版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:http://tecdat.cn/?p=6358
多重插补已成为处理缺失数据的常用方法 。 我们可以考虑使用多个插补来估算X中的缺失值。接下来的一个自然问题是,在X的插补模型中,变量Y是否应该作为协变量包含在内?
Stata
为了说明这些概念,我们在Stata中模拟了一个小数据集,最初没有缺失数据:
gen x = rnormal()
gen y = x + 0.25 * rnormal()
twoway(scatter yx)(lfit yx)
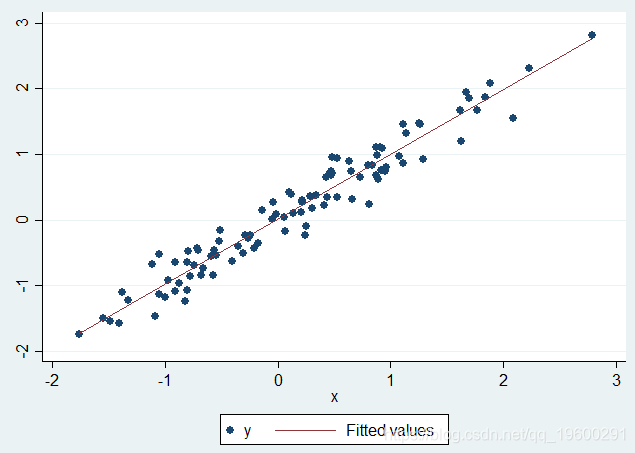
在任何数据缺失之前,Y对X的散点图
接下来,我们将X的100个观察中的50个设置为缺失:
gen xmiss =(_ n <= 50)
插补模型
在本文中,我们有两个变量Y和X,分析模型由Y上的Y的某种类型的回归组成(意味着Y是因变量而X是协变量),我们希望生成这样的插补我们得到Y | X模型中参数的有效估计。
输入X忽略Y
假设我们使用回归模型来估算X,但是在插补模型中不包括Y作为协变量。我们可以在Stata中轻松完成此操作,为每个缺失值生成一个估算值,然后根据X的结果推算值或观察到的X(当观察到它时)绘制Y:
mi impute reg x,add(1)
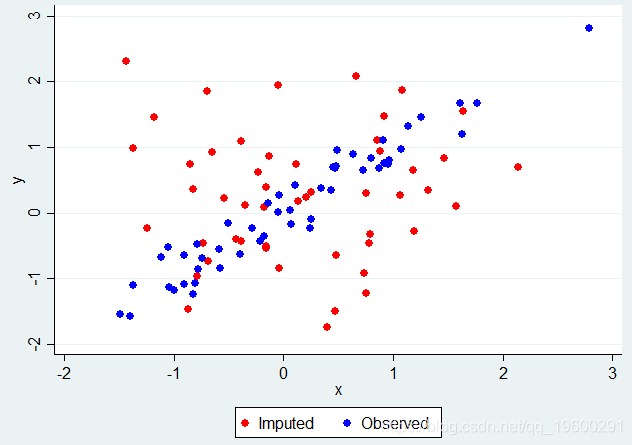
Y对X,其中缺少X值而忽略了Y.
清楚地显示了在X中忽略Y的缺失值的问题 - 在我们已经估算X的那些中,Y和X之间没有关联,实际上应该存在。
将结果考虑在内的
假设如果我们反过来将X结果考虑为Y(作为X的插补模型中的协变量),则会发生以下步骤。X | Y的插补模型将使用观察到X的个体来拟合。由于我们假设X在Y处随机丢失,因此完整的案例分析拟合是有效的。因此,如果实际上X和Y之间没有关联,我们应该(在期望中)在这个完整的情况下找到它。
要继续我们的模拟数据集,我们首先丢弃之前生成的估算值,然后重新输入X,但这次包括Y作为插补模型中的协变量:
mi impute reg x = y,add(1)
Y对X,其中使用Y估算缺失的X值
多重插补中的变量选择
选择要包含在插补模型中的变量时的一般规则是,必须包括分析模型中涉及的所有变量,或者作为被估算的变量,或者作为插补模型中的协变量。