文章目录
一、论文相关信息
1.论文题目
Fast R-CNN
2.论文时间
2015年
2.论文文献
3.论文源码
暂无
二、论文背景及简介
RCNN在解决目标检测任务的同时, 也留下了三个问题。
1. 训练采用multi-stage
RCNN训练步骤很多且繁琐,Fast RCNN使用single-stage training
2. 测试、训练时速度慢
RCNN要对每一个region proposal都要进行卷积,使得训练与测试速度很慢。Fast RCNN通过对整张图片进行卷积并获得region proposal在feature map的相应位置来共享feature map,而且采用大大加快了训练与测试速度
3. 训练所需空间大
RCNN中独立的分类器和回归器需要大量特征作为训练样本。 Fast RCNN通过共用深度学习网络,大大降低了存储压力。
基于VGG16的Fast RCNN算法在训练速度上比RCNN快了将近9倍,比SPPnet快大概3倍;测试速度比RCNN快了213倍,比SPPnet快了10倍。在VOC2012上的mAP在66%左右。
三、知识储备
1、ROI
ROI 即 region of interst,就是感兴趣的region proposal
2、ROI Pooling
ROI Pooling接受从卷积网络得到的feature map,以及region proposal的位置信息。在feature map上定位到region proposal的feature map,并将其转换成固定大小(超参数)的特征向量。
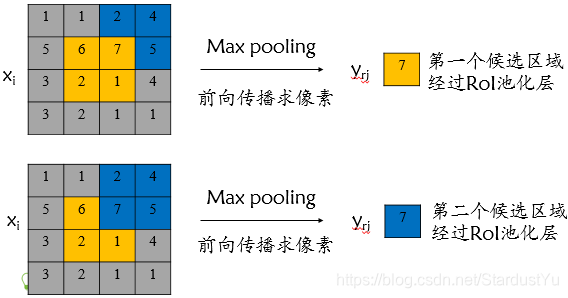
ROI Pooling前向传播过程
每一个RoI都由一个四元组(r,c,h,w)表示,其中(r,c)表示左上角,而(h,w)则代表高度和宽度。这一层使用最大池化(max pooling)将RoI区域转化成固定大小的 H*W 的特征图(H和W是取决于任何特定RoI层的超参数)。
RoI 最大池化通过将 h×w RoI窗口划分为 h / H × w / W个子窗口网格,子窗口大小固定为 H × W ,然后将每个子窗口中的值max pooling到相应的输出网格单元 。
roi_pool层将每个候选区域均匀分成 H × W 块,对每块进行max pooling。将特征图上大小不一的候选区域转变为大小统一的数据,送入下一层。
Rol pooling layer的作用主要有两个:
1.是将image中的rol定位到feature map中对应patch
2.是用一个单层的SPP layer将这个feature map patch下采样为大小固定的feature再传入全连接层。即RoI pooling layer来统一到相同的大小-> (fc)feature vector 即->提取一个固定维度的特征表示。
![]()
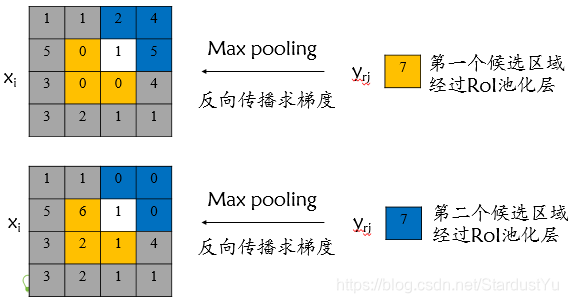
ROI Pooling反向传播过程



四、test阶段
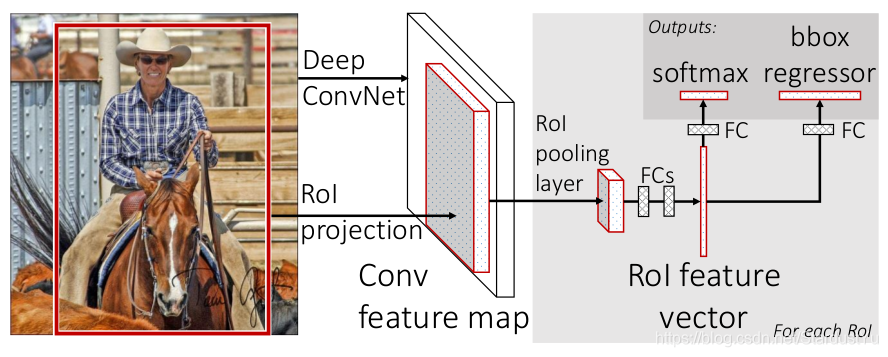
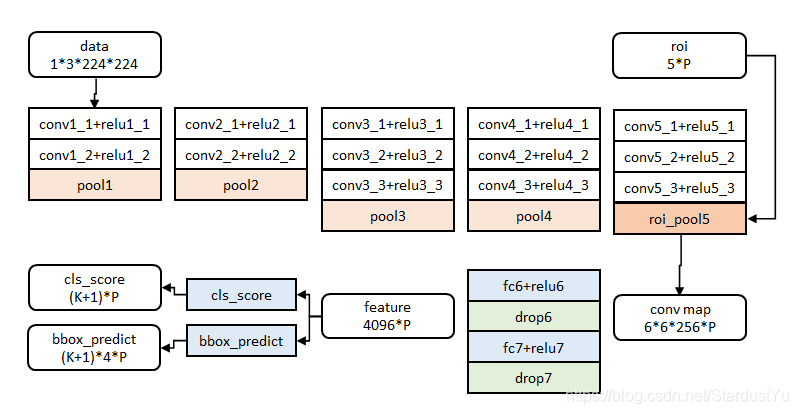
假设该模型为N分类结果,一些细节将会在下文进行介绍
- 输入一张图片
- 候选框提取:使用
selective search方法,获取该图片的ROI - 特征提取:将整张图片放入卷积网络,得到feature map
- ROI Pooling:根据feature map 以及 ROI 来进行ROI Pooling 得到固定大小的特征向量
- 分类与回归:将得到的特征向量放入fc层,将得到的feature,分别放入bbox回归分类器以及softmax分数分类器,对bbox的位置信息进行修正,并得到分类信息。
五、train阶段
根据test阶段,我们可以知道Fast RCNN将候选框提取、分类、回归修正都放在了一个网络中,使用一个Loss来对网络进行优化。其训练任务主要有:
1、对卷积网络fine tuning
2、整个网络的训练
下文将会对其原因以及细节进行讲解
1、训练样本的采样
利用训练期间的特征共享。在Fast RCNN训练中,随机梯度下降(SGD)小批量计算被分级采样,首先随机取样N张图片,然后每张图片取样 R / N 个RoIs 。关键的是,来自相同图像的RoI在向前和向后传播中共享计算和内存。
2、卷积网络的确定以及fine tuning
Fast RCNN使用了VGG作为卷积网络。作者通过实验发现对conv3以后的部分进行fine tuning更好一些。
3、整个网络Loss的确定
假设softmax输出的概率向量为p=(p1,p2·····,pn), bbox regression 输出的信息为t=(tx, ty, tw, th)。同时,假设该region proposal的类别为u(若为背景,u=0),ground-trruth 为v。Loss整合了两个分类器,最终形式为

其中
[u>=1] 表示 当u>=1 时 该值为1

注意:在regression的loss中使用了L1 loss, RCNN以及SPP net使用的都是L2 loss,这是因为,作者发现,L1 loss相对于L2 loss,其对异常值的敏感程度较低,有利于regression的训练。
4、SGD参数设置
用于Softmax分类和检测框回归的全连接层的权重分别使用具有方差0.01和0.001的零均值高斯分布初始化。偏置初始化为0。所有层的权重学习率为1倍的全局学习率,偏置为2倍的全局学习率,全局学习率为0.001。
5、对全连接层的处理(一个加速的优化)(可选)
作者使用奇异值分解(SVD),将fc层分解成两步。


这种方法加速了训练与测试过程,大概提速30%。仅仅损失了一点点mAP。

六、实验结果
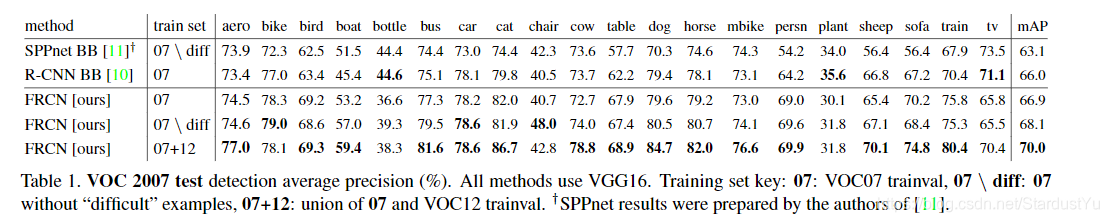
基于VGG16的Fast RCNN算法在训练速度上比RCNN快了将近9倍,比SPPnet快大概3倍;测试速度比RCNN快了213倍,比SPPnet快了10倍。在VOC2012上的mAP在66%左右。

七、论文细节与思考
1、Scale invariance(尺寸不变性)
对于输入图片的大小该如何处理?作者发现卷积网络具有很好的Scale invariance,并不需要过多的认为调节,因此multi-scale的方法对模型的提升效果不是很大,但却使得训练时间增加。因此作者直接采用single-scale的方法,直接将图片缩放到固定大小后,放入卷积网络里。
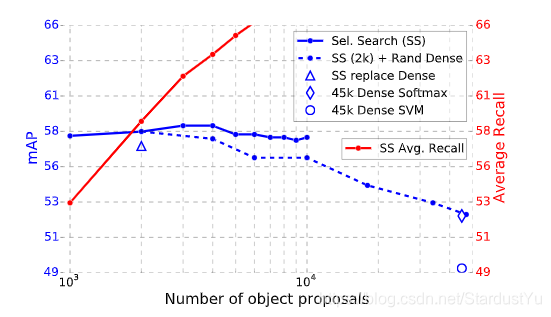
2、是不是region proposal越多,训练的越好?
作者通过实验发现并不是这样的,作者从1k到10k做实验,发现mAP先升高一点点,之后便开始下降。蓝色实线便是mAp的曲线