运维日常三大工作,发布,变更,故障处理
事实上对正常的发布来说,还有很多步骤
工作当中或者IT典型的公司,在提供产品的工作当中,大体分为两种运维环境
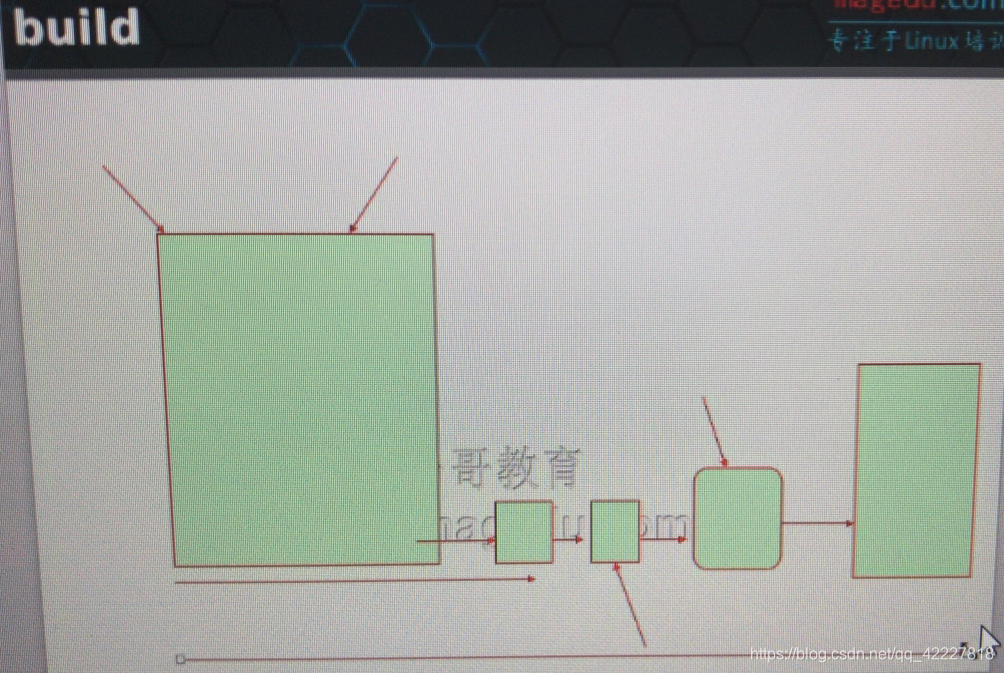
以电商站点为例,开发代码写完以后要想上线应用,以java为例,代码开发以后,第二个步骤肯定不可能直接把代码部署到线上应用环境中去,
所以一般第二步叫做构建,build(类似c代码的编译,编译完以后才能测试,一个庞大的java项目是需要一个构建工具进行构建的,类似编译操作一样,来检查代码间的关系,来完成依赖关系的检查,)
第二步构建,构建好以后
第三步可以做测试了,比如单元测试,功能测试,集成测试等,测试完成,如果没问题,这个时候就可以放在预发布环境里了。
测试是放在测试环境中做的,发布之前还应该放在预发布环境,预发布环境要进行接受性测试(发到准线上,我们检查对应代码运行结果,根据访问界面之类的,是否没有问题)
如果没有问题,就可以上线了
第四步部署
所以大致分几步
(先做开发计划 plan,plan完成以后开始实施开发)
1.写代码的过程(开发)
(开发完以后,要做单元测试,因为不同的人对应的开发项目本身有可能只负责这个项目中的很小一部分功能,由于每个功能的开发进度不一定完全一样,所以每个小组开发完功能以后,会将它集成到对应的代码树上,类似于推送的
写完代码要push到远程仓库来合并,合并完以后做单元测试)
2.开发完以后,做构建,
3.构建以后做测试(单元测试,都没问题)
4.测试都没问题(一般部署到预发布环境中),这个过程做交付,delive
5.最会一步,从预发布环境挪到线上环境中,完成发布过程,这个过程称为deploy部署
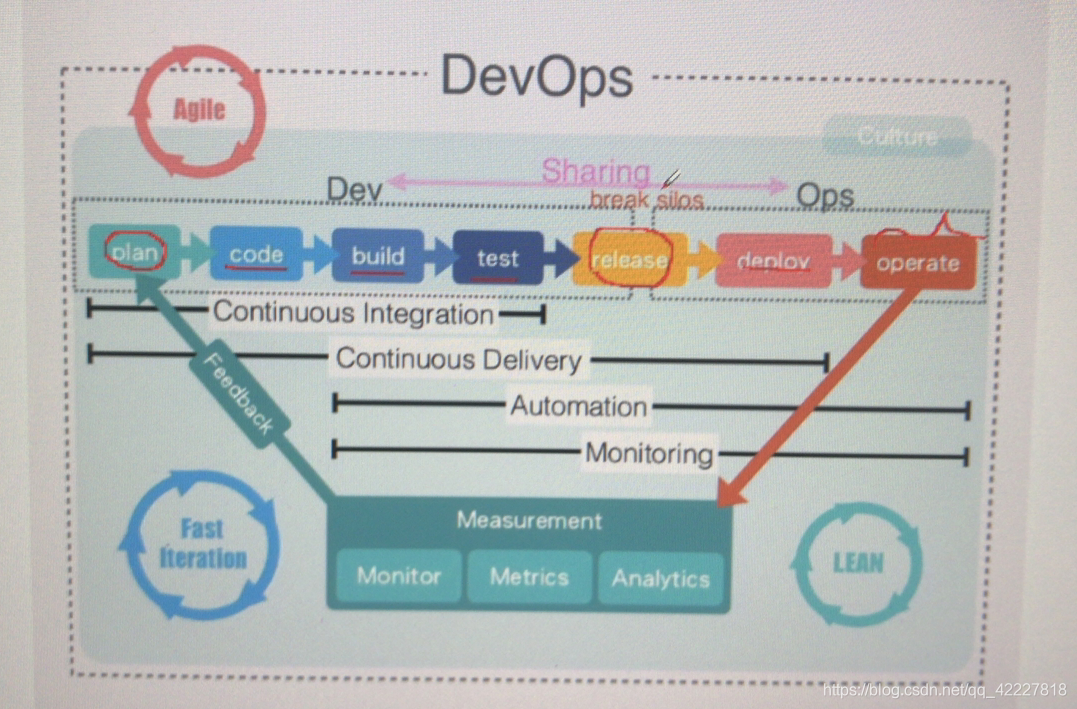
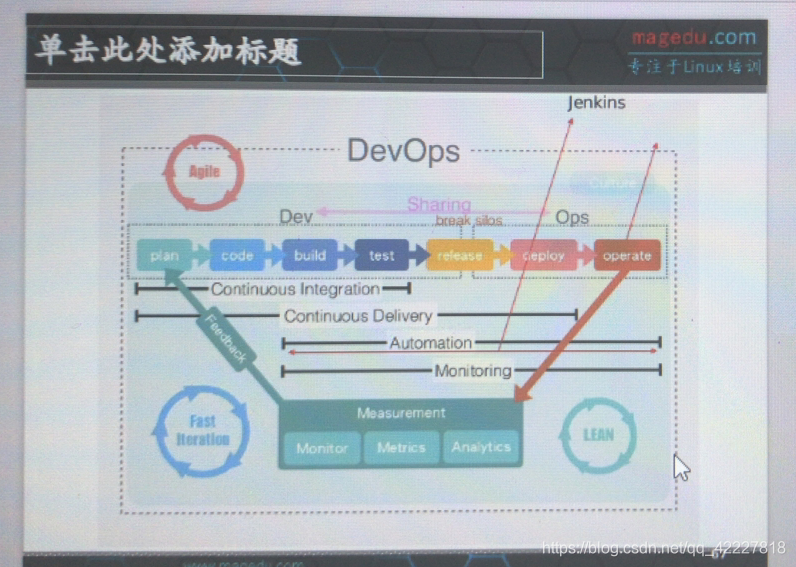
devops,早期开发讲究敏捷开发,精密开发延展出来的所谓的精密开发技术,或是敏捷开发的实现方案
一般一个产品从开发到上线运维,大致有几个步骤
1.要做计划plan
2.开始写代码(传统需要写很久放到主干当中,这样就不容易发现问题,)敏捷开发,每个人每一天的代码,下班之前都要立即整合到主干当中,以便尽早发现问题,不然会发现开发一个月集成,各种冲突合并不了,于是推倒重来,所以现在讲究敏捷开发,持续开发,持续集成,持续测试
3.代码写好以后,构建,build,一般需要专门的一个构建主机来实现,指的是以个完整的开发环境,(如果非完整开发环境,)java代码早期的构建工具叫ant,靠各种各样的ant脚本来实现
前几年出现了新的构建工具,Gradle,不管怎么说,构建也是需要依靠工具来实现的,就像c一眼的make一样(就是个构建工具,而不是编译工具)
4.构建完以后如果没有问题 ,把构建的结果部署到测试环境上,(也有可能在做单元测试的时候不需要放到测试环境中去)
5.测试通过没问题,就可以发现一个版本release,
释出一个版本,就可以开始上线,上线之前有一步deliver,放到预发布环境,叫交付
6.运维工程师把代码从预发布环境中拖出来放到线上环境,叫做deploy部署
7.然后是日常工作中的运维工作operate
(在运维过程不断的,把这个对应项目的收集过来的数据,动态数据,分析结果,监控数据等,给持续反馈给开发人员,开发人员根据反馈的结果,就能知道自己对应的代码,哪里有问题,哪里需要改进,因此做下一个版本计划)
但是早期的环节其实是隔开的,意味着开发是开发,运维是运维,而DevOps就把整个环节关联起来,可以实现使用一个pam工具,把整个过程都能自动来实现,可能有几个概念
从plan到test,叫持续集成 continus integration ,CI
从plan到最后的deploy(能够交付给线上环境,),叫CD持续交付,continus delivery
交付以后(交付就是发布到预发布环境,最后一步还是运维人员手工完成的,如果让运维人员自动完成,叫自动部署)
从构建,测试到交付,上线等,完全都靠自动化的工具来实现,所以称为自动化运维,automation
从预发布环境拖到发布环境,从deliver到deploy 大致可以靠一些工具来实现,比如ansible(可以实现让你写一个简单的ansible的playbook,或者public所谓的内部的定义,从预发环境中,把对应的内容给推送到对应的生产环境中去,其实就是一个发布工具),除了code这一步,每一步都可以依赖于工具来实现
比如build可以靠ant,Maven和Gradle
test也可以用测试工具,比如java,junit
release 可以做一个内部的ftp服务,测试代码没问题用脚本推到ftp服务器上,这个过程叫释出
在release中还可以推送放到预发布环境中,叫做交付,可能这个过程需要依赖一些脚本来实现
放在预发布环境中,接下来运维工程师就可以使用ansible或saltstack之类的接受,从预发布环境中,拖出来扔到生产环境中,production environment

一般遇到的环境有三种
development environment 开发环境
testing environment 测试环境
production environment 生产环境
小公司的生产环境很有可能是,开发环境一定是本地的,有一些实现开发托管的工具,gitlab(方便开发把写的代码推送道对应的仓库中去,可以让别人看得见,实现分享)
测试i环境有可能有两种情形testing environment
1.可能是本地的
2.可能在云端
一般而言,开发环境注重所提供的应用,能运行的环境,而测试环境通常部署的是API接口环境,而且有单台或者很小的,能让用户,能让程序员写代码,并随时调用各种API接口即可、
要真正意义上构建生产环境中的环境,一个主机故障,要想让他重新上线,大体步骤有,
1.先安装系统(可以基于PXE或者cobbler,自动安装系统)
2.各种基础服务初始化(NTP,DNS服务,等等都是基础,一般做的操作,@安装程序包,@2提供合适的配置文件,@3启动服务)这个过程,一般称为部署应用程序的过程
(如果是一个网站站点,把对应的程序环境准备好了还不够要想真正被用户访问还需要发布应用程序)
3.发布应用程序,放到指定主机合适运用程序的指定目录下,这样就称为发布的过程
4.最后需要做监控,把每个主机纳入到监控信息中,随时监控
 ‘这几个步骤都可以人工智能,也可以借助于工具来实现,比如最底层的安装操作系统可以使用PXE技术,使用kickstart
‘这几个步骤都可以人工智能,也可以借助于工具来实现,比如最底层的安装操作系统可以使用PXE技术,使用kickstart
系统安装其实是一个费时费力的活,如果在虚拟话环境中,用的每一个主机都是虚拟机的话,其实简单的多,少一个主机示例,可以在云端创建一个实例,而这个实例可以基于已有的来实现,必须装系统,就比如vmare 虚拟机克隆一样,需要一个虚拟机可以把对应的虚拟机做好的模板,放到指定位置,基于它直接启动,操作系统给你提前做好了,只需要展开启动即可,
安装系统这一步都不需要了,云技术为什么这么流行就是这样子,因为作为一个厂商来讲,无需再主机出现故障来讲,再去买主机,扛一个继续上架之类的,只需要申请一个实例即可,大大降低了,底层多余的工作
对更多公司来讲,需要的更多的可能是私有云而不是公有云,而且很多公司使用的云只不过是一个虚拟化管理器,算不上是云,
**向上一层是configuration,完成系统配置,安装程序,提供配置,启动服务等,也可以靠一堆的工具来实现,说白了这对工具是配置服务的配置系统
**
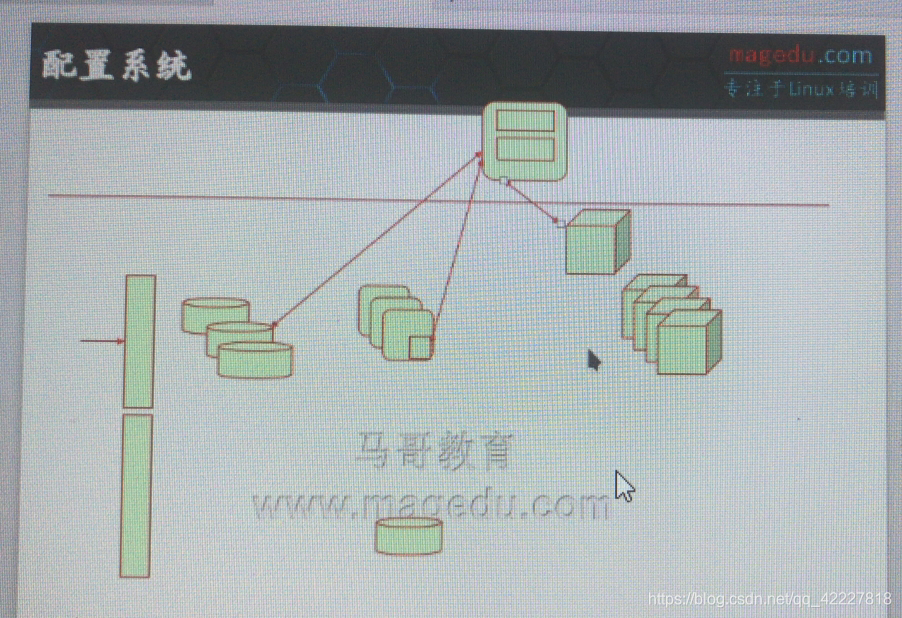
**一个站点,应该有调度器(调度器做高可用),用户请求过来以后,后端有一对缓存服务器(可能有三台),缓存服务器后可能有图片服务器(三台)背后可能有分布式文件系统或者分布式存储(中心节点和storage node)
这整个环境会有多台主机,每一台主机应该装哪些程序,提供哪些服务,拥有什么配置文件,应该规划好的,稳定运行的配置文件,应该有所记录,
万一哪台主机坏 了,就需要用新的主机,提供好这个主机此前在这个位置本来的具有的各种环境各种应用
(把每个主机所有的配置文件,应用程序,放到一个配置仓库中,这个库里边为每个主机,内部需要一个DNS系统,靠主机名来区别主机,不对外提供服务,只是内部各主机间的识别靠主机名来识别,为每一个主机定义好一种描述语言,定义好应该装哪些程序包,应该是哪个配置文件,为每一个主机都定义好配置,所以更重要的是,在为每一个被管控的主机的时候,都可以安装一个agent,或者不安装,通过ssh也行,在任意一个主机上,装一个代理程序,这个代理程序跟每一个管控主机,通信一次,通信的作用
这个主机,现在的状态和应该有的状态查看是否一致,不一致就拖过来强行应用,应用失败就通知管理员,需要手工接入,所以不一不小心把程序停了,都没有关系的,即便没有监控系统,因为只需要去看一下目标状态和自己的真实状态是否一致,不一致就强行该安装的安装,该重启的服务重启
从而使得每一个主机都处于应该处于的状态)
**
所谓就称为配置系统,虽然需要给每一个主机定义一个配置,但是如果每个主机都需要装clienting服务的话,难道在每个主机都定义一遍吗,太麻烦了
真正配置时,先写一个定义模块(clienting服务),再写一个模块(mariadb服务),再定义一个模块(tomcat),还有nginx,定义很多模块
如果这个主机是一个nginx主机,就拖进来nginx 模块和clienting模块,
模块定义好,把模块拼凑好,让这个主机成为应有的模块
所以应该分为前后端,第一定义模块,第二为每个主机定义好应该拥有的目标状态,模块之间还有依赖关系,先后次序,要描述清楚
任何主机只要出现故障,只需要给这个主机装好系统,配置好主机名,上线,这个主机只要一上线,就要向服务端拖取自己相关的配置,把没有完成的配置,直接配置好
这样就需要有一个人,对整个配置环境精确理解,同时要开发好这么一个模块才可以,听起来很容易,做起来还是挺麻烦的,需要自己的配置语言开发的,跟varnish类似,dcl
真实的环境其实有三种,开发,测试,线上,三个环境拥有的配置模块和环境都不一样,需要为三种环境各自开发配置适用的模块,才能确保三种环境自动配置的,这其实并不容易
几百台主机,几千台虚拟机这个工作就有可能不止一个人来做了
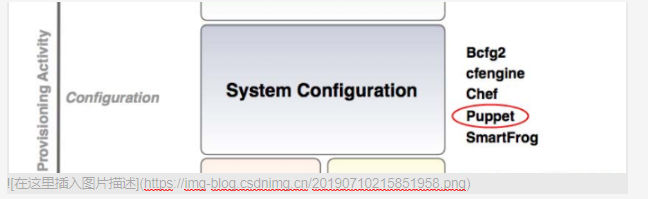
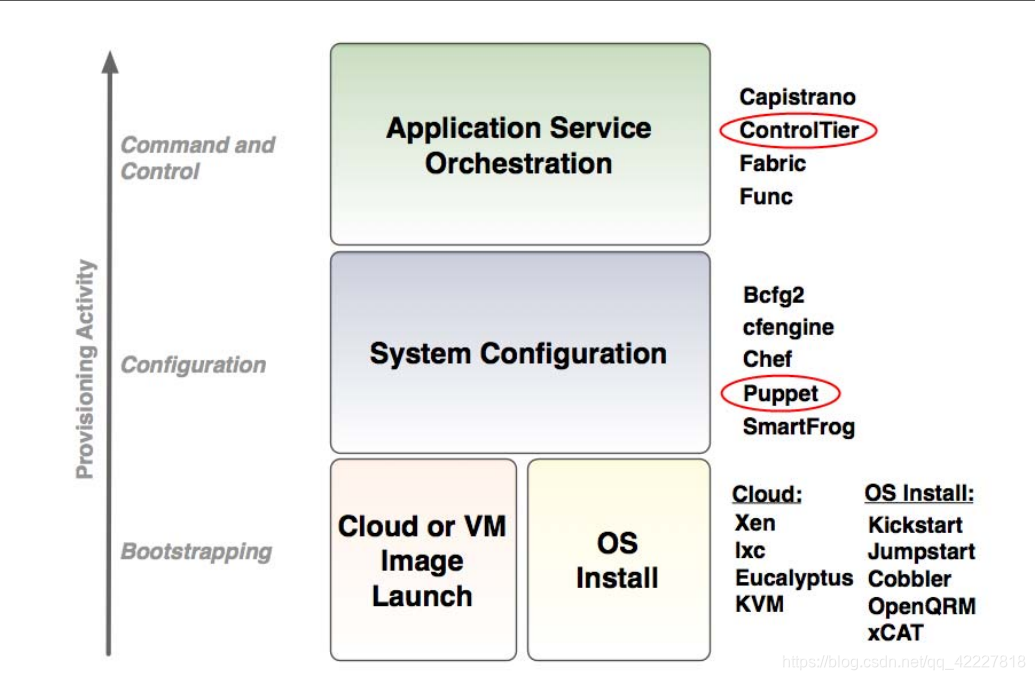
现在比较流行的配置系统有
1.puppet(ruby语言研发的,而且早期google都在使用,非常强大,ruby是一种不少人用,很少有人骂的语言,这种语言其实非常强大,国外 有些组织比较喜欢)
同类程序,用python研发的,叫saltstack
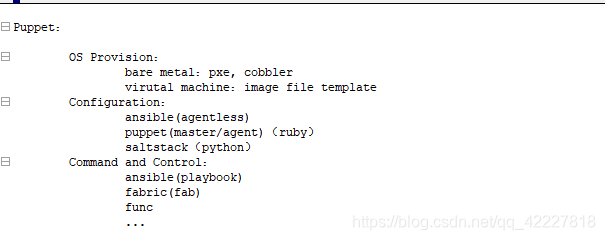
Puppet:
OS Provision:
bare metal:pxe, cobbler
virutal machine:image file template
Configuration: 配置工具
ansible(agentless)
puppet(master/agent)(ruby)
saltstack(python)
Command and Control:
ansible(playbook)
fabric(fab)
func
…

应用服务编排Application service orchestration
现在有几个应用彼此之间有依赖关系,需要在部署发布的时候,按次序一步步完成
这个层级叫 command and control 命令和控制
这个层级的工具有很多比如 ansible,fabric,func
任务编排工具
ansible算是一个奇葩,既能做编排,又能做配置,但一样也做不好,因为很慢
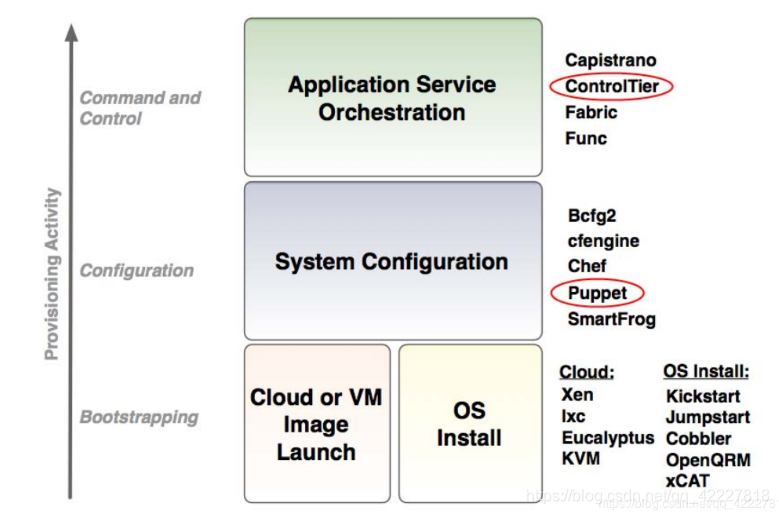
所以做运维的时候也需要一组工具栈,来完成应用,从底层的bootstrapping,到configuration,到顶级的command and control,各有工具来实现
如果要完成DEVOPS的话,整个过程基本上是自动,automation
能完成这一系列流水线,开源工具 jenkins
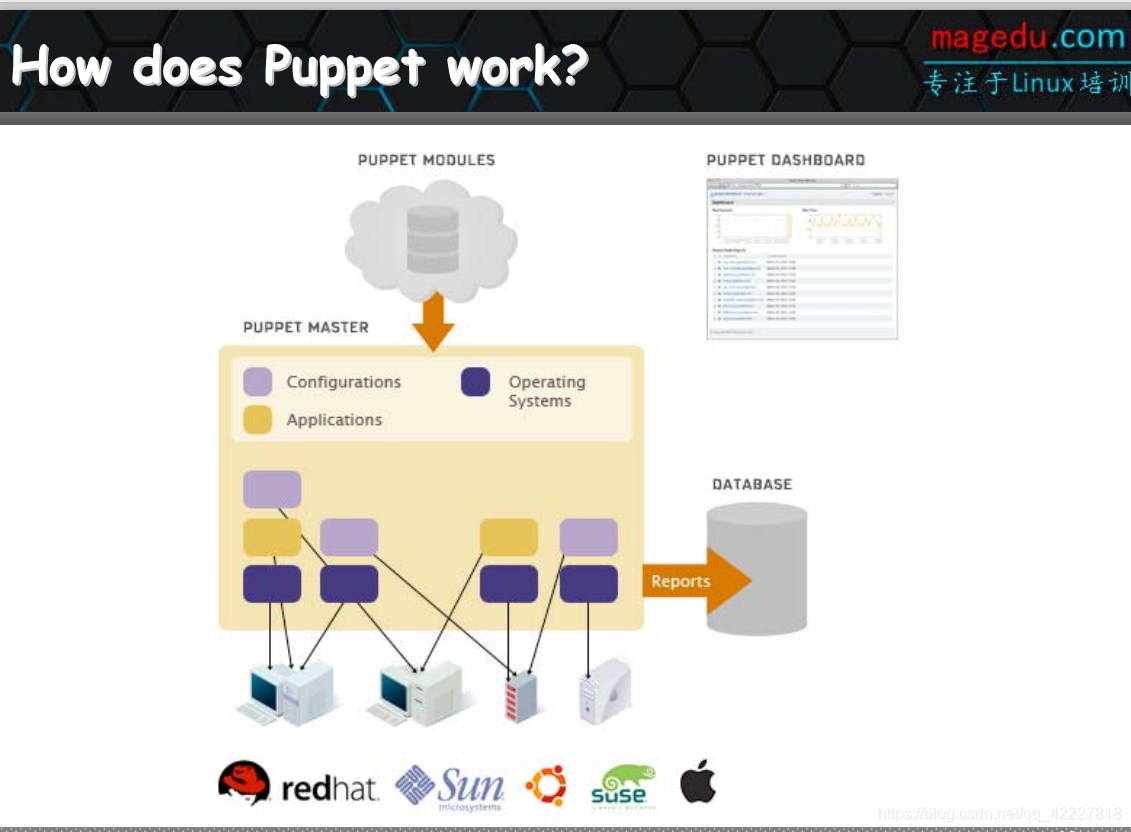
描述一下配置工具,puppet
仅是一个IT基础设施自动化管理工具,主要作用,帮助系统管理员管理基础设施的整个生命周期:包括 供应provisioning,配置configuration,编排联动orchestration及报告reporting
基于puppet工具,可实现自动化重复任务,快速部署关键性应用以及再本地或云端完成主动管理变更和快速扩展架构规模

对puppet而言,对于系统管理员而言,底层各种功能的实现,都是抽象的,而且统一到同一个接口上,统一以后的所被管理的对象,都被抽象成资源(跟ansible的概念是一样的)
安装程序包,window,IBM的ax。,惠普的unix,linux中的centos,deepin安装程序包,各自底层的安装方式是不一样的,对于管理来讲,定义什么,装什么程序包,底层什么系统就不去管,会找对应的操作系统的合适安装方法,把它装上,所以说是抽象的,抽象这个资源层级以后,只用描述清除对应的资源应该处于什么目标状态即可
正是这种抽象语言,使得配置的时候只需要用它的描述性语言即可、
puppet对于操作系统的安装并不是强项,通常只是用于做配置
initial configuration 配置初始化
fixes修复
updates 更新
audits 审计
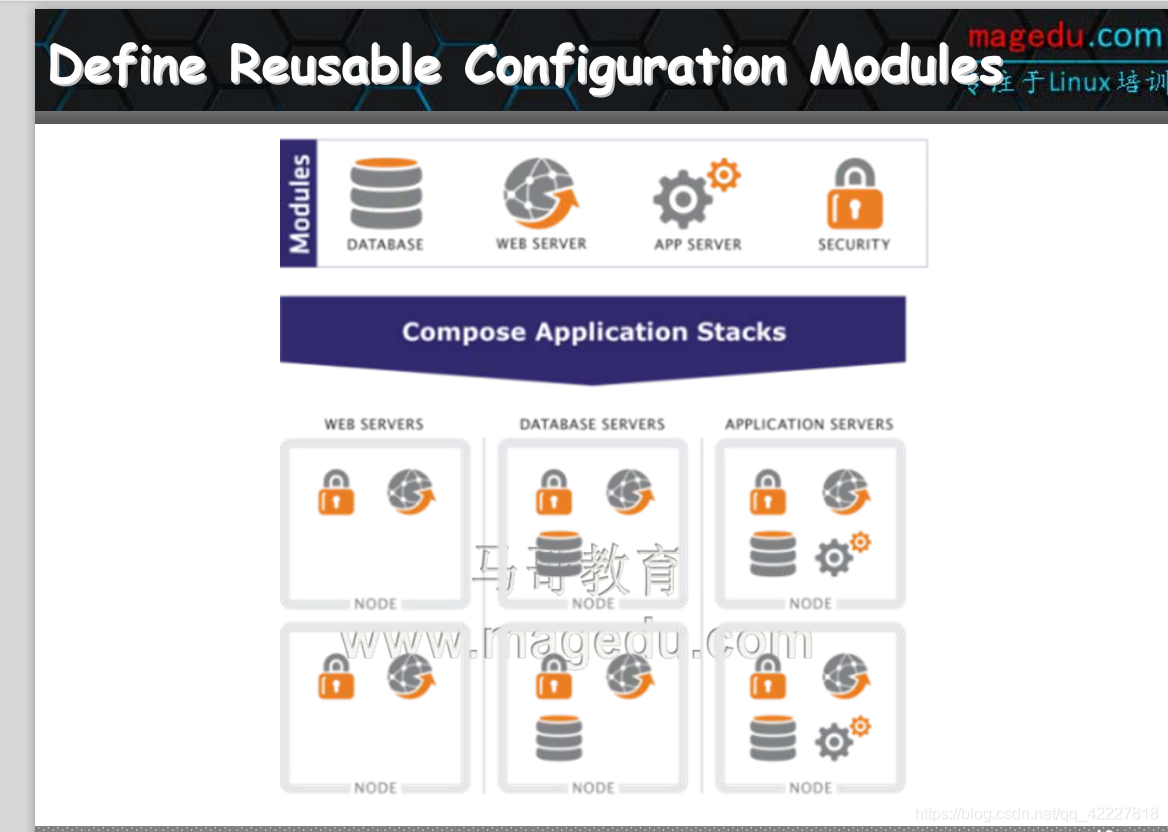
puppet如何工作,开发一个模块,分别描述每一种服务,模块,不仅是一个资源,一个模块是一堆资源的集合,比如要开发一个nginx模块,(应该装程序包,提供配置文件,启动服务,结合起来才叫一个模块),定义好模块后,可以把主机分配角色,而后让每一个主机调用合适的模块即可
第一个主机叫web services(需要安全模块和web服务模块)、
第二个database services (需要数据库 web服务模块和安全模块)
所以就4个模块,可以快速配置6个主机
puppet如何工作

puppet是属于master agent模型的,可以想成有一个主控主机(服务器,在服务器上拥有配置仓库,这个配置模块都在里面,配置模块有多少个,每一个主机调用哪些模块都在这里面定义,这个仓库所拥有的服务,通过master自己的套接字服务端口,输出出去,每一个被管控的主机,
配置好后,会自己请求查找自己相关的配置,每个主机都有自己相关的配置,所以master端,会根据请求的主机名,查找与这个主机单独相关的配置,而不是所有的配置,只是它的相关的配置,把配置结果再发送给主机,由这个主机来确定,自行,由agent来验证,对方发过来的目标配置,和已有的配置是不是一致,)通信时基于http协议来完成,但是http并不安全,因为是明文的,而这个配置有可能会包含一些隐藏信息,所以就可以用https
意味着,双方是互相认证的, 客户端服务端都需要互相认证。用的是XMLRPC,基于xml的远程调用的api逻辑来实现,可以想的简单点,在服务端其实就是一个web服务器,输出的接口也是http协议,客户端通过http协议,发起请求,对方用http协议进行响应,包含的不是网页而是puppet的信息数据,这个数据交换是用xml语言格式来进行描述的,所以不能通过浏览器来查看。
根据主机名配置,有可能会造成泄露的,随便弄个虚拟机,取个一样的主机名,一连接服务端,服务端就把配置发过来了,所以这里需要认证的,双向认证,服务端要认证客户端证书,客户端要认证服务端证书
初始化可能需要扔介入查看证书申请是否正确
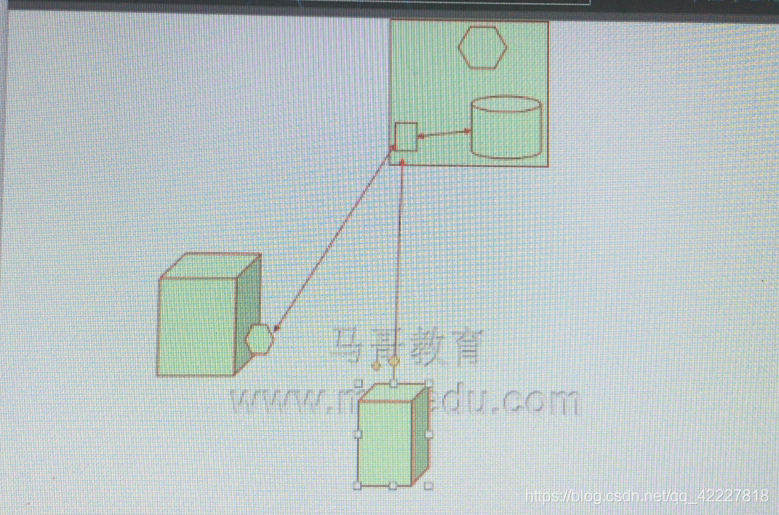
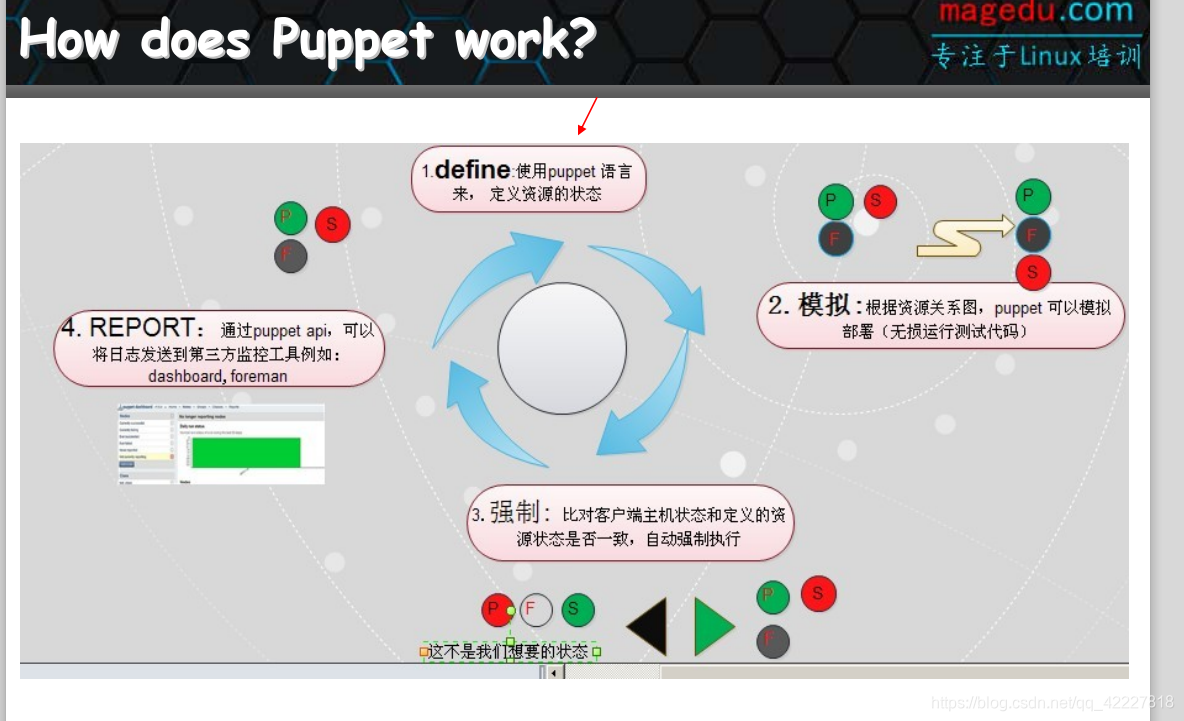
这就是puppet的工作模式,puppet 工作过程大致分成4个阶段
1.定义,开发主机配置,把目标主机的状态定义好,使用puppet配置资源的语言
2.定义好如果直接请求主机跑一遍,可能把主机跑坏了,所以有一个过程模拟,无损运行测试
3.模拟后,发现没有冲突问题,就真正开始配置了,强制执行
4.应用完如果成功了,就报告成功,没有成功就报告失败
puppet有一些自带的前端工具,dashboard,foreman,用它报告结果,用图形界面展示出来的工具

puppet为了实现定义,应用了三层模型
1.资源抽象层 resource abstraction layer(做配置人员来讲,写代码无须关心,不同系统的nginx配置文件语法都是一样的,资源和资源有依赖关系)
2.transactional layer 事务层(需要在这里描述资源间的依赖关系)
3.configuration language 配置语言

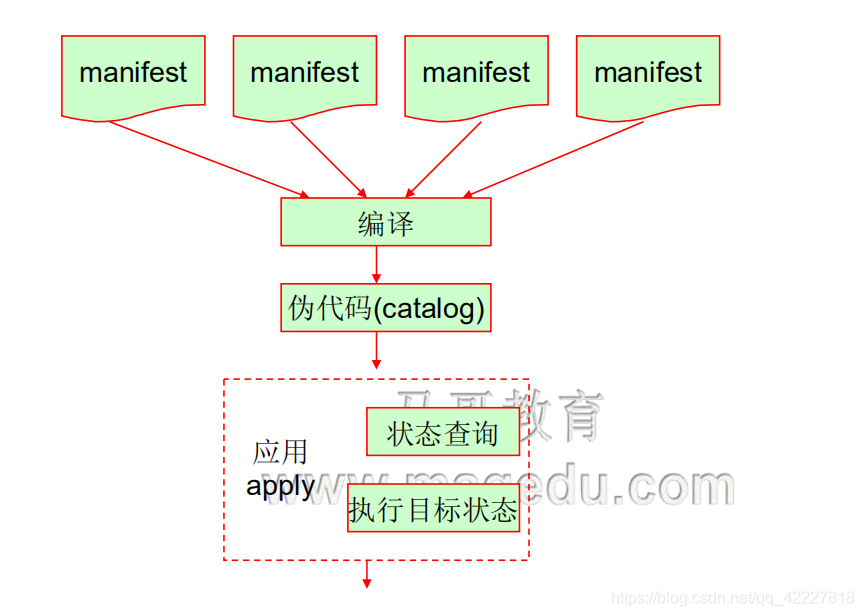
真正要完成配置,就需要用它的配置语言来写配置,配置跟编程一样,放在一个文本文件中,在第一个配置文件中,写目标状态,资源类型
资源定义好了,放一个文件叫资源清单,manifest清单,代表一个又一个的资源清单,
一个主机是可以应用多个模块的,每一个模块都有可能有一个清单,所以一个主机真正应用时,清单文件可能不止一个,所以要用清单的时候,要把所有主机的清单都拿过来做分析,分析完以后开始做编译,编译成伪二进制格式,,伪代码,只能在puppet引擎上运行,可以理解为在puppet虚拟机上运行,因此叫伪代码,catalog
编译完以后,有两个步骤,先尝试干跑一遍行不行,模拟,没问题,就强制执行,执行完了再报告
这只是在agent端单机模型用的逻辑
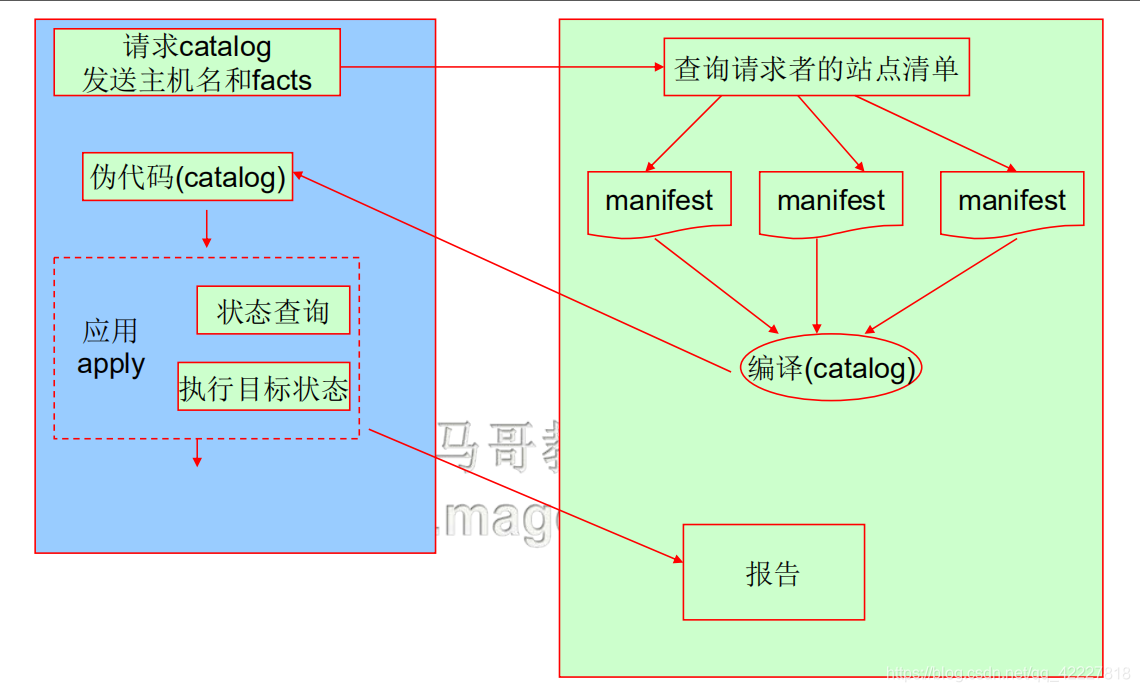
puppet是master agent模型,所有配置在master端,(右侧master,左侧agent,所以agent周期性地发请求,)
一个客户端主机称为agent,需要应用目标配置时,向master端发送请求,发请求的同时,会发送自己的主机名同时还要发送主机的facts(ansible有个facts)主机级别的变量,
服务端根据主机名查找与它相关的配置,而这个主机有定义调用多个模块,因此把这个主机调用的模块的资源清单,都需要拿来做编译,在服务端要编译好,编译好以后,把内容发送给agent,agent在本地模拟,强制,最后报告
这就是真正意义上master agent的工作逻辑
其实puppet可以运行于两种模型的
第一,standalone 单机模型(自己在一台主机上,自己定义自己的配置,用于当前的一台主机,只打算在本机 运用),就没必要运行服务了
(puppet apply 直接跑清单(自己开发自己跑)
puppet agent 去联系server端 -》server 到server端请求相关配置 (服务端开发,让各agent请求跑)
)
第二agent /master 主从模型
最主要的就是开发
node4当做puppet master node3

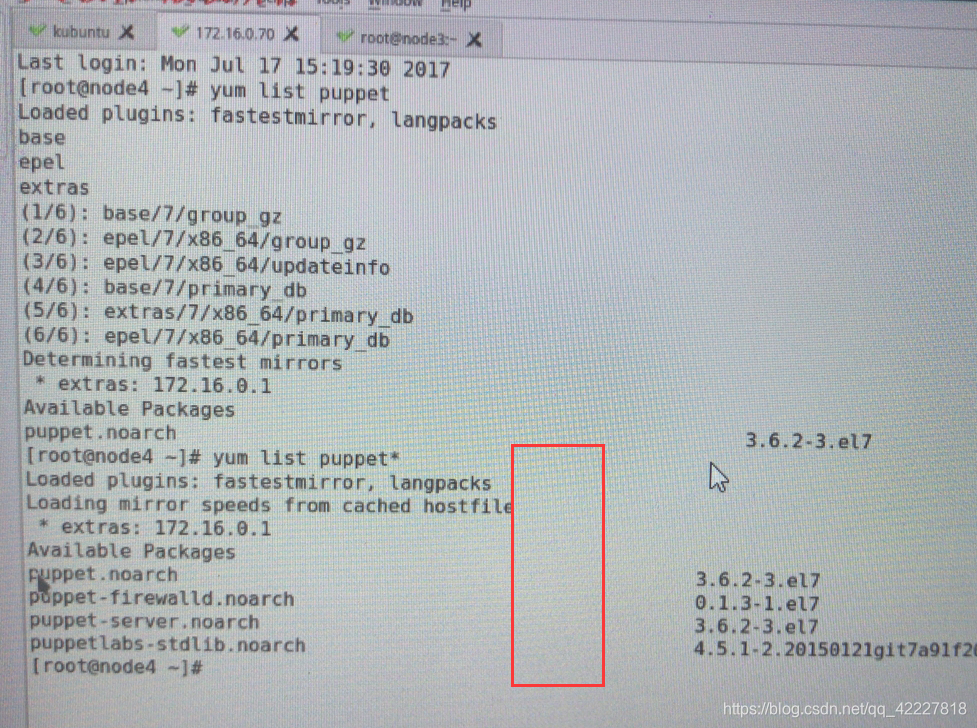
puppert是个成熟的项目,基本上各个版本都有相应的程序包,epel仓库种就有
puppet牵线木偶
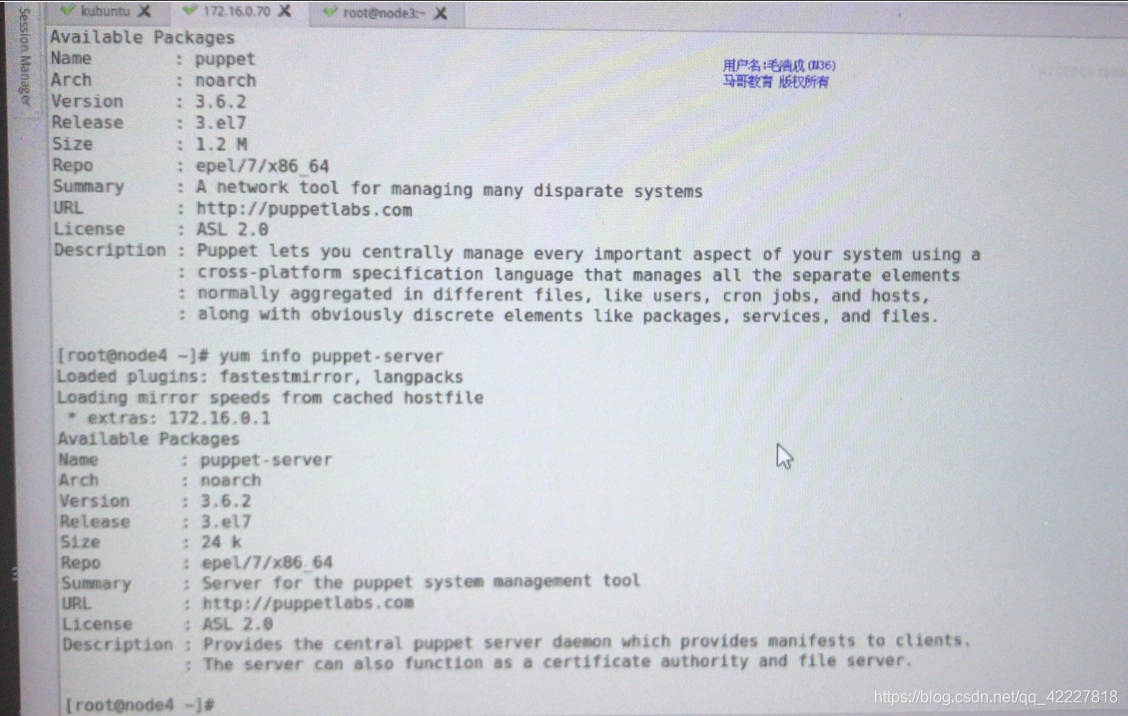
puppet server只是能配置成服务器运行的一个包
puppet,把所有功能都整合到一个大程序中,这个程序有很多子命令,子命令是master就扮成master端,agent就扮成server端,升级成master的时候,使用
现在我们只需要puppet即可
facter是报告本地facts的,系统级变量发生给master端使用的
如果本地只允许为agent,server可以先不用安装

puppet的工作模型:
单机模型:手动应用清单;
master/agent:由agent周期性地向Master请求清单并自动应用于本地;
单机模型:
程序环境:
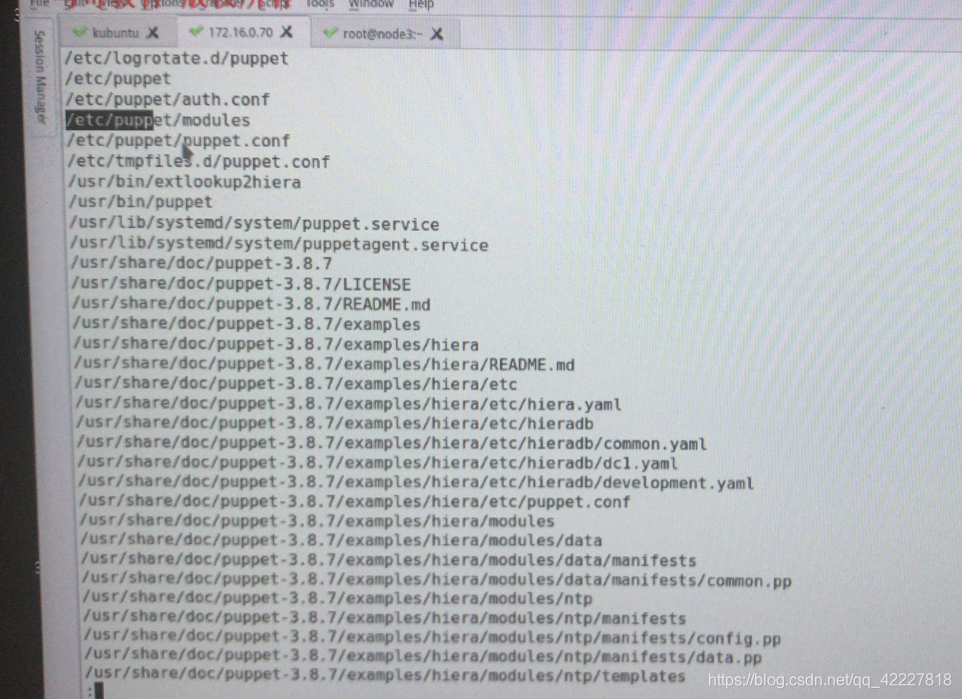
配置文件:/etc/puppet/
puppet.conf
主程序:/usr/bin/puppet
使用格式,puppet +子命令(子命令可能还有选项action还有各种选项,)
单机跑,写一个本地应用叫apply
agent是agent
master是master


资源清单直接本地跑一遍

描述内部支持的各种资源类型

master主动触发客户端运行的

管理模块的

管理插件的

跟报告相关的

查看服务端相关状态的

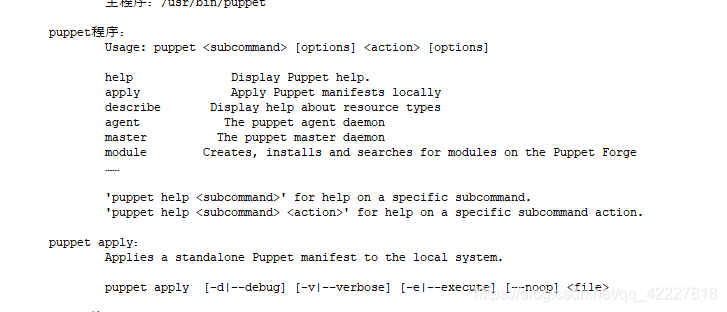
puppet程序:
Usage: puppet [options] [options]
help Display Puppet help.
apply Apply Puppet manifests locally
describe Display help about resource types
agent The puppet agent daemon
master The puppet master daemon
module Creates, installs and searches for modules on the Puppet Forge
……
'puppet help <subcommand>' for help on a specific subcommand.
'puppet help <subcommand> <action>' for help on a specific subcommand action.
最需要了解 puppet apply:
Applies a standalone Puppet manifest to the local system.(把资源清单在本地直接应用)
**puppet apply [-d|--debug] [-v|--verbose] [-e|--execute] [--noop(干跑,测试的模式)] <file>**
进入关键步骤,需要写文件


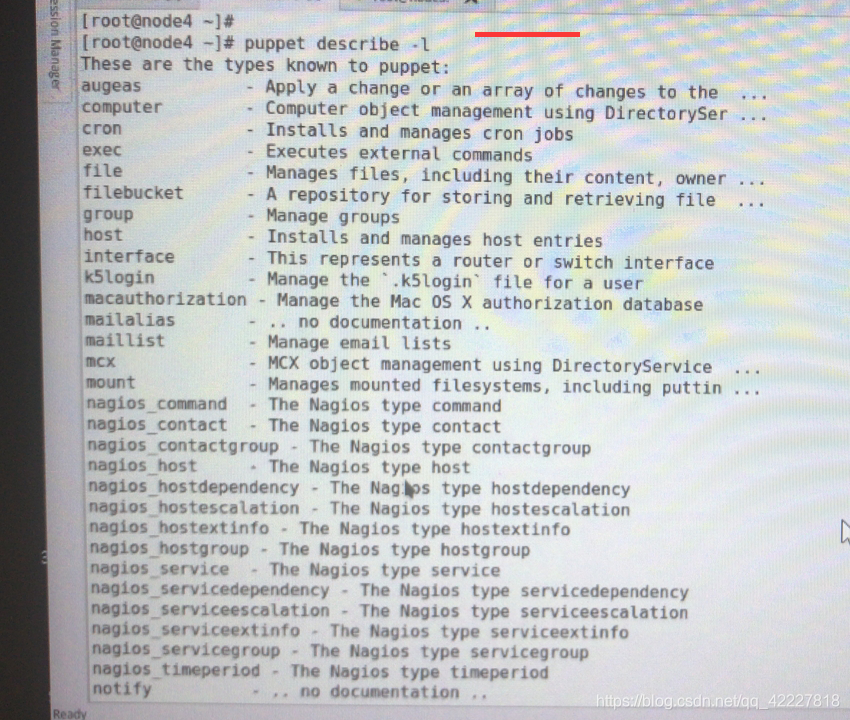
资源本身靠抽象来实现,puppet 支持多少资源可以使用puppet describe:来查看
puppet describe:
Prints help about Puppet resource types, providers, and metaparameters.
**puppet describe [-h|--help] [-s|--short] [-p|--providers] [-l|--list] [-m|--meta] [type]
-l:列出所有资源类型;
-s:显示指定类型的简要帮助信息;
-m:显示指定类型的元参数,一般与-s一同使用;**
几十种资源类型
查看单个清单如何定义、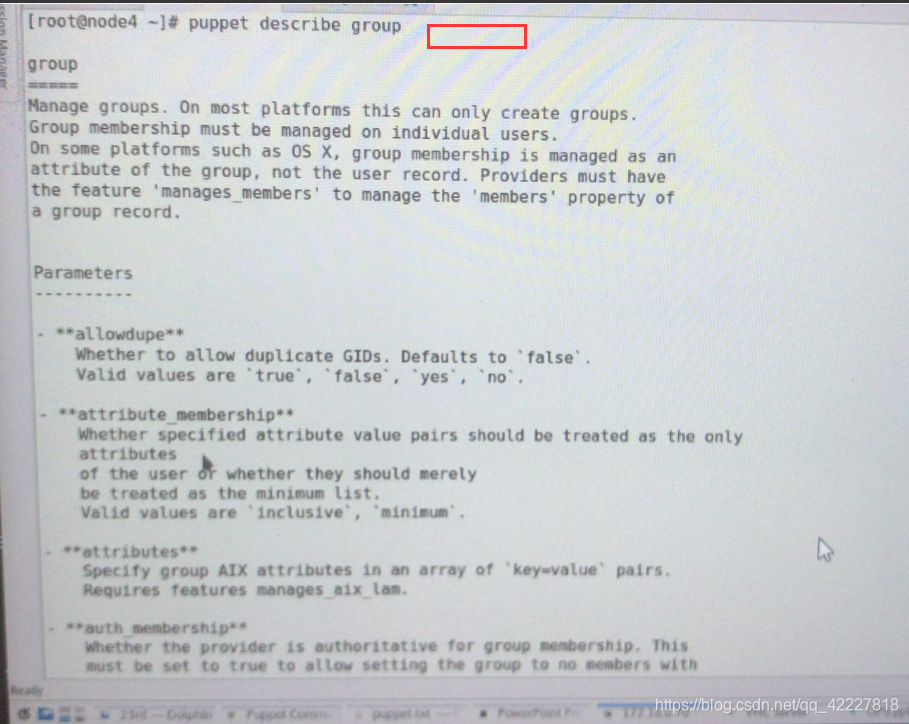 资源类型:
资源类型:
group:
Manage groups.
属性:
name:组名;
gid:GID;
system:是否为系统组,true OR false;
ensure:目标状态,present/absent(这个组必须删除);
members:内部成员用户;
system:是否是系统组 ture/false(id号<1000否则>1000)
定义资源,在清单中定义即可
 资源定义:向资源类型的属性赋值来实现,可称为资源类型实例化;
资源定义:向资源类型的属性赋值来实现,可称为资源类型实例化;
定义了资源实例的文件即清单,manifest(清单);
定义资源的语法:
(类型) type {‘title’:(标识,组有多个,需要区分,title一般是你组的名字,唯一标识)
attribute1 => value1,属性1
atrribute2 => value2,属性2
……
}
注意:type必须使用小写字符;title是一个字符串,在同一类型中必须惟一(组类型名字不能相同,同一类型名字不能相同);
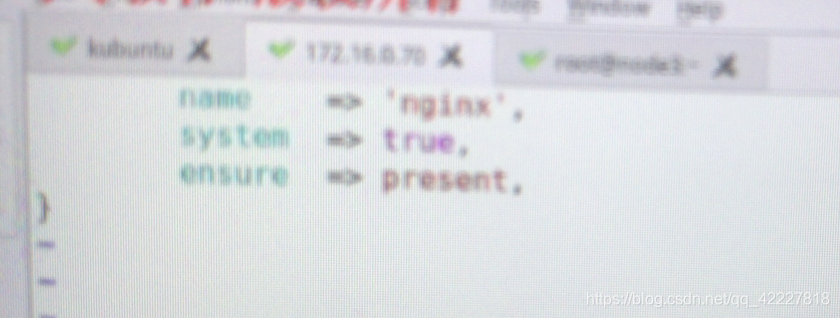
进行简单示例,puppet的资源清单一般后缀是.pp
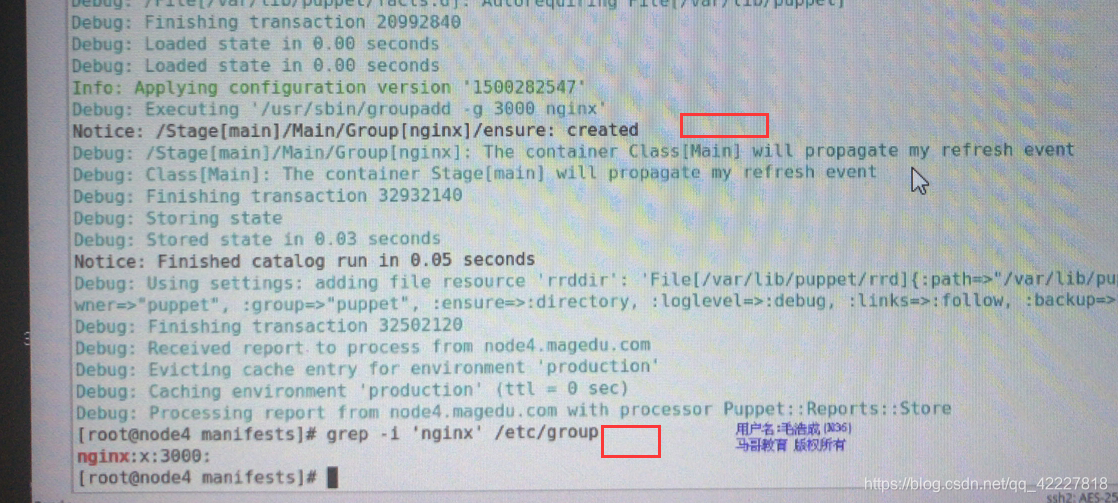
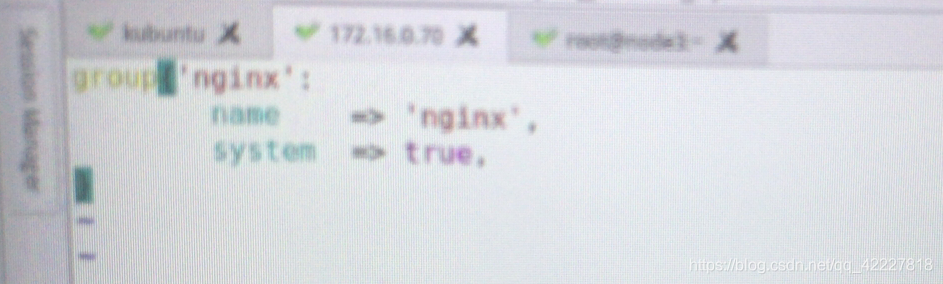
组名nginx ,冒号隔开
属性1 name=>赋值 'nginx’逗号分开
system=> true , 是否系统组
}
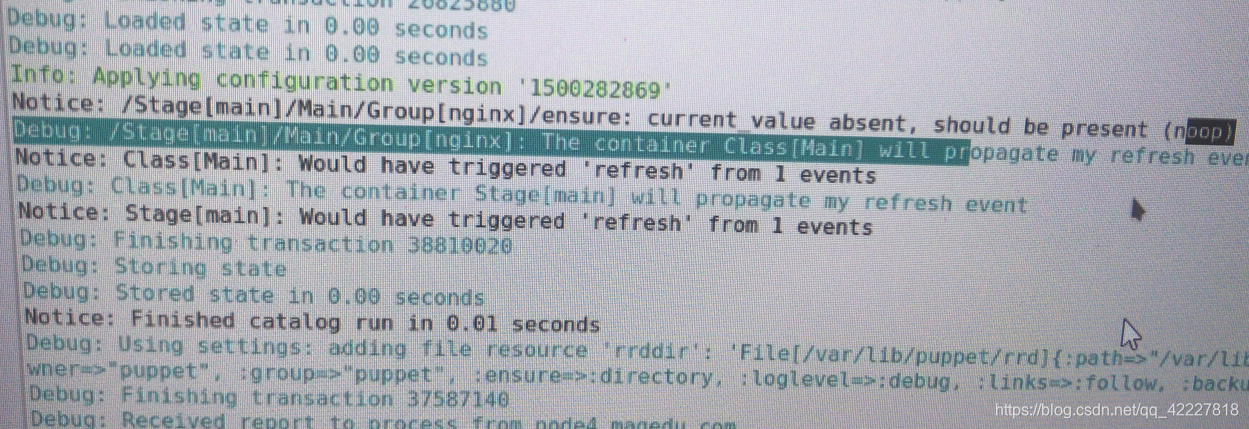
 使用puppet apply可以执行一遍了,–verbose 做测试 -noop 不真的执行
使用puppet apply可以执行一遍了,–verbose 做测试 -noop 不真的执行
编译这个清单文件,大概多少时间完成
绿色表示没有问题
state.yaml 目标状态的信息



当前组id是1000,现在是2000,已经有这个组
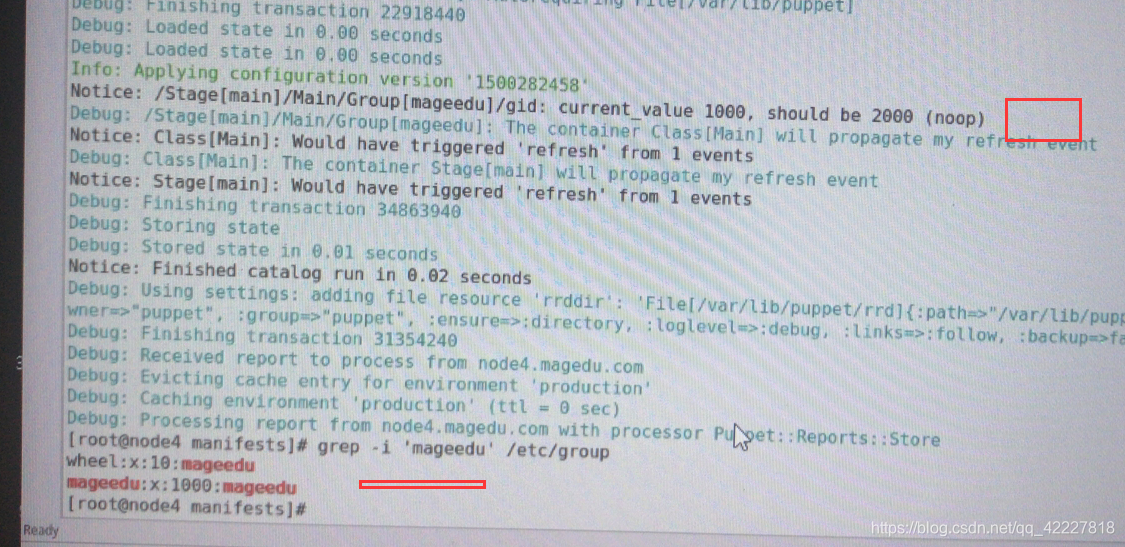
强行跑一遍,测试能否改成2000
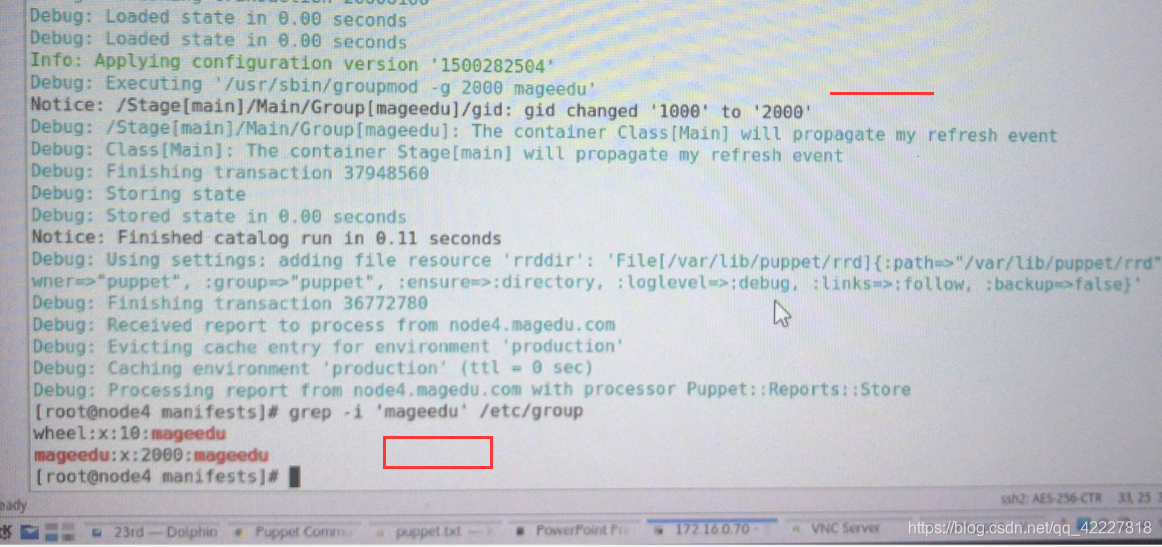
已经从1000改到了2000

改成nginx试试
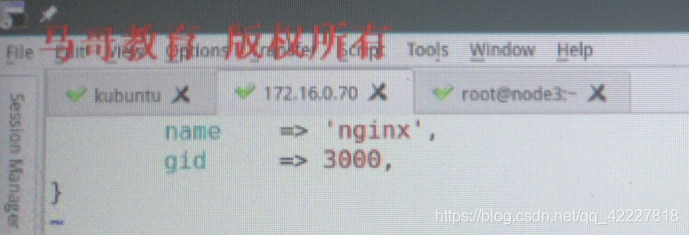

现在就创建好了
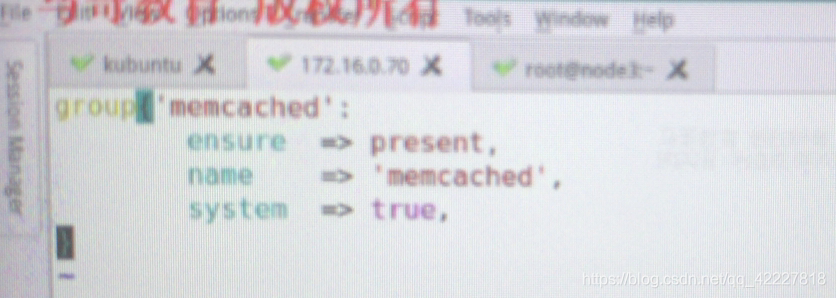
vim second.pp
再写一个,非常的关键词 ensure presen 表示必须要创建出来,任何一个资源类型都需要ensure属性,确保目标状态是否存在
system =true

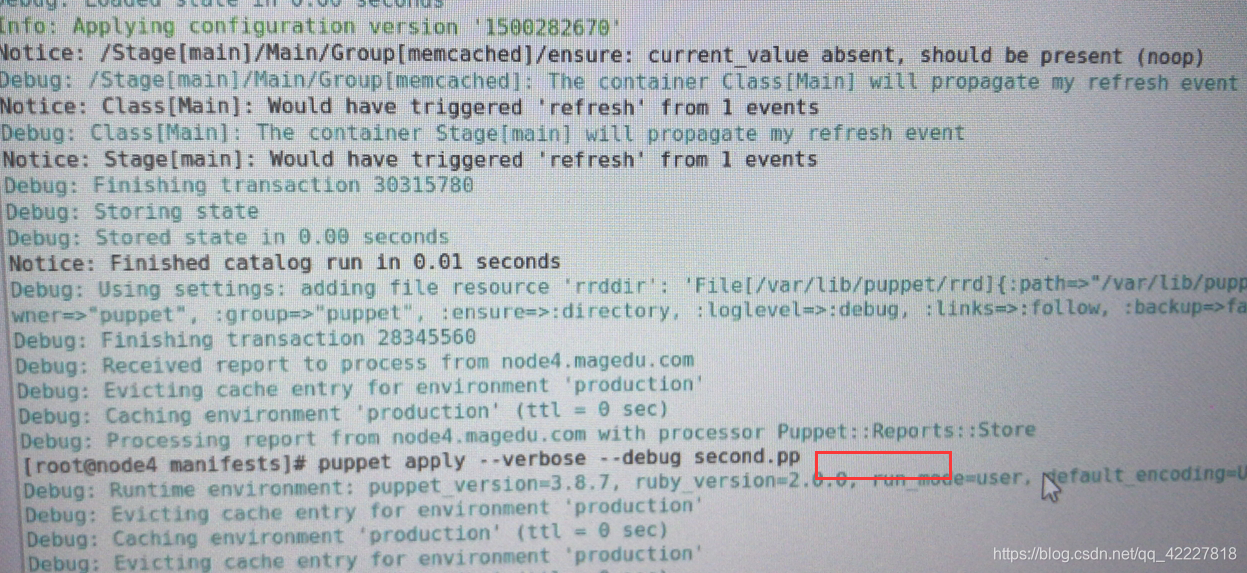
真实跑一遍

干跑一遍试试

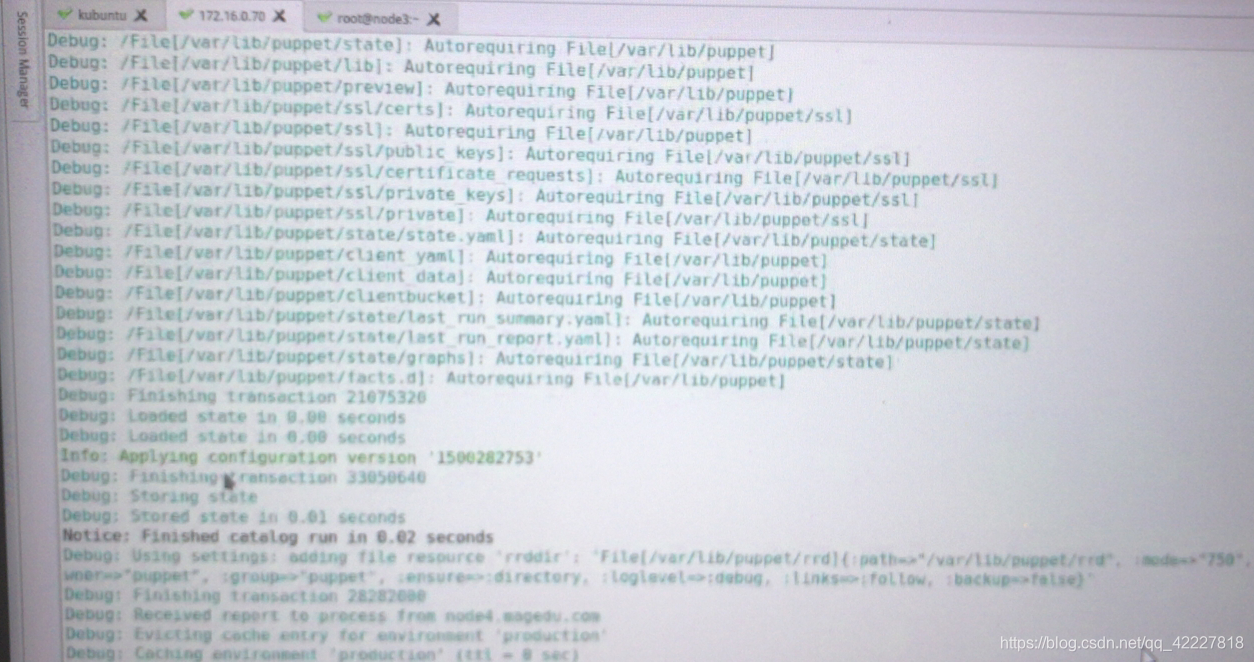
创建了却看不见,有可能是ensure导致的
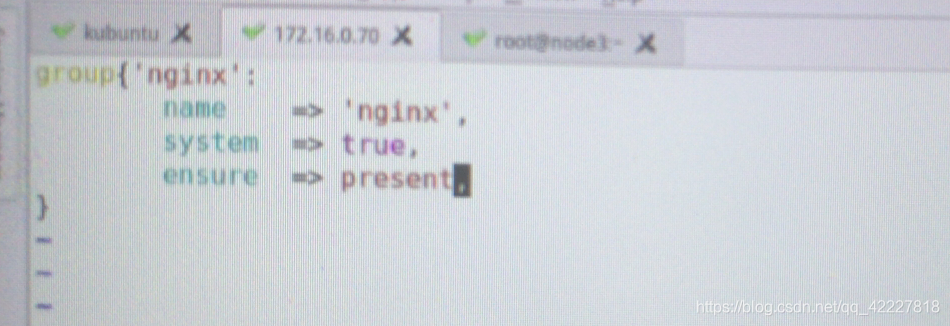

还是提示已经拥有

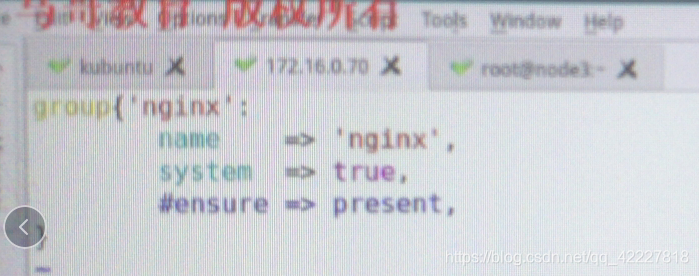

系统组,什么也不干
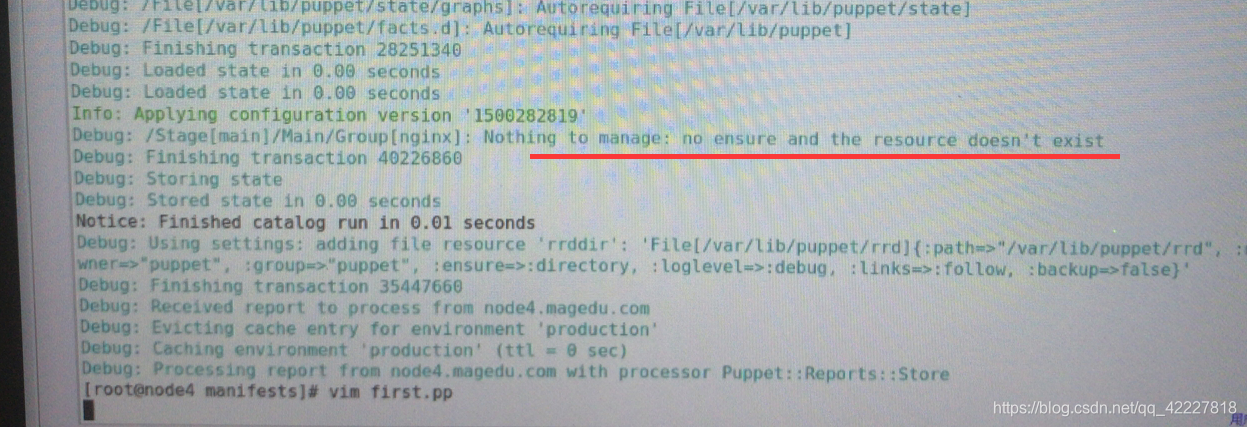
取消注释,系统组必须加上ensure,普通组就不用
这个选项必须给