在使用mongodb开发工作中,mongodb内存使用非常之大,64G的内存使用了99%的内存
通过整理和查询,了解了mongodb的内存工作原理,特此跟大家分享
mongodb 使用MMAP 将文件映射到内存中
wiki: http://www.hudong.com/wiki/mmap
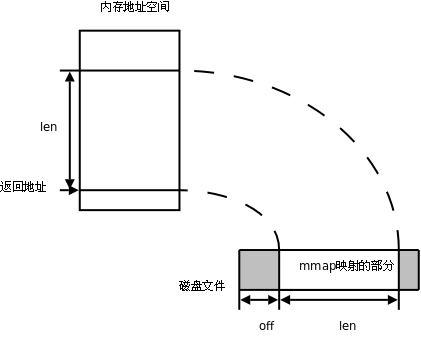
我用python实现了一个mongodb在内存实现方面的功能,key:value我是用的hash,没有使用btree,代码如下仅供参考:
代码在文章后附属
1.启动mongodb 服务
python _mongo_.py
2.链接到mongo服务
telnet 0.0.0.0 8900
3.开始调试
ps x|grep python #找到mongo对应的进程号 #接下来使用vmmap [mac] pmap[linux]查看内存使用情况 vmmap -resident 2546|grep wiyun mapped file 0000000101000000-000000010d801000 [200.0M 8K] rw-/rwx SM=PRV /Users/liuzheng/py.work.dir/wgit/wiyun0.db mapped file 000000010d801000-000000011a002000 [200.0M 8K] rw-/rwx SM=PRV /Users/liuzheng/py.work.dir/wgit/wiyun1.db #这里大家看到文件初始大小为200M,RSS内存使用了8k,VM 使用了200M #接下来我们操作数据库 telnet 0.0.0.0 8900 set a=1 set c=2 get a get c set a=helloworld_helloworld_helloworld_helloworld_helloworld_helloworld_helloworld_helloworld_helloworld_helloworld_helloworld_helloworld_helloworld_helloworld_helloworld_helloworld_helloworld_helloworld_helloworld_ set c=helloworld_helloworld_helloworld_helloworld_helloworld_helloworld_helloworld_helloworld_helloworld_helloworld_helloworld_helloworld_helloworld_helloworld_helloworld_helloworld_helloworld_helloworld_helloworld_ set d=helloworld_helloworld_helloworld_helloworld_helloworld_helloworld_helloworld_helloworld_helloworld_helloworld_helloworld_helloworld_helloworld_helloworld_helloworld_helloworld_helloworld_helloworld_helloworld_ set e=helloworld_helloworld_helloworld_helloworld_helloworld_helloworld_helloworld_helloworld_helloworld_helloworld_helloworld_helloworld_helloworld_helloworld_helloworld_helloworld_helloworld_helloworld_helloworld_ gat e vmmap -resident 2546|grep wiyun mapped file 0000000101000000-000000010d801000 [200.0M 1032K] rw-/rwx SM=PRV /Users/liuzheng/py.work.dir/wgit/wiyun0.db mapped file 000000010d801000-000000011a002000 [200.0M 8K] rw-/rwx SM=PRV /Users/liuzheng/py.work.dir/wgit/wiyun1.db #这里RSS内存使用变为了1032K,说明是使用过多数据进入了内存 cat wiyun0.db #电池没电了,先到这里
摘录:再说说MongoDB是如何使用内存的
目前,MongoDB使用的是内存映射存储引擎,它会把磁盘IO操作转换成内存操作,如果是读操作,内存中的数据起到缓存的作用,如果是写操作,内存还可以把随机的写操作转换成顺序的写操作,总之可以大幅度提升性能。MongoDB并不干涉内存管理工作,而是把这些工作留给操作系统的虚拟缓存管理器去处理,这样的好处是简化了MongoDB的工作,但坏处是你没有方法很方便的控制MongoDB占多大内存,事实上MongoDB会占用所有能用的内存,所以最好不要把别的服务和MongoDB放一起。 有时候,即便MongoDB使用的是64位操作系统,也可能会遭遇臭名昭著的OOM问题,出现这种情况,多半是因为限制了虚拟内存的大小所致,可以这样查看当前值: shell> ulimit -a | grep 'virtual' 多数操作系统缺省都是把它设置成unlimited的,如果你的操作系统不是,可以这样修改: shell> ulimit -v unlimited 不过要注意的是,ulimit的使用是有上下文的,最好放在MongoDB的启动脚本里
#coding=utf-8
#_mongo_.py 源码
import os, sys
import errno
import functools
import socket
import time
import os
import traceback
import memcache
from tornado import ioloop, iostream
from threading import Thread
from Queue import Queue
import logging
import mmap
import random
streamDict = {} #用于保存stream
streamRequests = {} #Stream 请求数据队列
io_loop = None #侦听网络服务对象
mmap_obj = None
def printLog(log):
tstr = time.strftime("%Y-%m-%d %X", time.localtime())
print tstr, log
def stream_add(stream, count):
streamkey = str(stream)
streamDict[streamkey] = (stream, 0)
streamRequests[streamkey] = Queue()
def stream_remove(streamkey, stream):
print "stream closed", stream.__dict__
stream.close()
if streamDict.has_key(streamkey):
del streamDict[streamkey]
if streamRequests.has_key(streamkey):
del streamRequests[streamkey]
class MMapping(object):
data_map = []
_hash = {}
def __init__(self, data_path, db):
self.read_ns_file(data_path,db)
def read_ns_file(self, data_path, db):
#f = open(os.path.join(data_path, db + ".ns"), "w+b")
#for i in xrange(1):
sz = (1024 * 1024 * 200 )
db_name = "%s.db" % (db)
f = open(os.path.join(data_path,db_name), "w+b")
f.seek(sz)
if f.readline() != "\0":
f.write('\0')
f.flush()
MMapping.data_map.append(mmap.mmap(f.fileno(), 0))
def parse_data(self, data):
command, values = data.split(" ")
if command == "set":
key, value = values.split("=")
return command, key, value
else:
key = values.strip()
self._hash.get(key, "no match\r\n")
return command, key, None
def flush_data(self, data):
self.data_map[0].write(data)
def get_data(self, data):
command, key, value = self.parse_data(data)
print "command,key,value", command, key, value
if command == "set":
d = "%s=%s" % (key, value)
self.flush_data(d)
self._hash[key] = value
return "True"
else:
return self._hash.get(key, "on match")
class ClockResponse(Thread):
def __init__(self):
Thread.__init__(self)
self.flag = True
self.count = 0
def run(self):
while self.flag:
#打印 LOG,N次/打印
ct = self.count % 10000
if ct == 0:
print 'now connections:%s' % (len(streamDict))
self.count = ct + 1
us = 0
for streamkey, (stream, num) in streamDict.items():
queue = streamRequests[streamkey]
try:
data = queue.get(False)
except Exception, e:
continue
if data:
print "get data %s", data
else:
continue
try:
d = mmap_obj.get_data(data)
stream.write(d + "\r\n")
except Exception, e:
logging.error(e)
stream.write(str(e) + "\r\n")
time.sleep(0.01)
def stop(self):
self.flag = False
class SocketRequest(object):
delimiter = "\r\n"
def __init__(self, stream, address):
self.stream = stream
self.streamkey = str(stream)
self.address = address
self.stream.read_until(SocketRequest.delimiter, self.on_body)
def on_body(self, data):
queue = streamRequests[self.streamkey]
size = queue.qsize()
if size <= 10000:
print "put in queue %s " % data
queue.put(data)
try:
self.stream.read_until(SocketRequest.delimiter, self.on_body)
except Exception, e:
print "in read", e
stream_remove(self.streamkey, self.stream)
def connection_ready(sock, fd, events):
while True:
try:
connection, address = sock.accept()
except socket.error, e:
if e[0] not in (errno.EWOULDBLOCK, errno.EAGAIN):
raise
return
print "connection on:", address
#non-block
connection.setblocking(0)
stream = iostream.IOStream(connection, io_loop)
stream_add(stream, 0)
skey = str(stream)
scallback = functools.partial(stream_remove, skey, stream)
stream.set_close_callback(scallback)
SocketRequest(stream, address)
def run_thread_worker(n=1):
threads = []
for t in xrange(n):
clock = ClockResponse()
threads.append(clock)
for t in threads:
t.start()
if __name__ == '__main__':
server_port = 8900
#init data
data_path = os.path.abspath(os.path.join(os.path.dirname(__file__)))
mmap_obj = MMapping(data_path, "wiyun")
run_thread_worker(1)
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM, socket.IPPROTO_TCP)
sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
sock.setblocking(0)
sock.bind(("", server_port))
sock.listen(9999)
io_loop = ioloop.IOLoop.instance()
callback = functools.partial(connection_ready, sock)
io_loop.add_handler(sock.fileno(), callback, io_loop.READ)
try:
io_loop.start()
except KeyboardInterrupt:
io_loop.stop()
clock.stop()
print "exited cleanly"
sys.exit(1)
except Exception, e:
print e
#mongodb 调试
shell> top -p $(pidof mongod)
Mem: 32872124k total, 30065320k used, 2806804k free, 245020k buffers
Swap: 2097144k total, 100k used, 2097044k free, 26482048k cached
VIRT RES SHR %MEM
1892g 21g 21g 69.6
#平时可以通过mongo命令行来监控MongoDB的内存使用情况,如下所示:
mongo> db.serverStatus().mem:
{
"resident" : 22346,
"virtual" : 1938524,
"mapped" : 962283
}
其中内存相关字段的含义是:
mapped:映射到内存的数据大小
visze:占用的虚拟内存大小
res:实际使用的内存大小
注:如果操作不能再内存中完成,结果faults列的数值不会是0,视大小可能有性能问题。
在上面的结果中,vsize是mapped的两倍,而mapped等于数据文件的大小,所以说vsize是数据文件的两倍,之所以会这样,是因为本例中,MongoDB开启了journal,需要在内存里多映射一次数据文件,如果关闭journal,则vsize和mapped大致相当。
如果想验证这一点,可以在开启或关闭journal后,通过pmap命令来观察文件映射情况:
shell> pmap $(pidof mongod)