这是作者的系列网络安全自学教程,主要是关于网安工具和实践操作的在线笔记,特分享出来与博友共勉,希望您们喜欢,一起进步。上一篇文章分享了OllyDbg动态分析工具的基础用法,并简单讲解两个Crakeme逆向工程破解实战方法;本篇文章将介绍Chrome浏览器的Network功能,并解析下载快手视频,同时分享了一个Python解析Network链接的难题。希望对初学者有帮助,大神请飘过,谢谢各位看官!
PS:作为初学者,深知网络安全这块要学习的知识太多,希望自己能始终保持满腔热情,科研结合实践慢慢前行。
前文学习:
[网络安全自学篇] 一.入门笔记之看雪Web安全学习及异或解密示例
[网络安全自学篇] 二.Chrome浏览器保留密码功能渗透解析及登录加密入门笔记
[网络安全自学篇] 三.Burp Suite工具安装配置、Proxy基础用法及暴库示例
[网络安全自学篇] 四.实验吧CTF实战之WEB渗透和隐写术解密
[网络安全自学篇] 五.IDA Pro反汇编工具初识及逆向工程解密实战
[网络安全自学篇] 六.OllyDbg动态分析工具基础用法及Crakeme逆向破解
前文欣赏:
[渗透&攻防] 一.从数据库原理学习网络攻防及防止SQL注入
[渗透&攻防] 二.SQL MAP工具从零解读数据库及基础用法
[渗透&攻防] 三.数据库之差异备份及Caidao利器
[渗透&攻防] 四.详解MySQL数据库攻防及Fiddler神器分析数据包
一.快手视频网站解析
虽然作者不玩快手和抖音,但作为网安方向的新人,总想把这些视频下载到本地。本篇文章主要利用Chrome浏览器和Python简单分析快手视频如何下载到本地。
第一步: 将需要下载的视频分享到QQ,将得到如下链接,通过浏览器打开如下图所示。
首页推荐的某主播视频:http://zhaotong.m.chenzhongtech.com/s/yQ0cCf77
第二步: 它会重定向跳转到一个新的网址,该网址才是我们需要分析的目标页面,比如下面的三个视频链接。
我们可以猜测出网址基本的构成为:
https://live.kuaishou.com/u + 用户ID + 视频ID + ?did= + 一串密钥
https://live.kuaishou.com/u/3xhese5im6yksx6/3xa7v5aze84kirg?did=web_3e7228e2fb25419eae1bc7a0eb29bbde
https://live.kuaishou.com/u/3xhese5im6yksx6/3xg6v9usfdnkuf9?did=web_3e7228e2fb25419eae1bc7a0eb29bbde
https://live.kuaishou.com/u/3xhese5im6yksx6/3xvgazhxasseuye?did=web_3e7228e2fb25419eae1bc7a0eb29bbde
注意,如果我们省略后面的did值,它会自动补充该值并正确访问的,如:
https://live.kuaishou.com/u/3xhese5im6yksx6/3xa7v5aze84kirg
第三步: 下面是视频hot页面,通过Chrome浏览器打开,并按下F12(或右键“检查”)可以查看源代码。在Network页面下,点击XHR,再刷新一次页面,点击“graphql”可以看到Json数据,这次终于确定我们之前的猜想,链接有“主播ID”(id)和“视频ID”(photoId)组成。
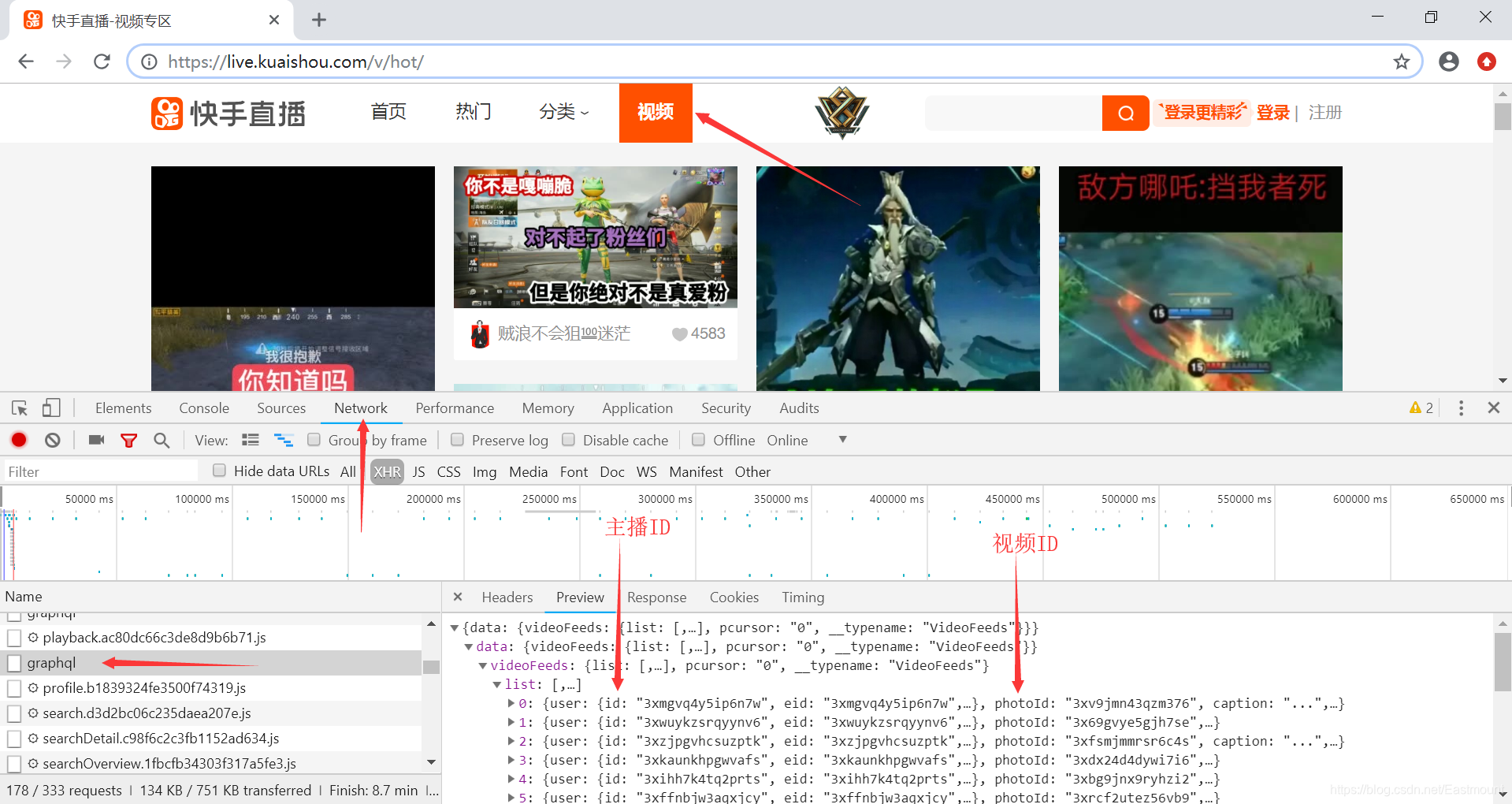
其中某个视频信息如下:

第四步: 我们尝试拼接下链接,确实能够正确访问,如下图所示。接着我们将简单分析如何下载视频至本地。
id: 3xwuykzsrqyynv6
photoId: 3x69gvye5gjh7se
https://live.kuaishou.com/u/3xwuykzsrqyynv6/3x69gvye5gjh7se
二.Chrome浏览器Network分析
第一步: 还是以这个视频为例,我们按下F12键(或右键“检查”),刷新页面,点击Network。
首页推荐的某主播视频:https://live.kuaishou.com/u/3xhese5im6yksx6/3xa7v5aze84kirg
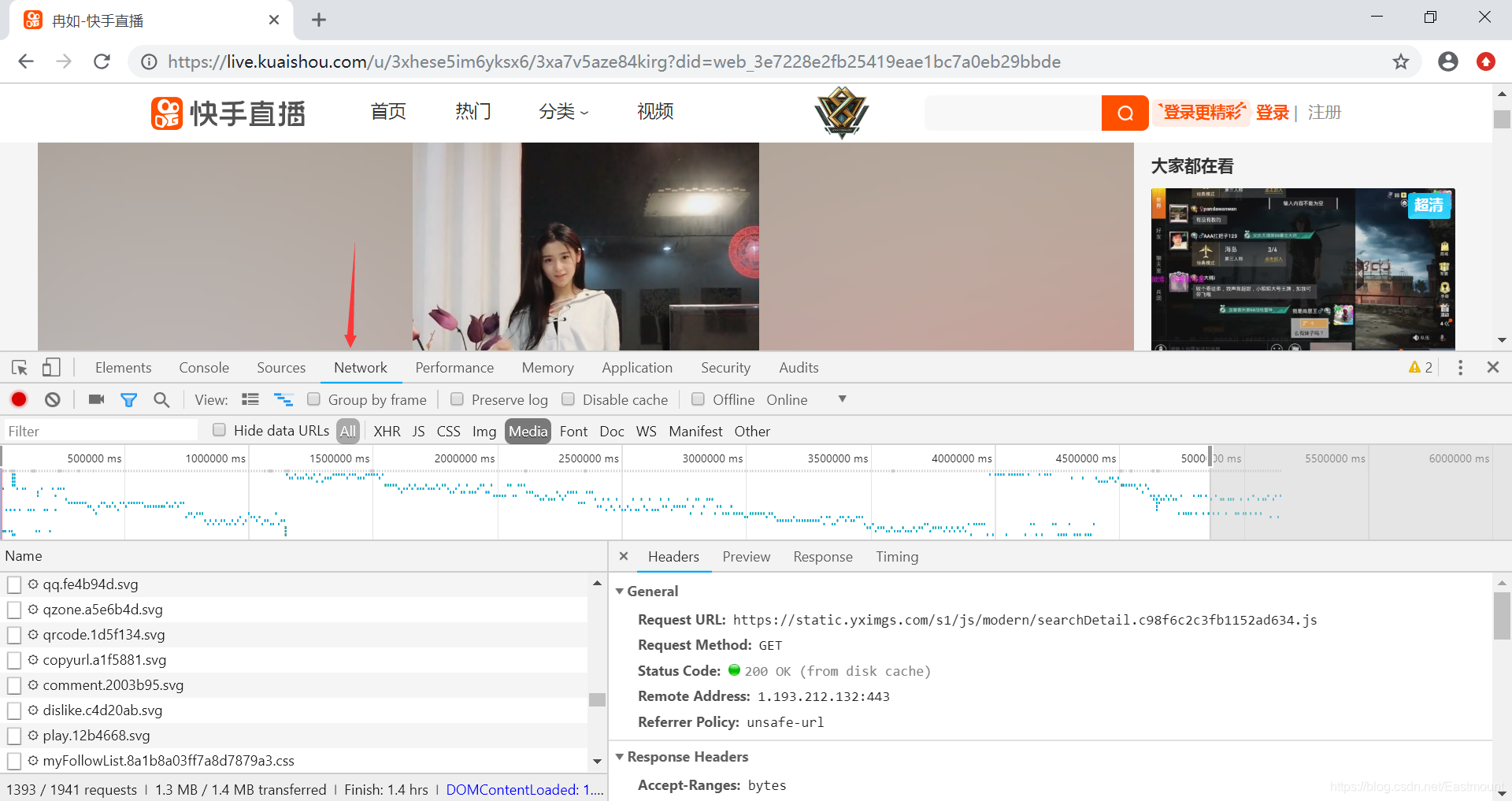
第二步: 在“ALL”中找到有一个“mp4”结尾的文件,即为要下载的视频文件,点击“Headers”查看对应视频地址。注意,视频执行过程中,尽量点击下暂停,否则会跳转到下一个视频。
Request URL: https://jsmov2.a.yximgs.com/bs2/newWatermark/NjUzODIwODM5OA_zh_4.mp4
Request Method: GET
Status Code: 206 Partial Content
Remote Address: 61.240.28.1:443
Referrer Policy: unsafe-url
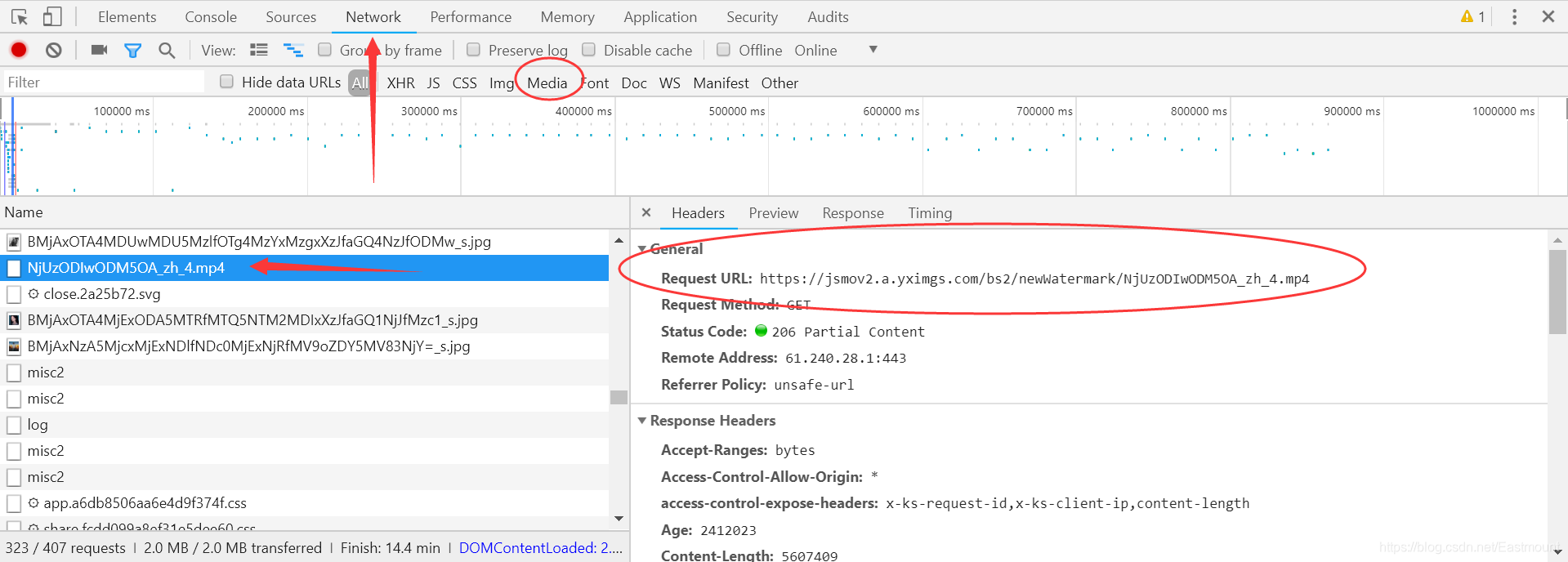
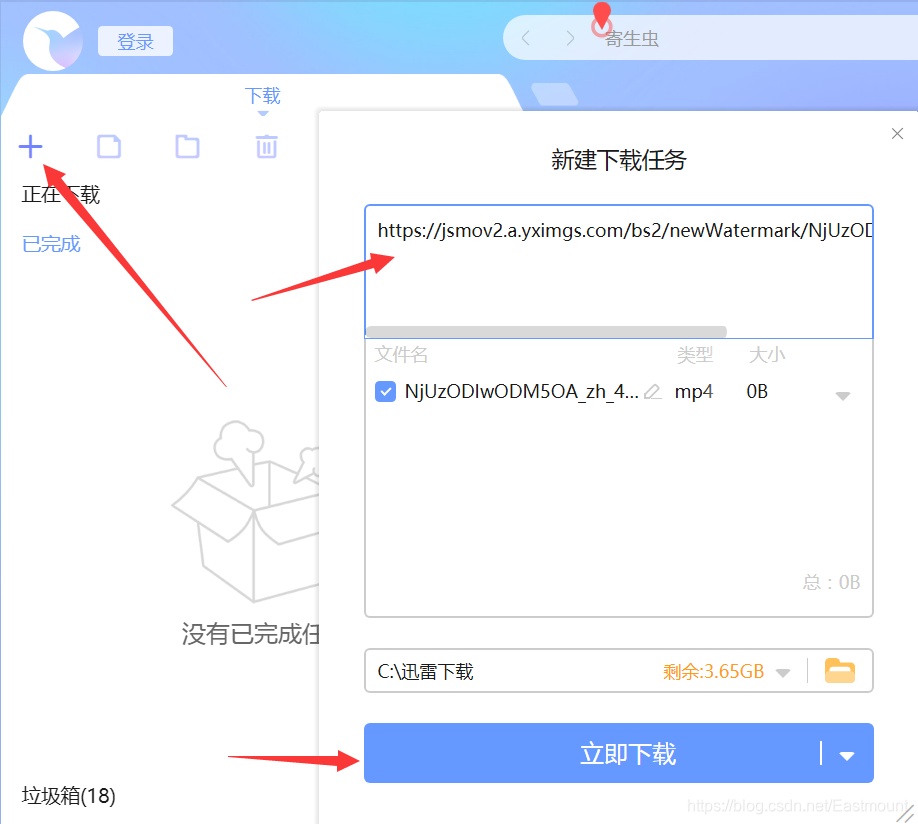
第三步: 打开迅雷,将复制的视频网址添加到“新建下载任务”中,下载该视频。
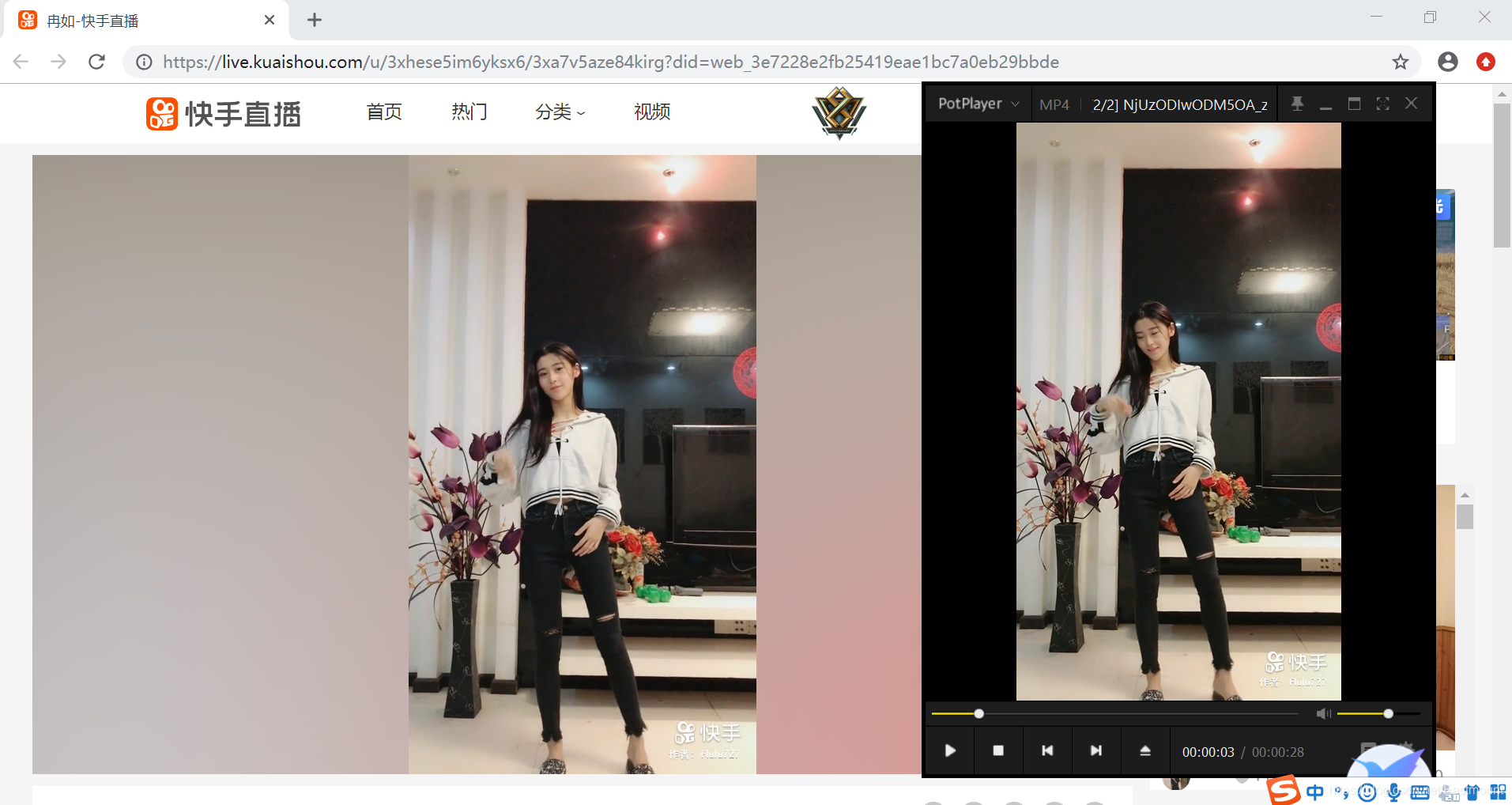
第四步: 视频成功下载至本地,打开即可。
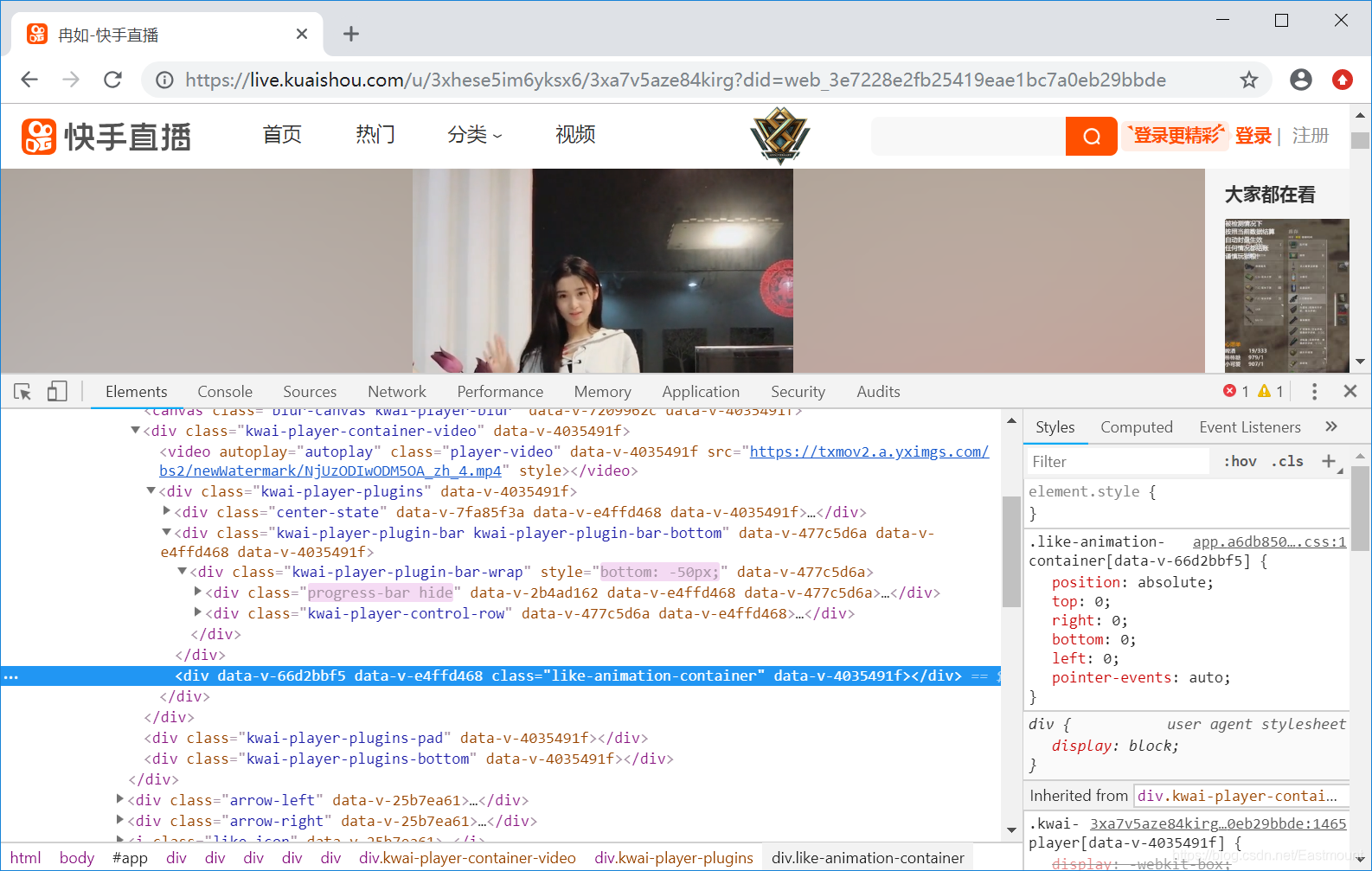
你可能会想:
能不能直接分析HTML源代码,从中定位视频的链接。不行了,视频是动态加载的,我能想到的方法是通过Python获取Network中的所有资源,再定位“mp4”对应的超链接,但最终还是没解决,后续部分将详细探讨。
三.Python下载视频
Tqdm是Python进度条库,可以在Python长循环中添加一个进度提示信息用法:tqdm(iterator)。
示例代码:
# -*- coding: utf-8 -*-
import time
from tqdm import tqdm
for i in tqdm(range(100)):
time.sleep(0.01)
#设置描述
pbar = tqdm(["a", "b", "c", "d"])
for char in pbar:
# 设置描述
pbar.set_description("Processing %s" % char)
time.sleep(1)
输出结果如下图所示:
0%| | 0/4 [00:00<?, ?it/s]
Processing a: 25%|██▌ | 1/4 [00:01<00:03, 1.00it/s]
Processing b: 50%|█████ | 2/4 [00:02<00:02, 1.00it/s]
Processing c: 75%|███████▌ | 3/4 [00:03<00:01, 1.00it/s]
Processing d: 100%|██████████| 4/4 [00:04<00:00, 1.00it/s]
下面讲述一段代码,将视频下载至本地。
# coding=utf-8
import json
import requests
import tqdm
#定义函数下载视频
def saveMp4(url, filename):
res = requests.get(url, stream=True)
file_size = int(res.headers['Content-Length'])
num = 1
num_size = 1024
num_bars = int(file_size / num_size)
with open(filename, 'wb') as fp:
for num in tqdm.tqdm(
res.iter_content(chunk_size = num_size),
total = num_bars,
unit = 'KB',
desc = filename,
leave = True
):
fp.write(num)
#调用函数
url = "https://jsmov2.a.yximgs.com/bs2/newWatermark/MTQ5Mzk2MzMwMDg_zh_4.mp4"
filename = "test.mp4"
saveMp4(url, filename)
如下图所示:

如果读者想下载快手某位主播的所有视频,则可以点击它的个人主页,如下图所示。
主播的主页:https://live.kuaishou.com/profile/Flulu727
写到这里,你可能会想能不能写个爬虫将所有网页链接中“mp4”对应的地址抓取下来,再进行统一爬取。下面我们来简单进行分析,但最终结果失败了!
四.Python自动化抓取视频讨论
网络查找很多获取Network中所有网络请求URL、获取XHR的response结果,均没有一个有效的答案,包括github的代码。比如:
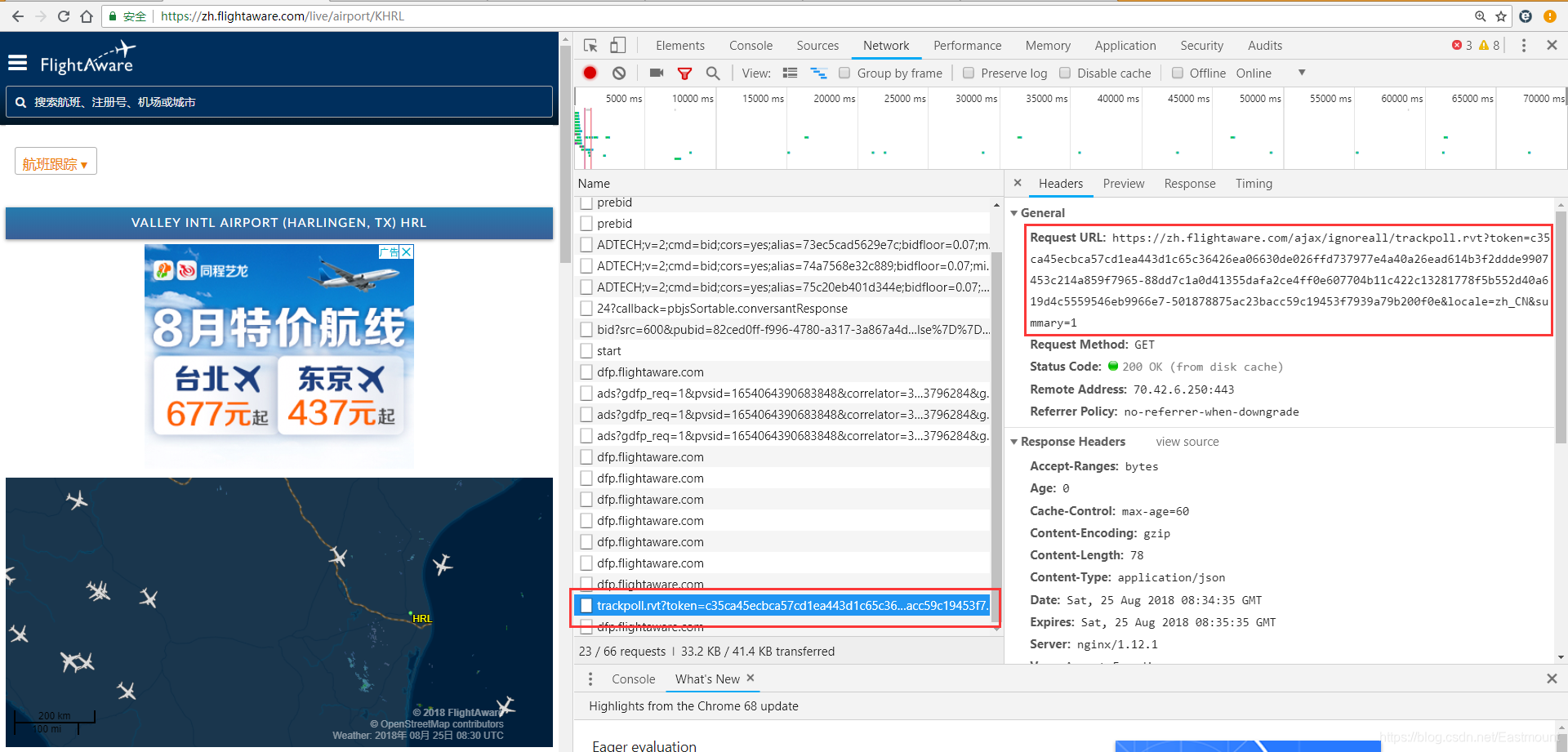
下面进行一些探讨,我首先想到的方法包括两个基本操作,即:
1.设置消息头headers和请求的参数data,调用requests()函数请求连接,注意该视频是GET方法。
Request URL: https://txmov2.a.yximgs.com/bs2/newWatermark/NjUzODIwODM5OA_zh_4.mp4
Request Method: GET
Status Code: 206 Partial Content
Remote Address: 116.207.112.100:443
Referrer Policy: unsafe-url
2.返回的数据调用json.load()函数进行解析,并且获取指定的字段。
# -*- coding: utf-8 -*-
import json
data = {
'id' : 1,
'name' : 'test1',
'age' : '1'
}
data2 = [{
'id' : 1,
'name' : 'test1',
'age' : '1'
},{
'id' : 2,
'name' : 'test2',
'age' : '2'
}]
#python字典类型转换为json对象
json_str = json.dumps(data)
print(u"python原始数据:")
print(repr(data))
print (u"json对象:")
print(json_str)
print("")
json_str2 = json.dumps(data2)
print (u"python原始数据:")
print(repr(data2))
print (u"json对象:")
print(json_str2)
print("")
# 将json对象转换为python字典
data3 = json.loads(json_str)
print(data3)
print("data3['name']: ", data3['name'])
print("data3['age']: ", data3['age'])
输出结果如下图所示:

下面开始简单的尝试:
第一步:调用requests获取数据
# coding=utf-8
import json
import requests
from pyquery import PyQuery as pq
#设置请求
ID = "3xrptqgjk98rism"
photoID = "3xw28sc864d8p2e"
URL = 'https://live.kuaishou.com/u/'+ID+'/'+photoID
print URL
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'
}
#获取某个ID用户的作品photoID
res = requests.get(URL, headers=headers)
print len(res.text)
#PyQuery解析
html = pq(res.text)
print html
输出结果中最重要的是最后一个script代码。
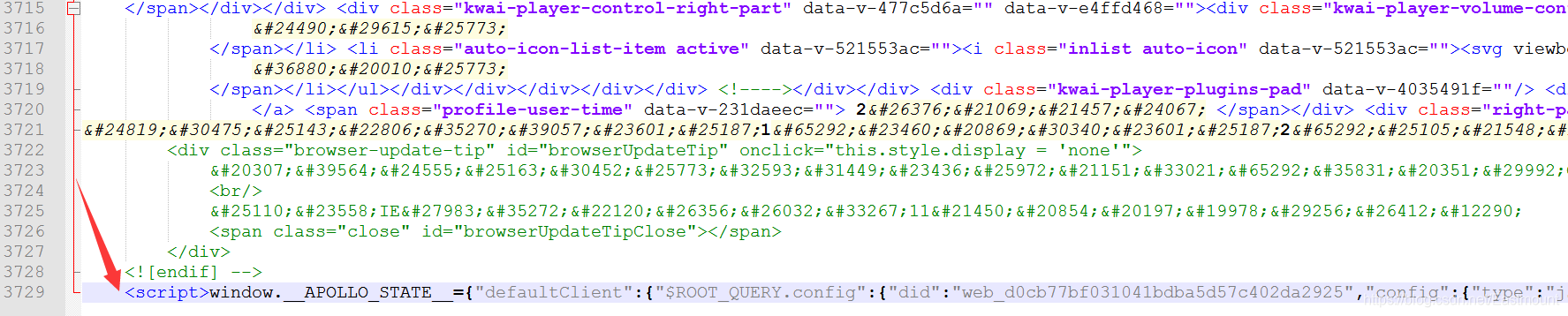
这里包含了视频URL代码。
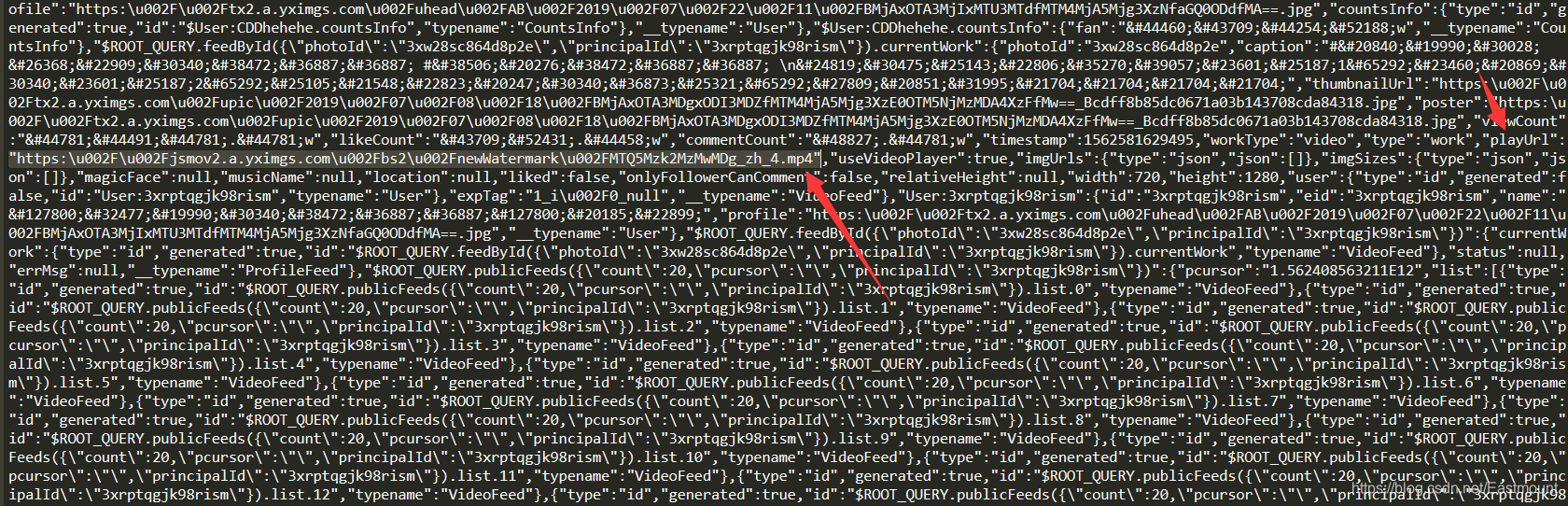

第二步:尝试用下面的代码解析Json数据并定位链接。
key = '$ROOT_QUERY.publicFeeds({"count":24,"pcursor":"","principalId":"%s"})' % ID
print key
data = json.loads(html)
print data
#获取连接及命名
play = data['data'][key]
url = play['playUrl']
vedio = play['caption']+'.mp4'
但最重要的一步是如何定位Json位置并解析。
五.总结
推荐读者阅读大神的文章,后续将学习Fiddler进行手机抓包以及代理设置。
(强推)用Python写了个下载快手视频的小脚本 - DIY
(强推)python爬虫从入门到放弃(九)之 实例爬取上海高级人民法院网开庭公告数据 -zhaof - 动态爬虫
python爬取快手视频–json数据分析 - Dream____Fly
python爬取快手视频 多线程下载 - foddler配置
Python 下载网络mp4视频资源 - dcb3688 - PyQuery获取Json参数
Python爬虫技巧-西瓜视频MP4地址获取 - 我爱学python - base64decode解密
[python] Python2.7爬虫+Fiddler 爬取快手APP的短视频 - 哈士奇的布偶 - APP代理
Chrome + Python 抓取动态网页内容 - 吹剑录
浅谈如何使用python抓取网页中的动态数据 - saintlabs
Github:
https://github.com/binglansky/spider/blob/master/kuaishou.py
https://github.com/muyangren907/Kwai_download_script
https://github.com/d1y/lovepack/blob/master/kuaishou.py
珞珞如石,温而若珈;潇洒坦荡,一生澄澈。新学期,新生活,新里程。
一个多月的闭关,深深体会到数学和英语的重要性,短板抓紧补起来,长板却没有。开学八门课,《信息论》《现代密码学》《网络安全协议》《信息安全前沿》《信息安全与可信计算》《自然语言处理》等,就NLP熟悉点,得加油了,更要静下心来去“做”、“学”、“问”。Stay hungry,Stay foolish~希望与您一起进步

(By:Eastmount 2019-09-05 下午1点 http://blog.csdn.net/eastmount/ )