spark03
map遍历每一个元素
mapPartitions每次遍历一个分区
foreach action算子
foreachPartitions action算子
collect
nginx flume hdfs hbase spark mysql
如果是插入数据,那么foreachPartition比较好,因为每个分区建立一个连接
提交的一个任务中,存在几个job? action算子有几个就存在几个job
reduce得出一个结果
| scala> var arr=Array(1,2,3,4,5,6) arr: Array[Int] = Array(1, 2, 3, 4, 5, 6) scala> sc.makeRDD(arr,2) res0: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at makeRDD at <console>:27 scala> res0.reduce(_+_) res1: Int = 21 |
count算子
| scala> res0.count res2: Long = 6 |
first
| scala> res0.first res4: Int = 1 |
take算子
| scala> sc.makeRDD(arr,3) res9: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[1] at makeRDD at <console>:27 scala> res9.take(2) res10: Array[Int] = Array(1, 2) scala> res9.take(4) res11: Array[Int] = Array(1, 2, 3, 4) |
take算子可以产生多个job

take算子每次提交任务的时候都是sc.runJob,扫描的元素个数和总的元素个数比对,扫描的分区数量和总的分区数量比对
top算子
| var arr=Array(1,2,3,4,5,6,7,8,9) sc.makeRDD(arr,2) scala> res9.top(3) res14: Array[Int] = Array(9, 8, 7) |
先将数据进行排序,然后倒序截取前N个
takeOrdered正序排序,然后截取前N个
| scala> res9.takeOrdered(3) res15: Array[Int] = Array(1, 2, 3) |
countByKey按照key得出value的数量
| scala> var arr = Array(("a",1),("b",1),("a",1)) arr: Array[(String, Int)] = Array((a,1), (b,1), (a,1)) scala> sc.makeRDD(arr,3) res16: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[4] at makeRDD at <console>:27 scala> res16.countByKey() res17: scala.collection.Map[String,Long] = Map(a -> 2, b -> 1) |
collect将数据收集到driver端,一般都是为了测试显示 Array
collectAsMap 将数据从executors端收集到driver端。Map
| var arr=Array(1,2,3,4,5,6,7,8,9) scala> sc.makeRDD(arr,3) scala> res9.collect res18: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9) scala> res9.collectAsMap <console>:29: error: value collectAsMap is not a member of org.apache.spark.rdd.RDD[Int] res9.collectAsMap ^ scala> var arr=Array(("a",1),("b",1),("a",1)) arr: Array[(String, Int)] = Array((a,1), (b,1), (a,1)) scala> sc.makeRDD(arr,3) res14: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[9] at makeRDD at <console>:27 res14.countByKey() scala> res14.collectAsMap res15: scala.collection.Map[String,Int] = Map(b -> 1, a -> 1) |
算子在executor中执行的原理和过程
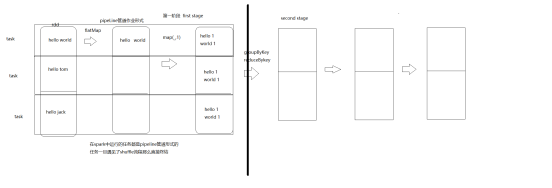
rdd是一个弹性的分布式的数据集,默认带有分区的,每个分区会被一个线程处理
rdd中存在数据?

sortBy排序
| scala> res27.collect res30: Array[Int] = Array(1, 2, 3, 4, 6, 7, 9) scala> res26.sortBy(t=>t,false,4) res31: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[27] at sortBy at <console>:29 scala> res31.partitions.size res32: Int = 4 |
sortBy可以改变分区数量,同时排序可以正序和倒序,并且带有shuffle
sortByKey按照key进行排序
| scala> var arr = Array((1,2),(2,1),(3,3),(6,9),(5,0)) arr: Array[(Int, Int)] = Array((1,2), (2,1), (3,3), (6,9), (5,0)) scala> sc.makeRDD(arr,3) res33: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[28] at makeRDD at <console>:27 scala> res33.sortByKey() res34: org.apache.spark.rdd.RDD[(Int, Int)] = ShuffledRDD[31] at sortByKey at <console>:29 scala> res34.collect res35: Array[(Int, Int)] = Array((1,2), (2,1), (3,3), (5,0), (6,9)) scala> res33.sortByKey def sortByKey(ascending: Boolean,numPartitions: Int): org.apache.spark.rdd.RDD[(Int, Int)] scala> res33.sortByKey(false) res36: org.apache.spark.rdd.RDD[(Int, Int)] = ShuffledRDD[34] at sortByKey at <console>:29 scala> res36.collect res37: Array[(Int, Int)] = Array((6,9), (5,0), (3,3), (2,1), (1,2)) scala> res33.sortByKey(false,10) res38: org.apache.spark.rdd.RDD[(Int, Int)] = ShuffledRDD[37] at sortByKey at <console>:29 scala> res38.partitions,size <console>:1: error: ';' expected but ',' found. res38.partitions,size ^ scala> res38.partitions.size res39: Int = 6 scala> res33.partitions.size res40: Int = 3 scala> res38.partitions.size res41: Int = 6 |
sortBykey产生shuffle,他的分区器就是rangePartitioner groupByKey reduceBykey他们的分区器都是hashPartitioner
比如:sortByKey它的分区器是rangePartitioner,这个分区器是按照范围和数据量进行自适配的,如果元素个数大于等于分区的个数,这样的分区不会产生差别,如果数据量比分区数量还要小,那么指定的分区个数和真正的分区个数就会产生差别
union intersection subtract
| scala> var arr = Array(1,2,3,4,5) arr: Array[Int] = Array(1, 2, 3, 4, 5) scala> var arr1 = Array(3,4,5,6,7) arr1: Array[Int] = Array(3, 4, 5, 6, 7) scala> sc.makeRDD(arr) res42: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[38] at makeRDD at <console>:27 scala> sc.makeRDD(arr1) res43: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[39] at makeRDD at <console>:27 scala> res42 union res41 <console>:35: error: type mismatch; found : Int required: org.apache.spark.rdd.RDD[Int] res42 union res41 ^ scala> res42 union res43 res45: org.apache.spark.rdd.RDD[Int] = UnionRDD[40] at union at <console>:33 scala> res45.collect res46: Array[Int] = Array(1, 2, 3, 4, 5, 3, 4, 5, 6, 7) |
union只是结果集的联合,没有任何业务逻辑,所以分区数量是两个rdd的分区数量总和
| scala> res42 intersection res43 res47: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[46] at intersection at <console>:33 scala> res47.collect res48: Array[Int] = Array(3, 4, 5) scala> res42 substract res43 <console>:33: error: value substract is not a member of org.apache.spark.rdd.RDD[Int] res42 substract res43 ^ scala> res42 subtract res43 res50: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[50] at subtract at <console>:33 scala> res50.collect res51: Array[Int] = Array(1, 2) |
交集和差集都是原来分区中的数据,所以分区数量不会改变
distinct
| scala> var arr = Array(1,1,1,1,1,12,2,3,3,3,3,3,4,4,4,4,4) arr: Array[Int] = Array(1, 1, 1, 1, 1, 12, 2, 3, 3, 3, 3, 3, 4, 4, 4, 4, 4) scala> sc.makeRDD(arr,3) res52: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[51] at makeRDD at <console>:27 scala> res52.distinct res53: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[54] at distinct at <console>:29 scala> res53.collect res54: Array[Int] = Array(3, 12, 4, 1, 2) |
使用groupbyKey
| scala> res52.map((_,null)) res55: org.apache.spark.rdd.RDD[(Int, Null)] = MapPartitionsRDD[55] at map at <console>:29 scala> res55.groupByKey() res56: org.apache.spark.rdd.RDD[(Int, Iterable[Null])] = ShuffledRDD[56] at groupByKey at <console>:31 scala> res55.map(_._1) res57: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[57] at map at <console>:31 scala> res57.collect res58: Array[Int] = Array(1, 1, 1, 1, 1, 12, 2, 3, 3, 3, 3, 3, 4, 4, 4, 4, 4) scala> res56.map(_._1) res59: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[58] at map at <console>:33 scala> res59.collect res60: Array[Int] = Array(3, 12, 4, 1, 2) |
使用reduceByKey
| scala> res52.map((_,null)) res61: org.apache.spark.rdd.RDD[(Int, Null)] = MapPartitionsRDD[59] at map at <console>:29 scala> res61.reduceByKey((a,b)=>a) res62: org.apache.spark.rdd.RDD[(Int, Null)] = ShuffledRDD[60] at reduceByKey at <console>:31 scala> res62.map(_._1) res63: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[61] at map at <console>:33 scala> res63.collect res64: Array[Int] = Array(3, 12, 4, 1, 2) |
| scala> res52.distinct(10) res66: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[64] at distinct at <console>:29 scala> res66.partitions.size res67: Int = 10 |
作业题:
| http://bigdata.edu360.cn/laozhang http://bigdata.edu360.cn/laozhang http://bigdata.edu360.cn/laozhao http://bigdata.edu360.cn/laozhao http://bigdata.edu360.cn/laozhao http://bigdata.edu360.cn/laoduan http://bigdata.edu360.cn/laoduan http://javaee.edu360.cn/xiaoxu http://javaee.edu360.cn/xiaoxu http://javaee.edu360.cn/laoyang http://javaee.edu360.cn/laoyang http://javaee.edu360.cn/laoyang http://bigdata.edu360.cn/laozhao |
全局topN,整个学校里面的老师访问的排名的前几个(不区分专业)
学科topN,每个专业的老师的排名前几个?
第一种分组方式 第二种过滤器的方式
join leftOuterJoin rightOuterJoin cogroup
以上是join的关联操作,rdd必须是对偶元组的
| scala> var arr = Array(("zhangsan",200),("lisi",250),("zhaosi",300),("wangwu",400)) arr: Array[(String, Int)] = Array((zhangsan,200), (lisi,250), (zhaosi,300), (wangwu,400)) scala> var arr1 = Array(("zhangsan",30),("lisi",25),("zhaosi",12),("liuneng",5)) arr1: Array[(String, Int)] = Array((zhangsan,30), (lisi,25), (zhaosi,12), (liuneng,5)) scala> sc.makeRDD(arr,3) res68: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[65] at makeRDD at <console>:27 scala> sc.makeRDD(arr1,3) res69: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[66] at makeRDD at <console>:27 scala> res68 join res69 res70: org.apache.spark.rdd.RDD[(String, (Int, Int))] = MapPartitionsRDD[69] at join at <console>:33 scala> res70.collect res71: Array[(String, (Int, Int))] = Array((zhangsan,(200,30)), (lisi,(250,25)), (zhaosi,(300,12))) scala> res68 leftOuterJoin res69 res72: org.apache.spark.rdd.RDD[(String, (Int, Option[Int]))] = MapPartitionsRDD[72] at leftOuterJoin at <console>:33 scala> res72.collect res73: Array[(String, (Int, Option[Int]))] = Array((zhangsan,(200,Some(30))), (wangwu,(400,None)), (lisi,(250,Some(25))), (zhaosi,(300,Some(12)))) scala> res68 rightOuterJoin res69 res74: org.apache.spark.rdd.RDD[(String, (Option[Int], Int))] = MapPartitionsRDD[75] at rightOuterJoin at <console>:33 scala> res74.collect res75: Array[(String, (Option[Int], Int))] = Array((zhangsan,(Some(200),30)), (lisi,(Some(250),25)), (zhaosi,(Some(300),12)), (liuneng,(None,5))) scala> res68 cogroup res69 res76: org.apache.spark.rdd.RDD[(String, (Iterable[Int], Iterable[Int]))] = MapPartitionsRDD[77] at cogroup at <console>:33 scala> res76.collect res77: Array[(String, (Iterable[Int], Iterable[Int]))] = Array((zhangsan,(CompactBuffer(200),CompactBuffer(30))), (wangwu,(CompactBuffer(400),CompactBuffer())), (lisi,(CompactBuffer(250),CompactBuffer(25))), (zhaosi,(CompactBuffer(300),CompactBuffer(12))), (liuneng,(CompactBuffer(),CompactBuffer(5)))) |