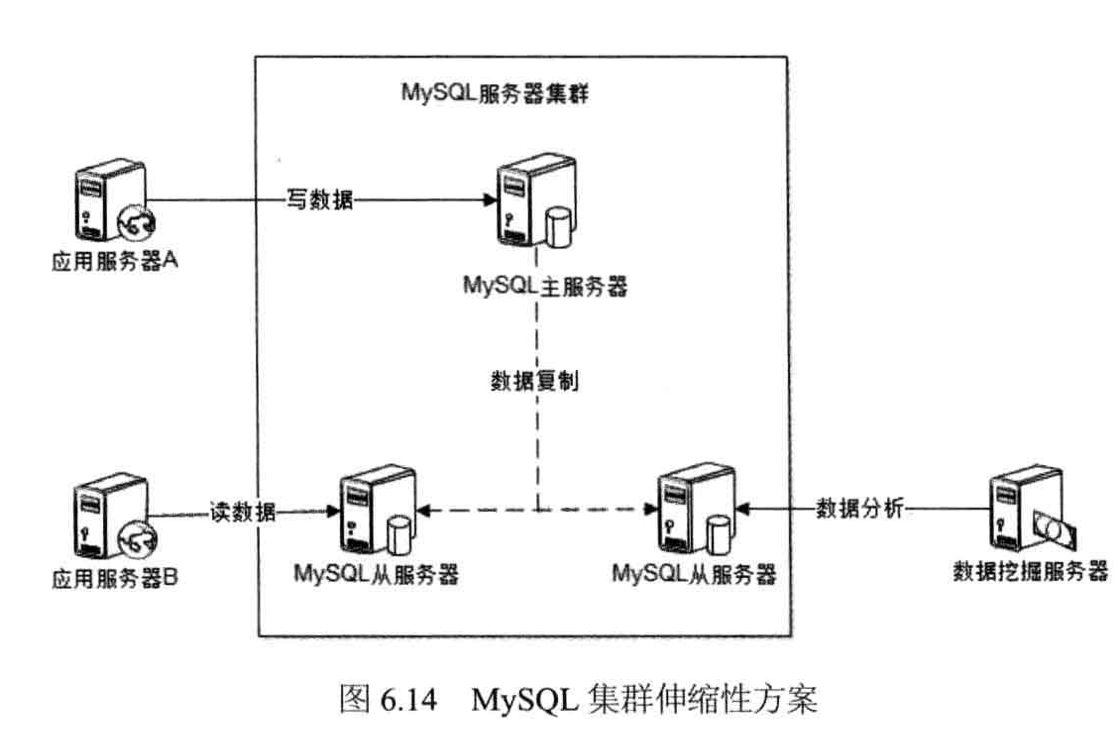
在上面这种架构中,虽然多台服务器部署MySQL实例,但是它们的角色有主从之分,数据写操作都在主服务器上,由主服务器将数据同步到集群中其他从服务器,数据读操作及数据分析等离线操作在从服务器上进行。
数据分库:根据业务分割,不同业务数据表部署在不同的数据库集群上。这种方式制约条件是跨库的表不能进行Join操作。
对于单表数据仍然很大的表,还需要进行分片,将一张表拆分开分别存储在多个数据库中。
目前成熟的支持数据分片的分布式关系数据库产品主要有开源的Amoeba和Cobar。这两个产品有相似的架构设计,以Cobar为例,其部署模型如下图所示:
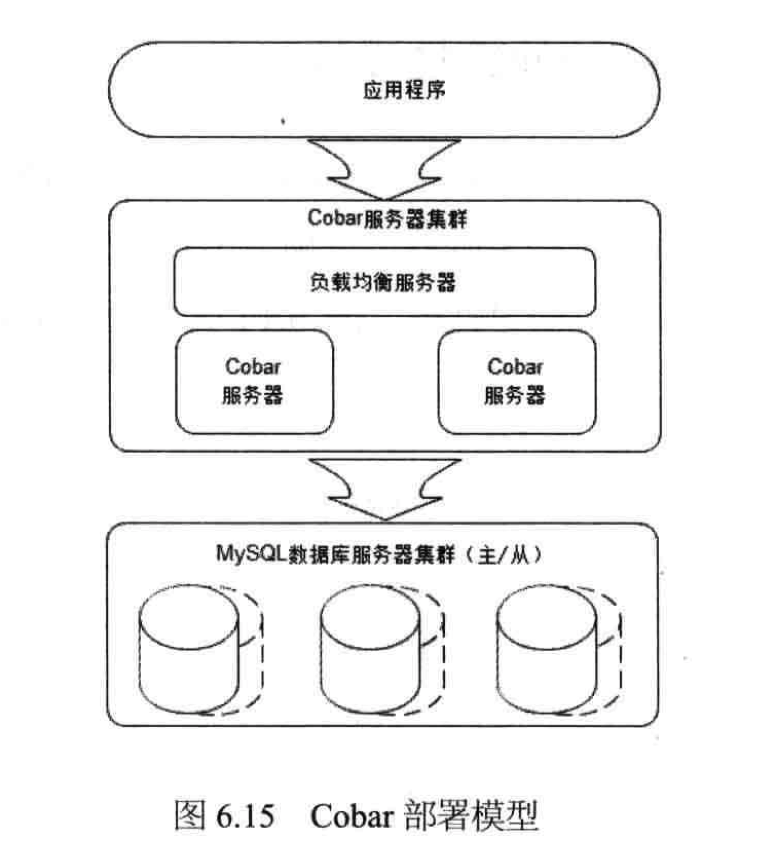
可以看到部署图上,其介于应用服务器和数据库服务器之间(Cobar也支持非独立部署,以lib的方式和应用程序部署在一起)。
应用程序通过JDBC驱动访问Cobar集群,Cobar服务器根据SQL和分库规则分解SQL,分发到MySQL集群不同的数据库实例上执行(每个MySQL实例都部署为主从结构,保证数据高可用)。
Cobar系统组件模型如下图:
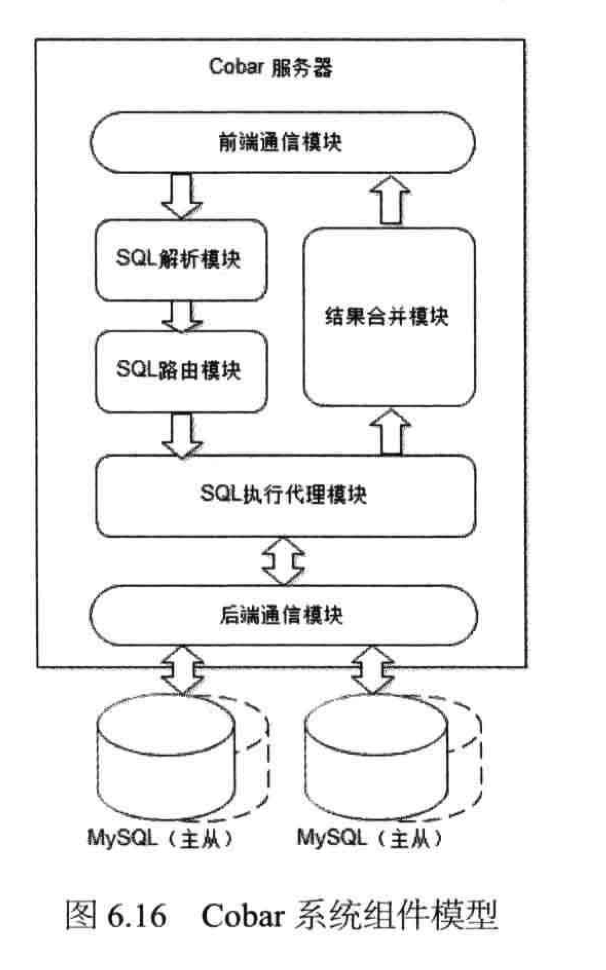
Cobar的执行流程是什么?一条SQL经过Cobar,Cobar怎么处理?
Cobar如何做集群伸缩?
Cobar的伸缩有两种:Cobar服务器集群的伸缩和MySQL服务器集群的伸缩。
Cobar服务器可以看作是无状态的应用服务器,其伸缩可以简单的使用负载均衡的手段实现。
MySQL中存储着数据,要想保证集群扩容后数据一致负载均衡,必须要做数据迁移,将集群中原来机器中的数据迁移到新添加的机器中。如下图所示:
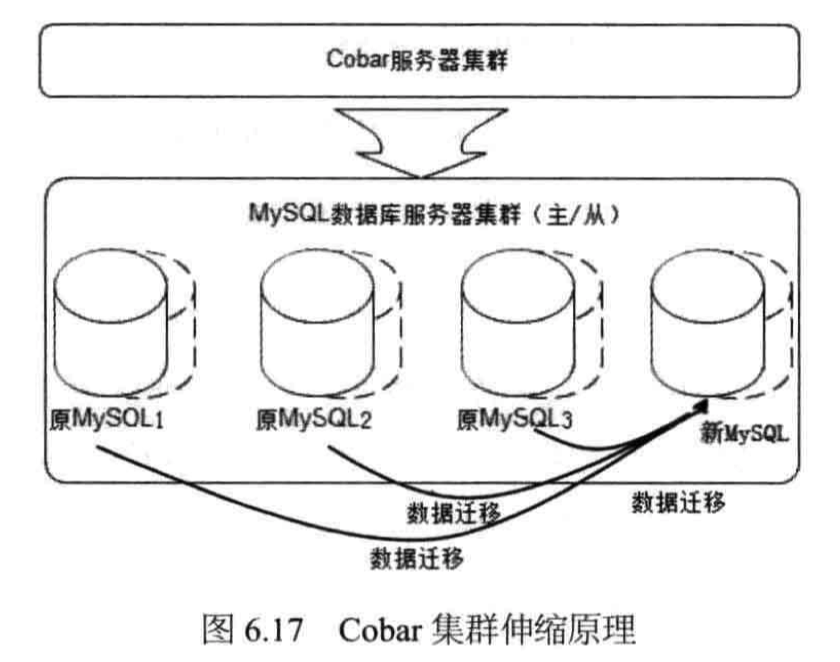
具体迁移哪些数据可以利用一致性hash算法,尽可能使需要迁移的数据量最少。
但是迁移数据需要遍历数据库中每条记录(的索引),重新进行路由计算确定其是否需要迁移,会对数据库访问造成一定压力。
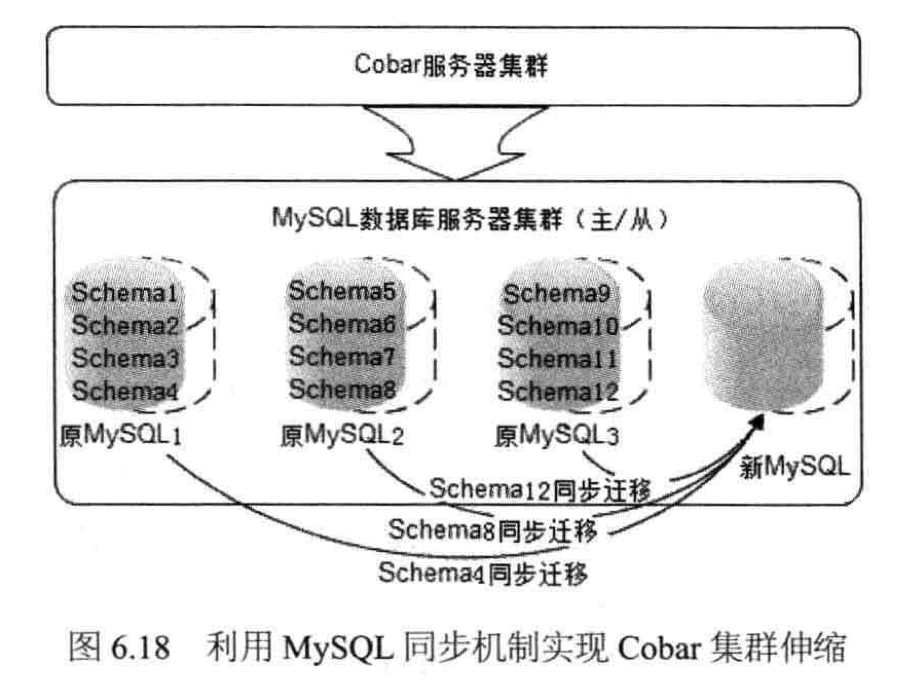
实践中,Cobar利用了MySQL的数据同步功能进行数据迁移。数据迁移不是以数据为单位,而是以Schema为单位。
在Cobar集群初始化时,在每个MySQL实例创建多个Schema(根据业务远景规划未来集群规模,如集群最大规模为1000台数据库服务器,那么总的初始Schema数>=1000)。
集群扩容时,从每个服务器中迁移部分Schema到新的机器中,由于迁移以Schema为单位,迁移过程可以使用MySQL的同步机制,如下图所示: