第一章 Python基础知识
第二章 字符串处理与编码不再发愁
第一章 Python基础知识
1.1 介绍
1.1.1 特点
Python是一种面向对象、解释型计算机程序设计语言。语法简洁清晰,强制用空白符作为语句缩进。
Python具有丰富和强大的库,又被称为胶水语言。能把其他语言(主要C/C++)写的模块很轻松的结合在一起。
1.1.2 应用领域
Web网站:有很多优秀的开源Web框架,比如Django(最流行)、Tornado(轻量级、异步)、Flask(微型)、Web.py(简单)等。
数据采集:有好用的http库,比如urllib2、requests等。还有高级的屏幕爬取及网页采集框架scrapy。并对网页解析也有很多库,比如lxml、xpath、BeautifulSoup等。
大数据分析:常用模块有Numpy、Pandas。并支持写MapReduce、PySpark处理Spark RDD(弹性分布式数据集)。
运维自动化:编写脚本、Web平台,自动化日常工作。
科学计算:在科学计算也应用越来越广泛,常用的模块有Numpy、SciPy。
等等...可见Python是一门通用语言!
1.1.3 为什么选择Python?
运维的目的呢,主要还是学习Python用来实现运维自动化了。大多数人除了shell脚本外有其他语言基础的应该占少数。
我们以Python作为第一门语言是很好的选择。为什么呢?
1) 语法简洁,易于学习。
2) 广泛的标准库,适合快速开发,不就追求极快处理速度。
3) 跨平台,基本所有的所有的操作系统都能运行。
4) 运维领域Python最流行。
1.2
安装Python
操作系统采用CentOS6.5,默认安装了Python2.6.6,那我们升级到Python2.7最新版Python2.7.12
1. 安装Python2.7
# wget https://www.python.org/ftp/python/2.7.12/Python-2.7.12.tgz
# tar zxvf Python-2.7.12.tgz
# cd Python-2.7.12
# ./configure
# make && make install
# mv /usr/bin/python /usr/bin/python2.6.6
# ln -s /usr/local/bin/python2.7 /usr/bin/python
# python -V
Python 2.7.12
注意:软链接指向Python2.7版本后,yum将不能正常工作,因为yum不兼容2.7的,所有需要指定下yum命令里默认Python版本为2.6.6版本
# sed -i '1s/$/2.6.6/' /usr/bin/yum
2. 安装setuptools
# yum install python-devel zlib-devel openssl-devel -y
# wget https://pypi.python.org/packages/32/3c/e853a68b703f347f5ed86585c2dd2828a83252e1216c1201fa6f81270578/setuptools-26.1.1.tar.gz
# tar zxvf setuptools-26.1.1.tar.gz
# cd setuptools-26.1.1
# python setup.py install
......
"Compression requires the (missing) zlib module"
RuntimeError: Compression requires the (missing) zlib module
解决方法,进入刚解压的Python2.7目录重新编译安装:
# cd ../Python-2.7.12
# make && make install
# python setup.py install
3. 安装pip2.7
# wget https://pypi.python.org/packages/e7/a8/7556133689add8d1a54c0b14aeff0acb03c64707ce100ecd53934da1aa13/pip-8.1.2.tar.gz
# tar zxvf pip-8.1.2.tar.gz
# cd pip-8.1.2
# python setup.py install
1.3
解释器
1.3.1 Python解释器几种实现版本
1) CPython
当我们装完Python后,其默认解释就是CPython,也是官方默认解释器。CPython是C语言写的,当执行代码时会将代码转化成字节码(ByteCode)。
2) IPython
基于CPython之上的一个交互式解释器,相当于默认解释器的一个增强版,最显著的功能就是自动补全,挺好用的。
3) PyPy
PyPy本身是由Python编写的,使用了JIT编译器(即时编译器)技术,当执行代码时JIT编译器将代码翻译成机器码。性能相比CPython要好。JAVA也采用了JIT编译器。
4) Jython
Jython是由JAVA编写的一个解释器,可以把JAVA模块加载到Python的模块中使用,也可以把Python代码打包成JAR包,意味着允许用Python写JAVA程序了。当执行代码时会将代码转化成JAVA字节码,然后使用JRE执行。
5) IronPython
在.NET平台上工作的Python语言。
1.3.2 Python代码执行过程
大致流程:源代码编译成字节码(.pyc文件)--> Python虚拟机 --> 执行编译好的字节码 --> Python虚拟机将字节码翻译成对应的机器指令(机器码)
运行Python程序时,先编译成字节码并保存到内存中,当程序运行结束后,Python解释器将内存中字节码对象写到.pyc文件中。
第二次再运行此程序时,先回从硬盘中寻找.pyc文件,如果找到,则直接载入,否则就重复上面的过程。
这样好处是,不重复编译,提供执行效率。
1) 字节码
字节码是一种包含执行程序、由一序列op代码/数据对组成的二进制文件。字节码是一种中间码,比机器码更抽象。
2) 机器码
机器码是一种指令集,让CPU可直接解读的数据。也称为原生码。
1.4 代码风格
1.4.1 代码风格有毛用?
个人觉得有以下几个作用:
1) 团队协作
在企业中,一个团队开发一个项目很正常不过了,刚入职是不是会先让你熟悉本公司的编码规范文档呢,作为纯开发来说,我相信大多数公司都会这么做,其中目的是让团队中的每个成员,写代码时能够统一,避免项目中出现几个编码风格版本,不利用后期维护和交接。
2) 有利于解决问题
草泥马,又出问题了,代码运行不起来了,怎么办?百度、谷歌无解...是时候求助大神了,来看看我的代码吧!大神一看,琢磨了一会,你想多了,不是再想你的问题,而是在梳理你的代码实现的功能和逻辑关系。结果发现,多了括号。擦,我怎么就没看到呢!~
3) 未雨绸缪
功能终于实现了,发布到线上运行也挺正常,过了半年后,突然跑不起来了,赶紧排查问题,代码看着看着自己就懵逼了,这还是自己写的代码嘛,长的这么不像我,是亲生的嘛!
小结:只要人人都献出一点爱,世界将会变成美好的人间。
1.4.2 编写代码怎么能更规范化?
1) 缩进
Python以空白符作为语句缩进,意味着语句没有结尾符,给往往因为少写个fi的人带来了福利,在Python中最好以4个空格作为缩进符。
2) 代码注释
据说优质的代码,注释说明要比代码量多,详细的代码说明不管对自己后期维护还是开源,都是有必要的。就像一个流行的软件,如果没有丰富的使用文档,你认为会有多少耐心的人去花大把的时间研究它呢!
3) 空格使用
在操作符两边,以及逗号后面,加1个空格。但是在括号左右不加空格。
在函数、类、以及某些功能代码块,空出一行,来分隔它们。
4) 命名
模块:自己写的模块,文件名全部小写,长名字单词以下划线分隔。
类:大/小驼峰命名。我一般采用大驼峰命名,也就是每个单词首字母大写。类中私有属性、私有方法,以双下划线作为前缀。
函数:首单词小写,其余首字母大写。
变量:都小写,单词以下划线分隔。
提醒:所有的命名必须能简要说明此代码意义。
5) 代码换行
按照语法规则去换行,比如一个很长的表达式,可以在其中某个小表达式两边进行换行,而不是将小表达式拆分,这样更容易阅读。
1.5 交互式解释器
直接执行Python命令就启动默认的CPython解释器:
# python
Python 2.7.12 (default, Sep 3 2016, 21:51:00)
[GCC 4.4.7 20120313 (Red Hat 4.4.7-17)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> print "Hello World"
Hello World
配置自动补全:
# pip2.7 install readline
# pip2.7 install rlcompleter2
>>> import readline, rlcompleter
>>> readline.parse_and_bind("tab: complete")
1.6 运算操作符
|
运算符
|
描述
|
示例
|
|
+
|
加法
|
1 + 1 = 2
|
|
-
|
减法
|
3 - 1 = 2
|
|
*
|
乘法
|
2 * 1 = 2
|
|
/
|
除法
|
2 / 1 = 2
|
|
%
|
取余/模
|
2 % 1 = 2
|
|
**
|
指数/幂
|
2 ** 1 = 2
|
1.7 赋值操作符
|
操作符
|
描述
|
示例
|
|
=
|
变量赋值
|
a = b + c
|
|
+=
|
加法
|
a += b 等同于 a = a + b
|
|
-=
|
减法
|
a -= b 等同于 a = a - b
|
|
*=
|
乘法
|
a *= b 等同于 a = a * b
|
|
/=
|
除法
|
a /= b 等同于 a = a / b
|
|
%=
|
模
|
a %= b 等同于 a = a % b
|
|
**=
|
指数/幂
|
a **= b 等同于 a = a ** b
|
赋值操作符,操作符左边运算右边,然后将结果赋值给操作符左边。
博客地址:http://lizhenliang.blog.51cto.com and https://yq.aliyun.com/u/lizhenliang
QQ群:323779636(Shell/Python运维开发群)
QQ群:323779636(Shell/Python运维开发群)
1.8 变量
1.8.1 变量赋值
>>> xxoo = 2
>>> print xxoo
>>> 2
说明:等号左边是变量名,等号右边是值
# 多重赋值
>>> xx, oo = 1, 2
>>> print xx
1
>>> print oo
2
>>> xx = oo = 2
>>> print xx
2
>>> print oo
2
1. 8.2 变量引用
上面打印时就是在引用变量了,可见Python引用变量不用加$什么特殊字符,不像Shell、PHP那样,还要加$。
的确,直接用变量名即是引用,下面说一种常用的字符串格式输出时引用变量的方法。
>>> xxoo = 2
>>> print "xxoo: %d" % xxoo
xxoo: 2
>>> xxoo = "xo"
>>> print "xxoo: %s" % xxoo
xxoo: xo
>>> x = "abc"
>>> o = 123
>>> print "str: %s, int: %d" %(x, o)
str: abc, int: 123
说明:双引号里面%操作符算是占位符吧,d代表数字,s代表字符串。双引号外面%加上后面的变量名对应里面的第一个%。
下面同时引用了两个变量,外面%()里变量名位置对应双引号里面的%位置。
1.8.3 局部变量
>>> xxoo = 2
>>> print xxoo
2
1.8.4 全局变量
>>> global xxoo # 声明为全局变量
>>> print xxoo
2
说明:从上面并不能看出什么区别,后续在函数章节中会讲解局部变量和全局变量的区别和使用。
1.9 转义字符(列出一些常用的)
|
符号
|
描述
|
|
\
|
字符串太长,换一行接着输入
|
|
\' \"
|
单引号和双引号
|
|
\r
|
光标
|
|
\t
|
横向制表符(tab键)
|
|
\v
|
纵向制表符
|
|
\n
|
换行符,打印到下一行
|
示例:
>>> print "Hello \
... World"
Hello World
>>> print "Hello \"World!"
Hello "World!
>>> print "Hello \rWorld!"
World!
>>> print "Hello\tWorld!"
Hello World!
>>> print "Hello \vWorld!"
Hello
World!
>>> print "Hello \nWorld!"
Hello
World!
如果不想让转义字符生效,可以用r指定显示原始字符串:
>>> print r"Hello \nWorld!"
Hello \nWorld!
>>> print "Hello \nWorld!"
Hello
World!
1.10 获取用户输入
1.10.1 raw_input()
>>> name = raw_input("My name is: ")
My name is: xiaoming
>>> print name
xiaoming
1.10.2 input()
>>> name = input("My name is: ")
My name is: xiaoming
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<string>", line 1, in <module>
NameError: name 'xiaoming' is not defined
>>> name = input("My name is: ")
My name is: "xiaoming"
>>> print name
xiaoming
>>> name = input("My name is: ")
My name is: 1 + 2
>>>
>>> print name
3
1.10.3 raw_input()与input()函数区别
可以看到两个函数用同样的方式输入,结果input()报错!
原因是因为raw_input()把任何输入的都转成字符串存储。
而input()接受输入的是一个表达式,否则就报错。
1.11 运行第一个程序
# vi test.py
#!/usr/bin/env python # 说明用什么可执行程序运行它,env会自动寻找python解释器的绝对路径
print "Hello World!"
# python test.py
Hello World!
easy!打印Hello world已经没什么难度了,那改进下刚学接受用户输入。
# vi test.py
#!/usr/bin/env python
name = raw_input("My name is: ")
print name
# python test.py
My name is: xiaoming
xiaoming
1.12 注释
单行注释:井号("#")开头
多行注释:三单引号或三双引号
#!/usr/bin/env python
# -*- coding: utf-8 -*- # 设置解释器默认编码,下一章会讲到
# 单行注释
'''
多行注释
多行注释
'''
"""
多行注释
多行注释
第二章 字符串处理与编码不再发愁
2.1 字符串
2.1.1 字符串转换
>>> a = 123
>>> b = 1.23
>>> type(a)
<type 'int'>
>>> type(b)
<type 'float'>
>>> type(str(a))
<type 'str'>
>>> type(str(b))
<type 'str'>
说明:先定义个整数和浮点数,再查看类型,用str()函数将对象转成字符串。
这里的用到了type()函数,用于查看对象类型。这个type()在以后学习中很用的,刚开始学习时候,往往因为对象类型不对,导致程序运行报错,这时可以用它来排查问题。
2.1.2 字符串连接
# 加号字符将同类型字符连接到一起
>>> hw = "Hello" + "World!"
>>> print hw
HelloWorld!
# 两个相邻的字符串自动连接一起
>>> hw = "Hello""World!"
>>> print hw
HelloWorld!
# 如果字符串内包括单引号或双引号,要用\转义,否则报错,上一章也讲过。
>>> hw = "Hello \"World!\""
>>> print hw
Hello "World!"
# 不同字符串类型拼接
>>> a = "abc"
>>> b = 1
>>> print a + b
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: cannot concatenate 'str' and 'int' objects
说明:不同字符串类型不允许连接,想要连接可以下面这么做。
方法1:
>>> c = "%s%d" %(a,b)
>>> print c
abc1
方法2:
>>> c = a + str(b)
>>> print c
abc1
2.1.3 格式化输出
|
操作符号
|
说明
|
|
%s
|
字符串(str())
|
|
%r
|
字符串(repr())
|
|
%d
|
整数
|
|
%f
|
浮点数,可指定小数点后的精度
|
|
?
|
|
1) 字符串格式输出三种方法
>>> xxoo = "string"
>>> print "%s" %xxoo
string
>>> print "%r" %xxoo
'string'
>>> print `xxoo`
'string'
说明:%s采用str()函数显示,%r采用repr()函数显示。repr()和反撇号把字符串转为Python表达式。
2) 保留小数点数
>>> '%.1f' %(float(100)/1024)
'0.1'
2.1.4 字符串处理
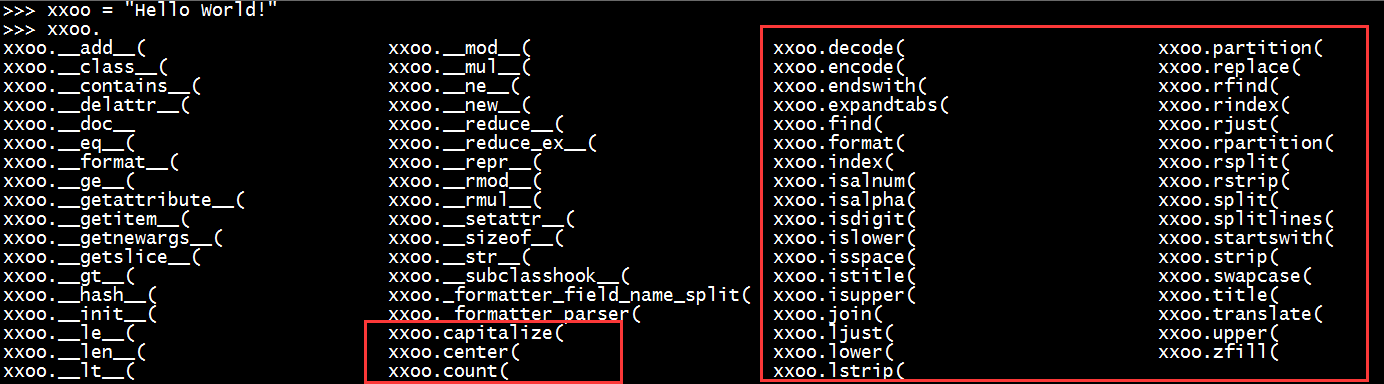
上图是字符串处理的方法,红色框框中大概有一半经常用的,我们就拿一部分常用的来举例说明。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
xxoo = "Hello world!"
print "字符串长度: %s" % len(xxoo)
print "首字母大写: %s" % xxoo.capitalize()
print "字符l出现次数: %s" % xxoo.count('l')
print "感叹号是否结尾: %s" % xxoo.endswith('!')
print "w字符是否是开头: %s" % xxoo.startswith('w')
print "w字符索引位置: %s" % xxoo.find('w') # xxoo.index('W')
print "格式化字符串: Hello{0} world!".format(',')
print "是否都是小写: %s" % xxoo.islower()
print "是否都是大写: %s" % xxoo.isupper()
print "所有字母转为小写: %s" % xxoo.lower()
print "所有字母转为大写: %s" % xxoo.upper()
print "感叹号替换为句号: %s" % xxoo.replace('!','.')
print "以空格分隔切分成列表: %s" % xxoo.split(' ')
print "转换为一个列表: %s" % xxoo.splitlines()
print "去除两边空格: %s" % xxoo.strip()
print "大小写互换: %s" % xxoo.swapcase()
print "只要Hello字符串: %s" % xxoo[0:5]
print "去掉倒数第一个字符: %s" % xxoo[0:-1]
# python test.py
字符串长度: 12
首字母大写: Hello world!
字符l出现次数: 3
感叹号是否结尾: True
w字符是否是开头: False
w字符索引位置: 6
格式化字符串: Hello, world!
是否都是小写: False
是否都是大写: False
所有字母转为小写: hello world!
所有字母转为大写: HELLO WORLD!
感叹号替换为句号: Hello world.
以空格分隔切分成列表: ['Hello', 'world!']
转换为一个列表: ['Hello world!']
去除两边空格: Hello world!
大小写互换: hELLO WORLD!
只要Hello字符串: Hello
去掉倒数第一个字符: Hello world
博客地址:http://lizhenliang.blog.51cto.com and https://yq.aliyun.com/u/lizhenliang
QQ群:323779636(Shell/Python运维开发群)
QQ群:323779636(Shell/Python运维开发群)
2.2 编码
2.2.1 常见字符编码类型
ASCII:美国信息交换标准码,是目前计算机中最广泛使用的字符集编码。每个ASCII码以1个字节存储,例如数字字符0的ASCII码是0110000,十进制表示为48。
Unicode:为解决世界上上百种语言带来混合、冲突,各国有各国的标准,显示很容易出现乱码。Unicode就出现了,它把所有语言的字符都统一到一套Unicode编码中,并定义每个语言字符的标准,所以Unicode又称统一码,万国码。大部分编程语言都支持Unicode,Python内部编码也支持Unicode。
GB2312:中国国家标准总局发布处理汉字的标准编码。
GBK:GB2312的扩展,向下兼容GB2312。
UTF-8:针对Unicode的可变长度字符编码,又称万国码。支持中文简体繁体及其它语言(如英文,日文,韩文)。
2.2.
3 decode()
decode()函数作用是将其他编码(比如ACSII、Byte String)的字符串解码成Unicode。
2.2.
4 encode()
encode()函数作用是将Unicode编码成终端软件能是识别的编码,就能正常显示了,比如UTF-8、GBK。
2.2.
5 Python编码处理
#!/usr/bin/env python
c = "中文"
print c
# python test.py
File "test.py", line 2
SyntaxError: Non-ASCII character '\xe4' in file test.py on line 3, but no encoding declared; see http://www.python.org/peps/pep-0263.html for details
说明:在程序里面直接打印中文,会报语法错误,这是因为Python默认编码是ASCII,无法处理其他编码。
如果想打印中文,需要声明编码为utf-8,上面也有写过:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
c = "中文"
print c
print type(c)
# python test.py
中文
<type 'str'>
可以正常输出中文了,类型是字符串,这个字符串是经过Python unicode编码后字节组成的。
虽然可以正常输入中文,并不意味的就万事大吉了,如果终端编码不是utf-8或其他软件也不确定编码还会出现乱码情况。所以还是要明白Python处理编码逻辑关系,才能更好的应对编码问题。
切换到交互式解释器:
>>> c = "中文"
>>> c.encode('utf-8')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeDecodeError: 'ascii' codec can't decode byte 0xe4 in position 0: ordinal not in range(128)
如果直接转成utf-8是不允许的,报错Unicode解码错误,大概意思是说ascii码不能解码字节字符串。
上面讲到encode()函数作用是将Unicode码解码,而现在的c变量并非是Unicode码,而是字节字符串,算是Unicode的一种吧?。
故此,不能使用encode(),而是先使用decode()先解码陈Unicode再用encode()编码成utf-8。
>>> c.decode('utf-8')
u'\u4e2d\u6587' # 4e2d对应unicode值是"中",6587对应unicdoe值是"文"
>>> type(c.decode('utf-8'))
<type 'unicode'>
>>> print c.decode('utf-8') ?
中文
>>> print c.decode('utf-8').encode('utf-8')
中文
如果是Unicode字符串可直接通过encode()函数转码其他编码。
>>> c = u'中文'
>>> c.encode('utf-8')
'\xe4\xb8\xad\xe6\x96\x87'
>>> print c.encode('utf-8')
中文
看下字节字符串和unicode字符串区别:
>>> c = '中文'
>>> u = u'中文'
>>> c
'\xe4\xb8\xad\xe6\x96\x87'
>>> u
u'\u4e2d\u6587'
>>> len(c)
6
>>> len(u)
2
字节字符串长度要比unicode长的多,而unicode长度就是字符长度。
总结下:Python处理编码流程大致是这样的,ascii --> decode() --> unicode --> encode() --> 终端是能识别的编码,unicode算是一个中间码,有着承上启下的作用。
第三章 Python丰富的数据类型
什么是数据类型?
前两章里面包含的字符串、布尔类型、整数、浮点数都是数据类型。数据类型在一个编程语言中必不可少,也是使用最多的。
而且数据类型的数据都是存放在内存中的,我们一般操作都是在对内存里对象操作。
什么是数组?
数组也是一种数据类型,为了方便处理数据,把一些同类数据放到一起就是数组,是一组数据的集合,数组内的数据称为元素,每个元素都有一个下标(索引),从0开始。
在Python中,内建数据结构有列表(list)、元组(tuple)、字典(dict)、集合(set)。
3.1 列表[List]
3.1.1 定义列表
>>> lst = ['a','b','c',1,2,3]
用中括号括起来,元素以逗号分隔,字符串用单引号引起来,整数不用。
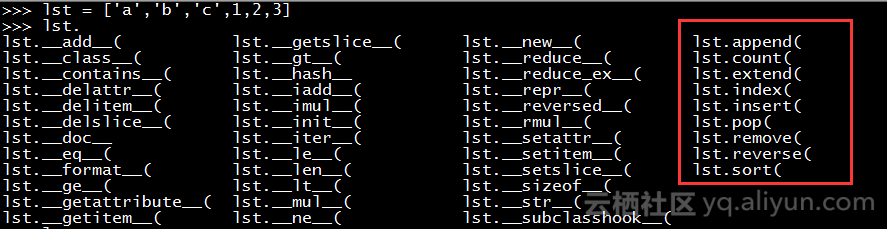
3.1.2 基本操作
# 追加一个元素
>>> lst.append(4)
>>> lst
['a', 'b', 'c', 1, 2, 3, 4]
# 统计列表中a字符出现的次数
>>> lst.count('a')
1
# 将一个列表作为元素添加到lst列表中
>>> a = [5,6]
>>> lst.extend(a)
>>> lst
['a', 'b', 'c', 1, 2, 3, 4, 5, 6]
# 查找元素3的索引位置
>>> lst.index(1)
3
# 在第3个索引位置插入一个元素
>>> lst.insert(3, 0)
>>> lst
['a', 'b', 'c', 0, 1, 2, 3, 4, 5, 6]
# 删除最后一个元素和第3个下标元素
>>> lst.pop()
6
>>> lst.pop(3)
0
>>> lst
['a', 'b', 'c', 1, 2, 3, 4, 5]
# 删除元素是5,如果没有会返回错误
>>> lst.remove("5")
>>> lst
['a', 'b', 'c', 1, 2, 3, 4]
# 倒序排列元素
>>> lst.reverse()
>>> lst
[4, 3, 2, 1, 'c', 'b', 'a']
# 正向排序元素
>>> lst.sort()
>>> lst
[1, 2, 3, 4, 'a', 'b', 'c']
# 列表连接
>>> a = [1,2,3]
>>> b = ['a','b','c']
>>> a + b
[1, 2, 3, 'a', 'b', 'c']
3.1.3 学习新函数对列表排序
# reversed()函数倒序排列
使用此函数会创建一个迭代器,遍历打印才能输出:
>>> lst = ['a', 'b', 'c', 1, 2, 3, 4, 5]
>>> type(reversed(lst))
<type 'listreverseiterator'>
>>> lst2 = []
>>> for i in reversed(lst):
... lst2.append(i)
...
>>> lst2
[5, 4, 3, 2, 1, 'c', 'b', 'a']
# sorted()函数正向排列
>>> lst2 = []
>>> for i in sorted(lst):
... lst2.append(i)
...
>>> lst2
[1, 2, 3, 4, 5, 'a', 'b', 'c']
这里在讲解一个序列生成器range()函数,生成的是一个列表:
>>> type(range(5))
<type 'list'>
>>> for i in range(1,5):
... print i
...
1
2
3
4
当然也可以用上面的排序函数来排序这个生成的序列了:
>>> for i in reversed(range(1,10,3)):
... print i
...
7
4
1
range()函数用法:range(start,end,step)
说明:是不是和列表内置方法结果一样!区别是内置函数不改动原有序列。
3.1.4 切片
>>> lst
[1, 2, 3, 4, 'a', 'b', 'c']
# 返回第一个元素
>>> lst[0]
1
# 返回倒数第一个元素
>>> lst[-1]
'c'
# 取出倒数第一个元素
>>> lst[0:-1]
[1, 2, 3, 4, 'a', 'b']
# 返回第一个至第四个元素
>>> lst[0:4]
[1, 2, 3, 4]
3.1.5 清空列表
方法1:
>>> lst = [1, 2, 3, 4, 'a', 'b', 'c']
>>> lst = []
>>> lst
[]
方法2:
>>> lst = [1, 2, 3, 4, 'a', 'b', 'c']
>>> del lst[:]
>>> lst
[]
# 删除列表
>>> lst = [1, 2, 3, 4, 'a', 'b', 'c']
>>> del lst
>>> lst
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'lst' is not defined
3.1.6 del语句
del语句也可以删除一个下标范围的元素
>>> lst = [1, 2, 3, 4, 'a', 'b', 'c']
>>> del lst[0:4]
>>> lst
['a', 'b', 'c']
3.1.7 列表推导式
利用其它列表推导出新的列表。
# 通过迭代对象方法
方法1:
>>> lst = []
>>> for i in range(5):
... lst.append(i)
...
>>> lst
[0, 1, 2, 3, 4]
方法2:
>>> lst = []
>>> lst = [i for i in range(5)]
>>> lst
[0, 1, 2, 3, 4]
说明:方法1和方法2,实现方式是一样的,只是方法2用简洁的写法。for循环在下一章会讲。
# 通过已有的列表生成新列表
>>> lst
[0, 1, 2, 3, 4]
>>> lst2 = [i for i in lst if i > 2]
>>> lst2
[3, 4]
3.1.8 遍历列表
如果既要遍历索引又要遍历元素,可以这样写。
方法1:
>>> lst = ['a','b','c',1,2,3]
>>> for i in range(len(lst)):
... print i,lst[i]
...
0 a
1 b
2 c
3 1
4 2
5 3
方法2:
>>> for index, value in enumerate(lst):
... print index,value
...
0 a
1 b
2 c
3 1
4 2
5 3
又学了一个新函数enumrate(),可遍历列表、字符串的下标和元素。
3.2 元组(Tuple)
元组与列表类型,不同之处在于元素的元素不可修改。
2.1 定义元组
t = ('a','b','c',1,2,3)
用小括号括起来,元素以逗号分隔,字符串用单引号引起来,整数不用。
2.2 基本操作
count()和index()方法和切片使用方法与列表使用一样,这里不再讲解。
3.3 集合(set)
集合是一个无序不重复元素的序列,主要功能用于删除重复元素和关系测试。
集合对象还支持联合(union),交集(intersection),差集(difference)和对称差集(sysmmetric difference)数学运算。
需要注意的是,集合对象不支持索引,因此不可以被切片。
3.3.1 定义集合
>>> s = set()
>>> s
set([])
使用set()函数创建集合。
3.3.2 基本操作
# 添加元素
>>> s.add('a')
>>> s
set(['a'])
>>> s.add('b')
>>> s
set(['a', 'b'])
>>> s.add('c')
>>> s
set(['a', 'c', 'b'])
>>> s.add('c')
>>> s
set(['a', 'c', 'b'])
说明:可以看到,添加的元素是无序的,并且不重复的。
# update方法事把传入的元素拆分为个体传入到集合中。与直接set('1234')效果一样。
>>> s.update('1234')
>>> s
set(['a', 'c', 'b', '1', '3', '2', '4'])
# 删除元素
>>> s.remove('4')
>>> s
set(['a', 'c', 'b', '1', '3', '2'])
# 删除元素,没有也不会报错,而remove会报错
>>> s.discard('4')
>>> s
set(['a', 'c', 'b', '1', '3', '2'])
# 删除第一个元素
>>> s.pop()
'a'
>>> s
set(['c', 'b', '1', '3', '2'])
# 清空元素
>>> s.clear()
>>> s
set([])
# 列表转集合,同时去重
>>> lst = ['a','b','c',1,2,3,1,2,3]
>>> s = set(lst)
>>> s
set(['a', 1, 'c', 'b', 2, 3])
3.3.3 关系测试
|
符号
|
描述
|
|
-
|
差集
|
|
&
|
交集
|
|
|
|
合集、并集
|
|
!=
|
不等于
|
|
==
|
等于
|
|
in
|
是成员为真
|
|
not in
|
不是成员为真
|
示例:
# 返回差集
>>> a - b
set(['1', '3', '2'])
>>> b - a
set(['9', '8', '7'])
# 返回交集
>>> a & b
set(['5', '4', '6'])
# 返回合集
>>> a | b
set(['1', '3', '2', '5', '4', '7', '6', '9', '8'])
# 不等于
>>> a != b
True
# 等于
>>> a == b
False
# 存在为真
>>> '1' in a
True
# 不存在为真
>>> '7' not in a
True
博客地址:http://lizhenliang.blog.51cto.com and https://yq.aliyun.com/u/lizhenliang
QQ群:323779636(Shell/Python运维开发群)
QQ群:323779636(Shell/Python运维开发群)
3.4 字典{Dict}
序列是以连续的整数位索引,与字典不同的是,字典以关键字为索引,关键字可以是任意不可变对象(不可修改),通常是字符串或数值。
字典是一个无序键:值(Key:Value)集合,在一字典中键必须是互不相同的,
3.4.1 定义字典
>>> d = {'a':1, 'b':2, 'c':3}
用大括号括起来,一个键对应一个值,冒号分隔,多个键值逗号分隔。
3.4.2 基本操作
# 返回所有键值
>>> d.items()
[('a', 1), ('c', 3), ('b', 2)]
# 返回所有键
>>> d.keys()
['a', 'c', 'b']
# 查看所有值
>>> d.values()
[1, 3, 2]
# 添加键值
>>> d['e'] = 4
>>> d
{'a': 1, 'c': 3, 'b': 2, 'e': 4}
# 获取单个键的值,如果这个键不存在就会抛出KeyError错误
>>> d['a']
>>> 1
# 获取单个键的值,如果有这个键就返回对应的值,否则返回自定义的值no
>>> d.get('a','no')
1
>>> d.get('f','no')
no
# 删除第一个键值
>>> d.popitem()
('a', 1)
>>> d
{'c': 3, 'b': 2, 'e': 4}
# 删除指定键
>>> d.pop('b')
2
>>> d
{'c': 3, 'e': 4}
# 添加其他字典键值到本字典
>>> d
{'c': 3, 'e': 4}
>>> d2 = {'a':1}
>>> d.update(d2)
>>> d
{'a': 1, 'c': 3, 'e': 4}
# 拷贝为一个新字典
>>> d
{'a': 1, 'c': 3, 'e': 4}
>>> dd = d.copy()
>>> dd
{'a': 1, 'c': 3, 'e': 4}
>>> d
{'a': 1, 'c': 3, 'e': 4}
# 判断键是否在字典
>>> d.has_key('a')
True
>>> d.has_key('b')
False
3.4.3 可迭代对象
字典提供了几个获取键值的迭代器,方便我们在写程序时处理,就是下面以iter开头的方法。
d.iteritems()
# 获取所有键值,很常用
d.iterkeys() # 获取所有键
d.itervalues() # 获取所有值
# 遍历iteritems()迭代器
>>> for i in d.iteritems():
... print i
...
('a', 1)
('c', 3)
('b', 2)
说明:以元组的形式打印出了键值
如果我们只想得到键或者值呢,就可以通过元组下标来分别获取键值:
>>> for i in d.iteritems():
... print "%s:%s" %(i[0],i[1])
...
a:1
c:3
b:2
有比上面更好的方法实现:
>>> for k, v in d.iteritems():
... print "%s: %s" %(k, v)
...
a: 1
c: 3
b: 2
这样就可以很方面处理键值了!
# 遍历其他两个迭代器也是同样的方法
>>> for i in d.iterkeys():
... print i
...
a
c
b
>>> for i in d.itervalues():
... print i
...
1
3
2
说明:上面用到了for循环来遍历迭代器,for循环的用法在下一章会详细讲解。
3.4.4 一个键多个值
一个键对应一个值,有些情况无法满足需求,字典允许一个键多个值,也就是嵌入其他数组,包括字典本身。
# 嵌入列表
>>> d = {'a':[1,2,3], 'b':2, 'c':3}
>>> d['a']
[1, 2, 3]
>>> d['a'][0] # 获取值
1
>>> d['a'].append(4) # 追加元素
>>> d
{'a': [1, 2, 3, 4], 'c': 3, 'b': 2}
# 嵌入元组
>>> d = {'a':(1,2,3), 'b':2, 'c':3}
>>> d['a'][1]
2
# 嵌入字典
>>> d = {'a':{'d':4,'e':5}, 'b':2, 'c':3}
>>> d['a']
{'e': 5, 'd': 4}
>>> d['a']['d'] # 获取值
4
>>> d['a']['e'] = 6 # 修改值
>>> d
{'a': {'e': 6, 'd': 4}, 'c': 3, 'b': 2}
3.5 额外的数据类型
colloctions()函数在内置数据类型基础上,又增加了几个额外的功能,替代内建的字典、列表、集合、元组及其他数据类型。
3.5.1 namedtuple
namedtuple函数功能是使用名字来访问元组元素。
语法:namedtuple("名称", [名字列表])
>>> from collections import namedtuple
>>> nt = namedtuple('point', ['a', 'b', 'c'])
>>> p = nt(1,2,3)
>>> p.a
1
>>> p.b
2
>>> p.c
3
namedtuple函数规定了tuple元素的个数,并定义的名字个数与其对应。
3.5.2 deque
当list数据量大时,插入和删除元素会很慢,deque的作用就是为了快速实现插入和删除元素的双向列表。
>>> from collections import deque
>>> q = deque(['a', 'b', 'c'])
>>> q.append('d')
>>> q
deque(['a', 'b', 'c', 'd'])
>>> q.appendleft(0)
>>> q
deque([0, 'a', 'b', 'c', 'd'])
>>> q.pop()
'd'
>>> q.popleft()
0
实现了插入和删除头部和尾部元素。比较适合做队列。
3.5.3 Counter
顾名思义,计数器,用来计数。
例如,统计字符出现的个数:
>>> from collections import Counter
>>> c = Counter()
>>> for i in "Hello world!":
... c[i] += 1
...
>>> c
Counter({'l': 3, 'o': 2, '!': 1, ' ': 1, 'e': 1, 'd': 1, 'H': 1, 'r': 1, 'w': 1})
结果是以字典的形式存储,实际Counter是dict的一个子类。
3.5.4 OrderedDict
内置dict是无序的,OrderedDict函数功能就是生成有序的字典。
例如,根据前后插入顺序排列:
>>> d = {'a':1, 'b':2, 'c':3}
>>> d # 默认dict是无序的
{'a': 1, 'c': 3, 'b': 2}
>>> from collections import OrderedDict
>>> od = OrderedDict()
>>> od['a'] = 1
>>> od['b'] = 2
>>> od['c'] = 3
>>> od
OrderedDict([('a', 1), ('b', 2), ('c', 3)])
# 转为字典
>>> import json
>>> json.dumps(od)
'{"a": 1, "b": 2, "c": 3}'
OrderedDict输出的结果是列表,元组为元素,如果想返回字典格式,可以通过json模块进行转化。
3.6 数据类型转换
3.6.1 常见数据类型转换
# 转整数
>>> i = '1'
>>> type(i)
<type 'str'>
>>> type(int(i))
<type 'int'>
# 转浮点数
>>> f = 1
>>> type(f)
<type 'int'>
>>> type(float(f))
<type 'float'>
# 转字符串
>>> i = 1
>>> type(i)
<type 'int'>
>>> type(int(1))
<type 'int'>
# 字符串转列表
方式1:
>>> s = 'abc'
>>> lst = list(s)
>>> lst
['a', 'b', 'c']
方式2:
>>> s = 'abc 123'
>>> s.split()
['abc', '123']
# 列表转字符串
>>> s = ""
>>> s = ''.join(lst)
>>> s
'abc'
# 元组转列表
>>> lst
['a', 'b', 'c']
>>> t = tuple(lst)
>>> t
('a', 'b', 'c')
# 列表转元组
>>> lst = list(t)
>>> lst
['a', 'b', 'c']
# 字典格式字符串转字典
方法1:
>>> s = '{"a": 1, "b": 2, "c": 3}'
>>> type(s)
<type 'str'>
>>> d = eval(s)
>>> d
{'a': 1, 'c': 3, 'b': 2}
>>> type(d)
<type 'dict'>
方法2:
>>> import json
>>> s = '{"a": 1, "b": 2, "c": 3}'
>>> json.loads(s)
{u'a': 1, u'c': 3, u'b': 2}
>>> d = json.loads(s)
>>> d
{u'a': 1, u'c': 3, u'b': 2}
>>> type(d)
<type 'dict'>
3.6.2 学习两个新内建函数
1) join()
join()函数是字符串操作函数,用于字符串连接。
# 字符串时,每个字符作为单个体
>>> s = "ttt"
>>> ".".join(s)
't.t.t'
# 以逗号连接元组元素,生成字符串,与上面的列表用法一样。
>>> t = ('a', 'b', 'c')
>>> s = ",".join(t)
>>> s
'a,b,c'
# 字典
>>> d = {'a':1, 'b':2, 'c':3}
>>> ",".join(d)
'a,c,b'
2) eval()
eval()函数将字符串当成Python表达式来处理。
>>> s = "abc"
>>> eval('s')
'abc'
>>> a = 1
>>> eval('a + 1')
2
>>> eval('1 + 1')
2
第四章 Python运算符和流程控制
在第一章的时候讲解了运算操作符和赋值操作符,这章来学习下其他常用操作符。
4.1 基本运算符
4.1.1 比较操作符
|
操作符
|
描述
|
示例
|
|
==
|
相等
|
>>> 1 == 1 True
|
|
!=
|
不相等
|
>>> 1 != 1 False
|
|
>
|
大于
|
>>> 2 > 1 True
|
|
<
|
小于
|
>>> 2 < 1 False
|
|
>=
|
大于等于
|
>>> 1 >= 1 True
|
|
<=
|
小于等于
|
>>> 1 <= 1 True
|
4.1.2 逻辑运算符
逻辑运算符常用于表达式判断。
|
操作符
|
描述
|
|
and
|
与
|
|
or
|
或
|
|
not
|
非
|
示例:
>>> a = "a"
>>> b = "b"
>>> a and b
'b'
>>> a or b
'a'
>>> a = ""
>>> b = "b"
>>> a and b
''
>>> a or b
'b'
and操作符判断表达式,如果a和b都为真,返回b的值,否则返回a的值。
or操作符也是判断表达式,如果a和b都为真,返回a的值,否则返回b的值。
类似于shell里的&&和||:[ 'a' == 'b' ] && echo no || echo yes
>>> a = ""
>>> if not a:
... print "yes"
... else:
... print "no"
...
yes
>>> a = "a"
>>> if not a:
... print "yes"
... else:
... print "no"
...
no
not操作符用于布尔值(true和false)判断不为真,与if语句连用。上面是不为真用not,那为真时怎么弄呢?
>>> a = "a"
>>> if a:
... print "yes"
... else:
... print "no"
...
yes
>>> a = ""
>>> if a:
... print "yes"
... else:
... print "no"
...
no
4.1.3 成员运算符
|
操作符
|
描述
|
|
in
|
在对象里
|
|
not in
|
不在对象里
|
示例:
>>> 'a' in 'abc'
True
>>> 'd' in 'abc'
False
>>> lst = ['a','b','c']
>>> 'a' in lst
True
>>> 'd' in lst
False
>>> 'a' not in 'abc'
False
>>> 'd' not in 'abc'
True
>>> 'd' not in lst
True
4.1.4 标识运算符
|
操作符
|
描述
|
|
is
|
内存地址相等
|
|
is not
|
内存地址不相等
|
示例:
>>> a = []
>>> b = []
>>> id(a)
139741563903296
>>> id(b)
139741563902144
>>> a is b
False
>>> a is not b
True
这里用到了id()函数,用于获取对象在内存的地址。
4.2 条件判断
4.2.1 单分支
>>> a = 20
>>> if a < 18:
... print "no"
... else:
... print "yes"
...
yes
有时候一个简单的判断语句,感觉这样写麻烦,有没有一条命令搞定的。
有的,简写if语句:
>>> a = 20
>>> result = ("yes" if a == 20 else "no")
>>> result
'yes'
>>> type(result)
<type 'str'>
# 有时会看到别人代码用中括号,意思把结果存储为一个列表
>>> result = ["yes" if a == 20 else "no"]
>>> result
['yes']
>>> type(result)
<type 'list'>
4.2.2 多分支
>>> a = 20
>>> if a < 18:
... print "no"
... elif a == 20:
... print "yes"
... else:
... print "other"
...
yes
4.2.3 pass语句
>>> a = 20
>>> if a < 18:
... print "no"
... elif a == 20:
... pass
... else:
... print "other"
...
pass语句作用是不执行当前代码块,与shell中的冒号做作用一样。
博客地址:http://lizhenliang.blog.51cto.com and https://yq.aliyun.com/u/lizhenliang
QQ群:323779636(Shell/Python运维开发群)
QQ群:323779636(Shell/Python运维开发群)
4.3 循环语句
4.3.1 for
1)迭代对象
遍历字符串,每个字符当做单个遍历:
>>> for i in "abc":
... print i
...
a
b
c
使用range()函数生成一个数字序列列表,并遍历:
>>> for i in range(1,5):
... print i
...
1
2
3
4
回顾下第三章讲的遍历字典:
>>> d = {'a':1, 'b':2, 'c':3}
>>> for i in d.iteritems():
... print "%s:%s" %(i[0],i[1])
...
a:1
c:3
b:2
2)嵌套循环
逐个循环判断外层列表里元素是否存在内层列表:
>>> for i in range(1,6):
... for x in range(3,8):
... if i == x:
... print i
...
3
4
5
3)简写语句
简写for语句:
>>> result = (x for x in range(5))
>>> result
<generator object <genexpr> at 0x030A4FD0>
>>> type(result)
<type 'generator'>
说明:在这里用小括号,会生成一个生成器,在这里知道下就可以了,不过多讲解,后面会专门生成器用途。
# 同样用中括号会以列表存储
>>> result = [ x for x in range(5)]
>>> type(result)
<type 'list'>
>>> result
[0, 1, 2, 3, 4]
for和if语句写一行:
>>> result = [ x for x in range(5) if x % 2 == 0]
>>> result
[0, 2, 4]
4.3.2 while
语法:
while 表达式:
执行语句...
1)输出序列
当条件满足时,停止循环:
>>> while count < 5:
... print count
... count += 1
...
0
1
2
3
4
2)死循环
>>> import time
>>> i = 1
>>> while True:
... print i
... i += 1
... time.sleep(0.5)
...
1
2
3
...... # 会一直循环,直到海枯石烂,天荒地老...
注意:当表达式值为true或者非零时,都会一直循环。
4.3.3 continue和break语句
continue当满足条件时,跳出本次循环。
break当满足条件时,跳出所有循环。
for和while用法一样。
1)基本使用
满足条件跳出当前循环:
#!/usr/bin/env python
for i in range(1,6):
if i == 3:
continue
else:
print i
# python test.py
1
2
4
5
#!/usr/bin/env python
count = 0
while count < 5:
count += 1
if count == 3:
continue
else:
print count
# python test.py
1
2
4
5
满足条件终止循环:
#!/usr/bin/env python
for i in range(1,6):
if i == 3:
break
else:
print i
# python test.py
1
2
#!/usr/bin/env python
count = 0
while count < 5:
count += 1
if count == 3:
break
else:
print count
# python test.py
1
2
2)输入错误次数超过三次退出
例如:提示用户输入名字,如果名字是xiaoming输入正确退出,否则一直提示重新输入,直到三次退出。
#!/usr/bin/env python
count = 0
while 1:
if count < 3:
name = raw_input("Please input your name: ").strip() # .strip()去除首尾空格
if len(name) == 0:
print "Input can not be empty!"
count += 1
continue
elif name == "xiaoming":
print "OK."
break
else:
print "Name input error, please input again!"
count += 1
else:
print "Error three times, Exit!"
break
4.3.4 else语句
else语句会在循环正常执行完才执行。在for循环用法也一样。
>>> count = 0
>>> while count < 5:
... print count
... count += 1
... else:
... print "end"
...
0
1
2
3
4
end
>>> count = 0
>>> while count < 5:
... print count
... break
... else:
... print "end"
...
0
第五章 Python函数你知多少
函数作用:把一些复杂的代码封装起来,函数一般都是一个功能,用的时候才调用,提高重复利用率和简化程序结构。
5.1 语法
def functionName(parms1, parms2, ...):
code block
return expression
函数以def关键字开头,空格后跟函数名,括号里面是参数,用于传参,函数代码段里面引用。
5.2 函数定义与调用
# 定义函数
>>> def func():
... print "Hello world!"
... return "Hello world!"
...
# 调用函数
>>> func()
Hello world!
'Hello world!'
当我们定义好函数,是不执行的,没有任何输出。当输入函数名后跟双小括号才会执行函数里写的代码。
顺便说下print和return区别:
有没有点奇怪!为什么print和return输出一样呢,return就加个单引号,貌似也没啥明显区别啊!其实在解释器下所有的结果都会输出的。
先了解下return作用:结束函数,并返回一个值。如果不跟表达式,会返回一个None。
好,那么我们深入了解下他们区别,举个例子,写个py程序:
#!/usr/bin/env python
def func():
print "1: Hello world!"
return "2: Hello world!"
func()
# python test.py
1: Hello world!
明白点了嘛?print是打印对象的值,而return是返回对象的值。也就是说你return默认是将对象值存储起来,要想知道里面的值,可以用print可以打印。
#!/usr/bin/env python
def func():
print "1: Hello world!"
return "2: Hello world!"
print func()
# python test.py
1: Hello world!
2: Hello world!
为什么函数里面不用print就在这里,往往我们定义一个函数是不需要打印的,而是交给其他代码去处理这个函数返回值。当然,print在调试函数代码时会起到很好的帮助。
5.3 函数参数
5.3.1 接受参数
>>> def func(a, b):
... print a + b
...
>>> func(1, 2)
3
>>> func(1, 2, 3)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: func() takes exactly 2 arguments (3 given)
a和b可以理解为是个变量,可由里面代码块引用。调用函数时,小括号里面的表达式数量要对应函数参数数量,并且按传参按位置赋予函数参数位置。如果数量不对应,会抛出TypeError错误。
当然,函数参数也可以是数组:
>>> def func(a):
... print a
...
>>> func([1,2,3])
[1, 2, 3]
>>> func({'a':1,'b':2})
{'a': 1, 'b': 2}
如果不想一一对应传参,可以指定参数值:
>>> def func(a,b):
... print a + b
...
>>> func(b=2,a=1)
3
5.3.2 函数参数默认值
参数默认值是预先定义好,如果调用函数时传入了这个值,那么将以传入的为实际值,否则是默认值。
>>> def func(a, b=2):
... print a + b
...
>>> func(1)
3
>>> func(1, 3)
4
5.3.3 接受任意数量参数
上面方式固定了参数多个,当不知道多少参数时候可以用以下方式。
单个星号使用:
>>> def func(*a):
... print a
...
>>> func(1,2,3)
(1, 2, 3)
单个星号存储为一个元组。
两个星号使用:
>>> def func(**a):
... print a
...
>>> func(a=1, b=2, c=3)
{'a': 1, 'c': 3, 'b': 2}
两个星号存储为一个字典。可见它们都是以数组的形式传入。
你也许在查资料的时候,会看到这样写的函数参数(*args, **kwargs),与上面只是名字不一样罢了 :
>>> def func(*args, **kwargs):
... print args
... print kwargs
...
>>> func(1,2,3,a=1,b=2,c=3)
(1, 2, 3)
{'a': 1, 'c': 3, 'b': 2}
与普通参数一起使用:
>>> def func(a, b, *c):
... print a + b
... print c
...
>>> func(1,2,3,5,6)
3
(3, 5, 6)
>>> def func(a, b, **c):
... print a + b
... print c
...
>>> func(1,2,a=1,b=2,c=3)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: func() got multiple values for keyword argument 'a'
>>> func(1,2,c=3,d=4,e=5)
3
{'c': 3, 'e': 5, 'd': 4}
抛出异常,是因为传入的第一个参数1,和第三个参数a=1,都认为是传入函数参数a了。请注意下这点。
5.4 作用域
作用域听着挺新鲜,其实很简单,就是限制一个变量或一段代码可用范围,不在这个范围就不可用。提高了程序逻辑的局部性,减少名字冲突。
作用域范围一般是:全局(global)->局部(local)->内置(build-in)
先看看全局和局部变量:
>>> a = 2
>>> def func():
... b = 3
...
>>> a
2
>>> b
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'b' is not defined
a变量的作用域是整个代码中有效,称为全局变量,也就是说一段代码最开始定义的变量。
b变量的作用域在函数内部,也就是局部变量,在函数外是不可引用的。
这么一来,全局变量与局部变量即使名字一样也不冲突。
如果函数内部的变量也能在全局引用,需要使用global声明:
>>> def func():
... global b
... b = 3
...
>>> b
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'b' is not defined
>>> func()
>>> b
3
抛出异常,说明一个问题,当函数没引用使用,里面的代码块是没有解释的。
使用global声明变量后外部是可以调用函数内部的变量的。
5.5 嵌套函数
# 不带参数
>>> def func():
... x = 2
... def func2():
... return x
... return func2 # 返回func2函数
...
>>> func()()
2
>>> func2()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'func2' is not defined
>>> def func():
... x = 2
... global func2
... def func2():
... return x
... return func2
...
>>> func()()
2
>>> func2()
2
内层函数可以访问外层函数的作用域。内嵌函数只能被外层函数调用,但也可以使用global声明全局作用域。
调用内部函数的另一种用法:
# 带参数
>>> def func(a):
... def func2(b):
... return a * b
... return func2
...
>>> f = func(2) # 变量指向函数。是的,变量可以指向函数。
>>> f(5)
10
>>> func(2)(5)
10
内层函数可以访问外层函数的作用域 。但
变量不能重新赋值,举例说明:
>>> def func():
... x = 2
... def func2():
... x = 3
... func2()
... return x
...
>>> func()
2
>>> def func():
... x = 2
... def func2():
... x += 1
... func2()
... return x
...
>>> func()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 5, in func
File "<stdin>", line 4, in func2
UnboundLocalError: local variable 'x' referenced before assignment
5.6 闭包
“官方”的解释是:所谓“闭包”,指的是一个拥有许多变量和绑定了这些变量的环境的表达式(通常是一个函数),因而这些变量也是该表达式的一部分。
其实,上面嵌套函数就是闭包一种方式:
>>> def func(a):
... def func2(b):
... return a * b
... return func2
...
>>> f = func(2) # 变量指向函数。是的,变量可以指向函数。
>>> f(5)
10
func是一个函数,里面又嵌套了一个函数func2,外部函数传过来的a参数,这个变量会绑定到函数func2。func函数以内层函数func2作为返回值,然后把func函数存储到f变量中。当外层函数调用内层函数时,内层函数才会执行(func()()),就创建了一个闭包。
5.7 高阶函数
高阶函数是至少满足这两个任意中的一个条件:
1) 能接受一个或多个函数作为输入。
2)输出一个函数。
abs、map、reduce都是高阶函数,后面会讲解。
其实,上面所讲的嵌套函数也是高阶函数。
举例说明下高阶函数:
>>> def f(x):
... return x * x
...
>>> def f2(func, y):
... return func(y)
...
>>> f2(f, 2)
4
这里的f2就是一个高阶函数,因为它的第一个参数是一个函数,满足了第一个条件。
博客地址:http://lizhenliang.blog.51cto.com and https://yq.aliyun.com/u/lizhenliang
QQ群:323779636(Shell/Python运维开发群)
QQ群:323779636(Shell/Python运维开发群)
5.8 函数装饰器
装饰器(decorator)本身是一个函数,包装另一个函数或类,它可以让其他函数在不需要改动代码情况下动态增加功能,装饰器返回的也是一个函数对象。
先举一个例子,说明下装饰器的效果,定义两个函数,分别传参计算乘积:
#!/usr/bin/python
# -*- coding: utf-8 -*-
def f1(a, b):
print "f1 result: " + str(a * b)
def f2(a, b):
print "f2 result: " + str(a * b)
f1(1, 2)
f2(2, 2)
# python test.py
f1 result: 2
f2 result: 4
跟预期的那样,打印出了乘积。
如果我想给这两个函数加一个打印传入的参数,怎么办,应该这样:
#!/usr/bin/python
# -*- coding: utf-8 -*-
def f1(a, b):
print "f1 parameter: %d %d" %(a, b)
print "f1 result: " + str(a * b)
def f2(a, b):
print "f2 parameter: %d %d" %(a, b)
print "f2 result: " + str(a * b)
f1(1, 2)
f2(2, 2)
# python test.py
f1 parameter: 1 2
f1 result: 2
f2 parameter: 2 2
f2 result: 4
按照所想的打印了传入的参数,有没有方法能更简洁点呢,来看看装饰器后的效果。
#!/usr/bin/python
# -*- coding: utf-8 -*-
def deco(func):
def f(a, b):
print "%s parameter: %d %d" %(func.__name__, a, b)
return func(a, b)
return f
@deco
def f1(a, b):
print "f1 result: " + str(a * b)
@deco
def f2(a, b):
print "f2 result: " + str(a * b)
f1(1, 2)
f2(2, 2)
# python test.py
f1 parameter: 1 2
f1 result: 2
f2 parameter: 2 2
f2 result: 4
可见用装饰器也实现了上面方法,给要装饰的函数添加了装饰器定义的功能,这种方式显得是不是更简洁呢!
好,那么我们继续深入学习装饰器用法。
5.8.1 无参数装饰器
方式1:函装饰器函数装饰函数
#!/usr/bin/python
# -*- coding: utf-8 -*-
def deco(func):
return func
def f1():
print "Hello world!"
myfunc = deco(f1)
myfunc()
# python test.py
Hello world!
方式2:使用语法糖"@"来装饰函数
#!/usr/bin/python
# -*- coding: utf-8 -*-
def deco(func):
return func
@deco
def f1():
print "Hello world!"
f1()
# python test.py
Hello world!
方式1是将一个函数作为参数传给装饰器函数。
方式2使用了语法糖,也实现同样效果。
其实两种方式结果一样,方式1需要每次使用装饰器时要先变量赋值下,而方式2使用装饰器时直接用语法糖"@"引用,会显得更方便些,实际代码中一般也都是用语法糖。
5.8.2 带参数装饰器
#!/usr/bin/python
# -*- coding: utf-8 -*-
def deco(func):
def f(a, b):
print "function name: %s" % func.__name__ # __name__属性是获取函数名,为了说明执行了这个函数
return func(a, b) # 用接受过来的func函数来处理传过来的参数
return f
@deco
def f1(a, b):
print "Hello world!"
print a + b
f1(2, 2)
# python test.py
function name: f1
Hello world!
4
3)不固定参数
#!/usr/bin/python
# -*- coding: utf-8 -*-
def log(func):
def deco(*args, **kwargs):
print "function name: %s" % func.__name__
return func(*args, **kwargs)
return deco
@log
def f1(a, b):
print "f1() run."
print a + b
f1(1,2)
# python test.py
function name: f1
f1() run.
3
4)装饰器加参数
#!/usr/bin/python
# -*- coding: utf-8 -*-
# 三层函数,调用log函数返回deco函数,再调用返回的函数deco,则返回值是_deco函数
def log(arg):
def deco(func):
def _deco(*args, **kwargs):
print "%s - function name: %s" % (arg, func.__name__)
return func(*args, **kwargs)
return _deco
return deco
@log("info")
def f1(a, b):
print "f1() run."
print a + b
f1(1,2)
# python test.py
info - function name: f1
f1() run.
3
再举一个例子,给函数输出字符串带颜色:
#!/usr/bin/python
# -*- coding: utf-8 -*-
def fontColor(color):
begin = "\033["
end = "\033[0m"
d = {
'red':'31m',
'green':'32m',
'yellow':'33m',
'blue':'34m'
}
def deco(func):
print begin + d[color] + func() + end
return deco
@fontColor("red")
def f():
return "Hello world!"
@fontColor("green")
def f2():
return "Hello world!"
可以看出装饰器处理方式满足了高阶函数的条件,所以装饰器也是一种高阶函数。
装饰器优点:灵活给装饰器增加功能,而不修改函数,提高代码可重复利用性,增加可读性。
5.9 匿名函数
匿名函数:定义函数的一种形式,无需定义函数名和语句块,因此代码逻辑会受到局限,同时也减少代码量,增加可读性。
在Python中匿名函数是lambda。
举例子说明def关键字与lambda函数定义函数区别:
# 普通函数
>>> def func():
... return "Hello world!"
...
>>> func()
>>> def func(a, b):
... return a * b
...
>>> func(2, 2)
4
# 匿名函数
>>> f = lambda:"Hello world!"
>>> f()
'Hello world!'
>>> f = lambda a, b: a * b # 冒号左边是函数参数,右边是返回值
>>> f(2, 2)
4
lambda函数一行就写成一个函数功能,省去定义函数过程,让代码更加精简。
5.10 内置高阶函数
5.10.1 map()
语法:map(function, sequence[, sequence, ...]) -> list
将序列中的元素通过函数处理返回一个新列表。
例如:
>>> lst = [1,2,3,4,5]
>>> map(lambda x:str(x)+".txt", lst)
['1.txt', '2.txt', '3.txt', '4.txt', '5.txt']
5.10.2 filter()
语法:filter(function or None, sequence) -> list, tuple, or string
将序列中的元素通过函数处理返回一个新列表、元组或字符串。
例如:过滤列表中的奇数
>>> lst = [1,2,3,4,5]
>>> filter(lambda x:x%2==0, lst)
[2, 4]
5.10.3 reduce()
语法:reduce(function, sequence[, initial]) -> value
reduce()是一个二元运算函数,所以只接受二元操作函数。
例如:计算列表总和
>>> lst = [1,2,3,4,5]
>>> reduce(lambda x,y:x+y, lst)
15
先将前两个元素相加等于3,再把结果与第三个元素相加等于6,以此类推。这就是reduce()函数功能。
第六章 Python类(面向对象编程)
什么是面向对象编程?
面向对象编程(Object Oriented Programming,OOP,面向对象程序设计)是一种计算机编程架构。Python就是这种编程语言。
面向对象程序设计中的概念主要包括:对象、类、继承、动态绑定、封装、多态性、消息传递、方法。
1)对象:类的实体,比如一个人。
2)类:一个共享相同结构和行为的对象的集合。通俗的讲就是分类,比如人是一类,动物是一类。
3)继承:类之间的关系,比如猫狗是一类,他们都有四条腿,狗继承了这个四条腿,拥有了这个属性。
4)动态绑定:在不修改源码情况下,动态绑定方法来给实例增加功能。
5)封装:把相同功能的类方法、属性封装到类中,比如人两条腿走路,狗有四条腿走路,两个不能封装到一个类中。
6)多态性:一个功能可以表示不同类的对象,任何对象可以有不同的方式操作。比如一个狗会走路、会跑。
7)消息传递:一个对象调用了另一个对象的方法。
8)方法:类里面的函数,也称为成员函数。
对象=属性+方法。
属性:变量。
方法:函数。
实例化:创建一个类的具体实例对象。比如一条泰迪。
什么是类?
类是对对象的抽象,对象是类的实体,是一种数据类型。它不存在内存中,不能被直接操作,只有被实例化对象时,才会变的可操作。
类是对现实生活中一类具有共同特征的事物的抽象描述。
6.1 类和类方法语法
# 类
class ClassName():
pass
# 类中的方法
def funcName(self):
pass
self代表类本身。类中的所有的函数的第一个参数必须是self。
6.2 类定义与调用
#!/usr/bin/python
# -*- coding: utf-8 -*-
class MyClass():
x = 100
def func(self, name):
return "Hello %s!" % name
def func2(self):
return self.x
mc = MyClass() # 类实例化,绑定到变量mc
print mc.x # 类属性引用
print mc.func("xiaoming") # 调用类方法
print mc.func2()
# python test.py
100
Hello xiaoming!
100
上面示例中,x变量称为类属性,类属性又分为类属性和实例属性:
1)类属性属于类本身,通过类名访问,一般作为全局变量。比如mc.x
2)如果类方法想调用类属性,需要使用self关键字调用。比如self.x
3)实例属性是实例化后对象的方法和属性,通过实例访问,一般作为局部变量。下面会讲到。
4)当实例化后可以动态类属性,下面会讲到。
类方法调用:
1)类方法之间调用:self.<方法名>(参数),参数不需要加self
2)外部调用:<实例名>.<方法名>
6.3 类的说明
给类添加注释,提高可阅读性,可通过下面方式查看。
方法1:
>>> class MyClass:
... """
... 这是一个测试类.
... """
... pass
...
>>> print MyClass.__doc__
这是一个测试类.
>>>
方法2:
>>> help(MyClass)
Help on class MyClass in module __main__:
class MyClass
| 这是一个测试类.
6.4 类内置方法
|
内置方法
|
描述
|
|
__init__(self, ...)
|
初始化对象,在创建新对象时调用 |
|
__del__(self)
|
释放对象,在对象被删除之前调用
|
|
__new__(cls, *args, **kwd)
|
实例的生成操作,在__init__(self)之前调用 |
|
__str__(self)
|
在使用print语句时被调用,返回一个字符串
|
|
__getitem__(self, key)
|
获取序列的索引key对应的值,等价于seq[key]
|
|
__len__(self)
|
在调用内建函数len()时被调用
|
|
__cmp__(str, dst)
|
比较两个对象src和dst
|
|
__getattr__(s, name)
|
获取属性的值
|
|
__setattr__(s, name, value)
|
设置属性的值
|
|
__delattr__(s, name)
|
删除属性
|
|
__gt__(self, other)
|
判断self对象是否大于other对象
|
|
__lt__(self, other)
|
判断self对象是否小于other对象
|
|
__ge__(self, other)
|
判断self对象是否大于或等于other对象
|
|
__le__(self, other)
|
判断self对象是否小于或等于other对象
|
|
__eq__(self, other)
|
判断self对象是否等于other对象
|
|
__call__(self, *args)
|
把实例对象作为函数调用 |
6.5 初始化实例属性
很多类一般都有初始状态的,常常定义对象的共同特性,也可以用来定义一些你希望的初始值。
Python类中定义了一个构造函数__init__,对类中的实例定义一个初始化对象,常用于初始化类变量。当类被实例化,第二步自动调用的函数,第一步是__new__函数。
__init__构造函数也可以让类传参,类似于函数的参数。
__init__构造函数使用:
#!/usr/bin/python
# -*- coding: utf-8 -*-
class MyClass():
def __init__(self):
self.name = "xiaoming"
def func(self):
return self.name
mc = MyClass()
print mc.func()
# python test.py
xiaoming
__init__函数定义到类的开头.self.name变量是一个实例属性,只能在类方法中使用,引用时也要这样self.name。
类传参:
#!/usr/bin/python
# -*- coding: utf-8 -*-
class MyClass():
def __init__(self, name):
self.name = name
def func(self, age):
return "name: %s,age: %s" %(self.name, age)
mc = MyClass('xiaoming') # 第一个参数是默认定义好的传入到了__init__函数
print mc.func('22')
# python test.py
Name: xiaoming, Age: 22
6.6 类私有化(私有属性)
6.6.1 单下划线
实现模块级别的私有化,以单下划线开头的变量和函数只能类或子类才能访问。当from modulename import * 时将不会引入以单下划线卡头的变量和函数。
#!/usr/bin/python
# -*- coding: utf-8 -*-
class MyClass():
_age = 21
def __init__(self, name=None):
self._name = name
def func(self, age):
return "Name: %s, Age: %s" %(self._name, age)
mc = MyClass('xiaoming')
print mc.func('22')
print mc._name
print mc._age
# python test.py
Name: xiaoming, Age: 22
xiaoming
21
_age和self._name变量其实就是做了个声明,说明这是个内部变量,外部不要去引用它。
6.6.2 双下划线
以双下划线开头的变量,表示私有变量,受保护的,只能类本身能访问,连子类也不能访问。避免子类与父类同名属性冲突。
#!/usr/bin/python
# -*- coding: utf-8 -*-
class MyClass():
__age = 21
def __init__(self, name=None):
self.__name = name
def func(self, age):
return "Name: %s, Age: %s" %(self.__name, age)
mc = MyClass('xiaoming')
print mc.func('22')
print mc.__name
print mc.__age
# python test.py
Name: xiaoming, Age: 22
Traceback (most recent call last):
File "test.py", line 12, in <module>
print mc.__name
AttributeError: MyClass instance has no attribute '__name'
可见,在单下划线基础上又加了一个下划线,同样方式类属性引用,出现报错。说明双下划线变量只能本身能用。
如果想访问私有变量,可以这样:
#!/usr/bin/python
# -*- coding: utf-8 -*-
class MyClass():
__age = 21
def __init__(self, name=None):
self.__name = name
def func(self, age):
return "Name: %s, Age: %s" %(self.__name, age)
mc = MyClass('xiaoming')
print mc.func('22')
print mc._MyClass__name
print mc._MyClass__age
# python test.py
Name: xiaoming, Age: 22
xiaoming
21
self.__name变量编译成了self._MyClass__name,以达到不能被外部访问的目的,并没有真正意义上的私有。
6.6.3 特殊属性(首尾双下划线)
一般保存对象的元数据,比如__doc__、__module__、__name__:
>>> class MyClass:
"""
这是一个测试类说明的类。
"""
pass
# dic()返回对象内变量、方法
>>> dir(MyClass)
['__doc__', '__module__']
>>> MyClass.__doc__
'\n\t\xd5\xe2\xca\xc7\xd2\xbb\xb8\xf6\xb2\xe2\xca\xd4\xc0\xe0\xcb\xb5\xc3\xf7\xb5\xc4\xc0\xe0\xa1\xa3\n\t'
>>> MyClass.__module__
'__main__'
>>> MyClass.__name__
'MyClass'
这里用到了一个新内置函数dir(),不带参数时,返回当前范围内的变量、方法的列表。带参数时,返回参数的属性、方法的列表。
Python自己调用的,而不是用户来调用。像__init__ ,你可以重写。
6.7 类的继承
子类继承父类,子类将继承父类的所有方法和属性,提高代码重用。
1)简单继承
#!/usr/bin/python
# -*- coding: utf-8 -*-
class Parent():
def __init__(self, name=None):
self.name = name
def func(self, age):
return "Name: %s, Age: %s" %(self.name, age)
class Child(Parent):
pass
mc = Child('xiaoming')
print mc.func('22')
print mc.name
# python test.py
Name: xiaoming, Age: 22
xiaoming
2)子类实例初始化
如果子类重写了构造函数,那么父类的构造函数将不会执行:
#!/usr/bin/python
# -*- coding: utf-8 -*-
class Parent():
def __init__(self):
self.name_a = "xiaoming"
def funcA(self):
return "function A: %s" % self.name_a
class Child(Parent):
def __init__(self):
self.name_b = "zhangsan"
def funcB(self):
return "function B: %s" % self.name_b
mc = Child()
print mc.name_b
print mc.funcB()
print mc.funcA()
# python test.py
zhangsan
function B: zhangsan
Traceback (most recent call last):
File "test2.py", line 17, in <module>
print mc.funcA()
File "test2.py", line 7, in funcA
return "function A: %s" % self.name_a
AttributeError: Child instance has no attribute 'name_a'
抛出错误,提示调用funcA()函数时,没有找到name_a属性,也就说明了父类的构造函数并没有执行。
如果想解决这个问题,可通过下面两种方法:
方法1:调用父类构造函数
#!/usr/bin/python
# -*- coding: utf-8 -*-
class Parent():
def __init__(self):
self.name_a = "xiaoming"
def funcA(self):
return "function A: %s" % self.name_a
class Child(Parent):
def __init__(self):
Parent.__init__(self)
self.name_b = "zhangsan"
def funcB(self):
return "function B: %s" % self.name_b
mc = Child()
print mc.name_b
print mc.funcB()
print mc.funcA()
# python test.py
zhangsan
function B: zhangsan
function A: xiaoming
方法2:使用supper()函数继承
#!/usr/bin/python
# -*- coding: utf-8 -*-
class Parent(object):
def __init__(self):
self.name_a = "xiaoming"
def funcA(self):
return "function A: %s" % self.name_a
class Child(Parent):
def __init__(self):
super(Child, self).__init__()
self.name_b = "zhangsan"
def funcB(self):
return "function B: %s" % self.name_b
mc = Child()
print mc.name_b
print mc.funcB()
print mc.funcA()
# python test.py
zhangsan
function B: zhangsan
function A: xiaoming
6.8 多重继承
每个类可以拥有多个父类,如果调用的属性或方法在子类中没有,就会从父类中查找。多重继承中,是依次按顺序执行。
类简单的继承:
#!/usr/bin/python
# -*- coding: utf-8 -*-
class A:
def __init__(self):
self.var1 = "var1"
self.var2 = "var2"
def a(self):
print "a..."
class B:
def b(self):
print "b..."
class C(A,B):
pass
c = C()
c.a()
c.b()
print c.var1
print c.var2
# python test.py
a...
b...
var1
var2
类C继承了A和B的属性和方法,就可以像使用父类一样使用它。
子类扩展方法,直接在子类中定义即可:
#!/usr/bin/python
# -*- coding: utf-8 -*-
class A:
def __init__(self):
self.var1 = "var1"
self.var2 = "var2"
def a(self):
print "a..."
class B:
def b(self):
print "b..."
class C(A,B):
def test(self):
print "test..."
c = C()
c.a()
c.b()
c.test()
print c.var1
print c.var2
# python test.py
a...
b...
test...
var1
var2
在这说明下经典类和新式类。
经典类:默认没有父类,也就是没继承类。
新式类:有继承的类,如果没有,可以继承object。在Python3中已经默认继承object类。
经典类在多重继承时,采用从左到右深度优先原则匹配,而新式类是采用C3算法(不同于广度优先)进行匹配。两者主要区别在于遍历父类算法不同,具体些请在网上查资料。
6.9 方法重载
直接定义和父类同名的方法,子类就修改了父类的动作。
#!/usr/bin/python
# -*- coding: utf-8 -*-
class Parent():
def __init__(self, name='xiaoming'):
self.name = name
def func(self, age):
return "Name: %s, Age: %s" %(self.name, age)
class Child(Parent):
def func(self, age=22):
return "Name: %s, Age: %s" %(self.name, age)
mc = Child()
print mc.func()
# python test.py
Name: xiaoming, Age: 22
6.10 修改父类方法
在方法重载中调用父类的方法,实现添加功能。
#!/usr/bin/python
# -*- coding: utf-8 -*-
class Parent():
def __init__(self, name='xiaoming'):
self.name = name
def func(self, age):
return "Name: %s, Age: %s" %(self.name, age)
class Child(Parent):
def func(self, age):
print "------"
print Parent.func(self, age) # 调用父类方法
print "------"
mc = Child()
mc.func('22')
# python test.py
------
Name: xiaoming, Age: 22
------
还有一种方式通过super函数调用父类方法:
#!/usr/bin/python
# -*- coding: utf-8 -*-
class Parent():
def __init__(self, name='xiaoming'):
self.name = name
def func(self, age):
return "Name: %s, Age: %s" %(self.name, age)
class Child(Parent):
def func(self, age):
print "------"
print super(Child, self).func(age)
print "------"
mc = Child()
mc.func('22')
# python test.py
------
Traceback (most recent call last):
File "test2.py", line 15, in <module>
mc.func('22')
File "test2.py", line 11, in func
print super(Child, self).func(age)
TypeError: must be type, not classobj
抛出错误,因为super继承只能用于新式类,用于经典类就会报错。
那我们就让父类继承object就可以使用super函数了:
#!/usr/bin/python
# -*- coding: utf-8 -*-
class Parent(object):
def __init__(self, name='xiaoming'):
self.name = name
def func(self, age):
return "Name: %s, Age: %s" %(self.name, age)
class Child(Parent):
def func(self, age):
print "------"
print super(Child, self).func(age) # 调用父类方法。在Python3中super参数可不用写。
print "------"
mc = Child()
mc.func('22')
# python test.py
------
Name: xiaoming, Age: 22
------
6.11 属性访问的特殊方法
有四个可对类对象增删改查的内建函数,分别是getattr()、hasattr()、setattr()、delattr()。
6.11.1 getattr()
返回一个对象属性或方法。
>>> class A:
... def __init__(self):
... self.name = 'xiaoming'
... def method(self):
... print "method..."
...
>>> c = A()
>>> getattr(c, 'name', 'Not find name!')
'xiaoming'
>>> getattr(c, 'namea', 'Not find name!')
>>> getattr(c, 'method', 'Not find method!')
<bound method A.method of <__main__.A instance at 0x93fa70>>
>>> getattr(c, 'methoda', 'Not find method!')
'Not find method!'
6.11.2 hasattr()
判断一个对象是否具有属性或方法。返回一个布尔值。
>>> hasattr(c, 'name')
True
>>> hasattr(c, 'namea')
False
>>> hasattr(c, 'method')
True
>>> hasattr(c, 'methoda')
False
6.11.3 setattr()
给对象属性重新赋值或添加。如果属性不存在则添加,否则重新赋值。
>>> hasattr(c, 'age')
False
>>> setattr(c, 'age', 22)
>>> c.age
22
>>> hasattr(c, 'age')
True
6.11.4 delattr()
删除对象属性。
>>> delattr(c, 'age')
>>> hasattr(c, 'age')
False
6.12 类装饰器
与函数装饰器类似,不同的是类要当做函数一样调用:
#!/usr/bin/python
# -*- coding: utf-8 -*-
class Deco:
def __init__(self, func):
self._func = func
self._func_name = func.__name__
def __call__(self):
return self._func(), self._func_name
@Deco
def f1():
return "Hello world!"
print f1()
# python test.py
('Hello world!', 'f1')
6.13 类内置装饰器
下面介绍类函数装饰器,在实际开发中,感觉不是很常用。
6.10.1 @property
@property属性装饰器的基本功能是把类中的方法当做属性来访问。
在没使用属性装饰器时,类方法是这样被调用的:
>>> class A:
... def __init__(self, a, b):
... self.a = a
... self.b = b
... def func(self):
... print self.a + self.b
...
>>> c = A(2,2)
>>> c.func()
4
>>> c.func
<bound method A.func of <__main__.A instance at 0x7f6d962b1878>>
使用属性装饰器就可以像属性那样访问了:
>>> class A:
... def __init__(self, a, b):
... self.a = a
... self.b = b
... @property
... def func(self):
... print self.a + self.b
...
>>> c = A(2,2)
>>> c.func
4
>>> c.func()
4
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'NoneType' object is not callable
6.10.2 @staticmethod
@staticmethod是静态方法装饰器,可以通过类对象访问,也可以通过实例化后类对象实例访问。
实例方法的第一个参数是self,表示是该类的一个实例,称为类对象实例。
而使用静态方法装饰器,第一个参数就不用传入实例本身(self),那么这个方法当做类对象,由Python自身处理。
看看普通方法的用法:
>>> class A:
... def staticMethod(self):
... print "not static method..."
...
>>> c = A()
>>> c.staticMethod()
not static method...
使用静态方法则是这么用:
>>> class A:
... @staticmethod
... def staticMethod():
... print "static method..."
...
>>> A.staticMethod() # 可以通过类调用静态方法
static method...
>>> c = A()
>>> c.staticMethod() # 还可以使用普通方法调用
static method...
静态方法和普通的非类方法作用一样,只不过命名空间是在类里面,必须通过类来调用。一般与类相关的操作使用静态方法。
6.10.3 @classmethod
@classmethod是类方法装饰器,与静态方法装饰器类似,也可以通过类对象访问。主要区别在于类方法的第一个参数要传入类对象(cls)。
>>> class A:
... @classmethod
... def classMethod(cls):
... print "class method..."
... print cls.__name__
...
>>> A.classMethod()
class method...
A
6.14 __call__方法
可以让类中的方法像函数一样调用。
>>> class A:
... def __call__(self, x):
... print "call..."
... print x
...
>>> c = A()
>>> c(123)
call...
123
>>> class A:
... def __call__(self, *args, **kwargs):
... print args
... print kwargs
...
>>> c = A()
>>> c(1,2,3,a=1,b=2,c=3)
(1, 2, 3)
{'a': 1, 'c': 3, 'b': 2}
转自
博客地址:http://lizhenliang.blog.51cto.com and https://yq.aliyun.com/u/lizhenliang