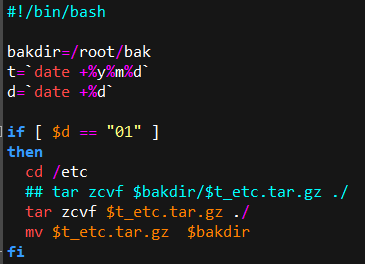
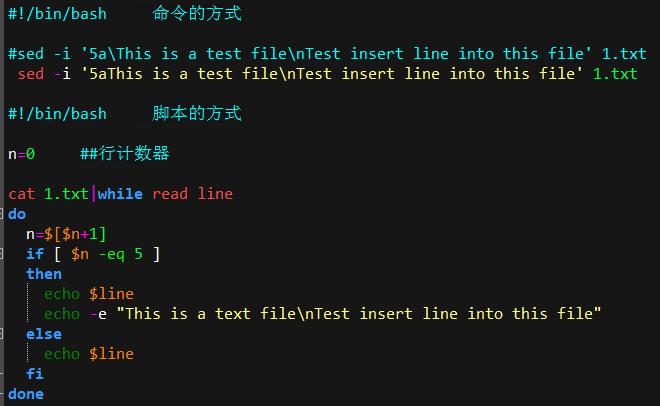
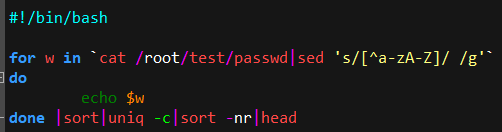
| #!/bin/bash f=member.txt ##人员列表,一行一个人员
member_n=`wc -l $f|awk '{print $1}'`
group_n=7 ##7**2,人员数开平方 ## 根据人员姓名计算该成员所在小组的ID,即小组号
get_n()
{
## 根据人员姓名计算cksum值,即根据字符串计算随机数字,非随机字符串
l=`echo $1|cksum|awk '{print $1}'`
## 获取一个随机数
n1=$RANDOM
## cksum值和随机数相加,使随机数更加随机;然后除以小组数取余;这样每次获得的余数都会不一样(即人员分的组不一样)
n2=$[$l+$n1]
g_id=$[$n2%$group_n]
## 假如小组数为7,则余数的范围则是0-6,余数为0则小组id为7
if [ $g_id -eq 0 ]
then
g_id=$group_n
fi
echo $g_id ## 函数返回值
} ## 检测n_$i.txt组临时文件,用来记录对应的每个小组内的成员,n_3.txt用来记录第3小组内的成员
for i in `seq 1 group_n`
do
## 如果脚本执行过则该文件会存在,本次执行脚本前应该删除该临时文件,每次分组内的成员都不一样
[ -f n_$i.txt ] && rm -f n_$i.txt
done shuf $f|while read name
do
## 计算人员所在组的ID,调用前面的函数
g=`get_n $name`
## 将人员写入其对应的组临时文件n_$i.txt中
echo "$name" >> n_$g.txt
done 定义计算组临时文件n_$i.txt行数的函数
nu()
{
wc -l $1|awk '{print $1}'
} ## 定义函数:获取小组人员数量的最大值
max()
{
ma=0 ## 小组内人员数量的最大值,最小是0
for i in `seq 1 $group_n|shuf`
do
n=`nu n_$i.txt`
if [ $n -gt $ma ]
then
ma=$n
fi
done
echo $ma
}
## 定义函数:获取小组人员数量的最小值
min()
{
mi=$member_n ## 小组内人员数量的最小值,最大是member_n,所有人员的总数量
for i in `seq 1 $group_n|shuf`
do
n=`nu n_$i.txt`
if [ $n -lt $mi ]
then
mi=$n
fi
done
echo $mi
} ## 定义四舍五入函数
div()
{
n=`echo "scale=1;$1/$2"|bc` ## 两个数相除
n1=`echo "scale=1;$n+0.5"|bc` ## 两个数相除的商 加 0.5
echo $n1|cut -d. -f1 ## 两个数相除的商 加 0.5,取整数
} ## 小组组员数量的平均值(非四舍五入)
ava_n=$[$member_n/$group_n]
## 小组组员数量的平均值(四舍五入)
ava_n1=`div $member_n $group_n` if [ $ava_n -eq $ava_n1 ]
then
## 定义初始最小值
ini_min=1
## while循环:把人数多的组里面的人员 转移到 人数少的组里去
## 人数少的组的定义是:其组成员的数量 小于 小组组员数量的平均值
while [ $ini_min -lt $ava_n1 ]
do
m1=`max` ## 小组组员数量的最大值
m2=`min`
for i in `seq 1 $group_n|shuf`
do
n=`nu n_$i.txt`
## 找出人数最多的组对应的组人员文件f1,可能有多个,这里取出现的第一个即可
if [ $n -eq $m1 ]
then
f1=n_$i.txt
## 找出人数最多少的组对应的组人员文件f2,可能有多个,这里取出现的第一个即可
else if [ $n -eq $m2 ]
then
f2=n_$i.txt
fi
done
name=`tail -n1 $f1` ## 取人数最多的组人员文件f1的最后一个人名
echo "$name" >> $f2
sed -i "/$name/d" $1 ## 在组人员文件f1中删除刚刚取走的人名
## 把此时(转移人员后)组员数量的最小值赋值给变量ini_min
ini_min=`min` ## 调用min函数;循环后变量ini_min的值最接近变量ava_n1的值
done
else
## 定义初始最大值
ini_max=$member_n
## while循环:把人数多的组里面的人员 转移到 人数少的组里去
## 人数多的组的定义是:其组成员的数量 大于 小组组员数量的平均值
while [ $ini_max -gt $ava_n1 ]
do
m1=`max` ## 小组组员数量的最大值
m2=`min`
for i in `seq 1 $group_n|shuf`
do
n=`nu n_$i.txt`
## 找出人数最多的组对应的组人员文件f1,可能有多个,这里取出现的第一个即可
if [ $n -eq $m1 ]
then
f1=n_$i.txt
## 找出人数最多少的组对应的组人员文件f2,可能有多个,这里取出现的第一个即可
else if [ $n -eq $m2 ]
then
f2=n_$i.txt
fi
done
name=`tail -n1 $f1` ## 取人数最多的组人员文件f1的最后一个人名
echo "$name" >> $f2
sed -i "/$name/d" $1 ## 在组人员文件f1中删除刚刚取走的人名
## 把此时(转移人员后)组员数量的最小值赋值给变量ini_min
ini_max=`max` ## 调用max函数;循环后变量ini_max的值最接近变量ava_n1的值
fi for i in `seq 1 $group_n`
do
echo -e "\033[34m$i 组成员有:\033[0m" ## 带颜色输出组成员
cat n_$i.txt
## 删除组临时文件
rm -f n_$i.txt
echo
done |