kafka入门
01.消息引擎系统ABC
kafka是什么?kafka是一款开源的消息引擎系统。如果消息引擎系统这个词对你来说有点陌生的话,那么"消息队列"、"消息中间件"你一定是有所耳闻的。对于kafka来说,如果叫消息队列,那么仿佛是在暗示kafka使用队列的方式构建的,如果叫消息中间件,又过度夸张"中间件",让人搞不清楚这个中间件到底是干嘛的。而kafka在国外又一个专属的名字,叫做message system,之所以翻译成消息引擎系统,是因为不要只关注递消息,同时也要关注这类系统所具有的引以为豪的消息传递属性,就像引擎一样,具备某种能量转换传输的能力。
那么继续聊聊消息引擎系统,那么这类系统是干什么的呢?根据维基百科的定义,消息引擎系统是一组规范,企业利用这组规范在不同系统之间传递语义准确的消息,实现松耦合的异步式数据传递。果然这种定义永远都是那么的阳春白雪,我们可以再看一个下里巴人的定义。
消息A发送消息给消息引擎系统,系统B从消息引擎系统中读取A发送的消息。
是不是很简单呢?最基础的消息引擎就是用来干这点事的。无论定义的阳春白雪、亦或下里巴人,它们都提到了两个重要的事实。
消息引擎传输的对象是消息如何传输消息属于消息引擎设计机制的一部分
既然消息引擎是用于在不同系统之间传输消息,那么如何设计待传输消息的格式从来都是一等一的大事。试问:一条消息如何做到信息表达业务语义而无歧义,同时它还要能最大限度地提供可重用性以及通用性?稍微停顿几秒去思考一下,如果是你,你要如何设计你的消息编码格式。
一个比较容易想到的是使用一些已有的成熟解决方案,比如使用csv、xml、json等等,又或者是国外大厂开源的一些序列化框架,比如Google的protocol buffer或Facebook的thrift。但是对于kafka来说,它使用的是纯二进制的字节序列。当然消息还是结构化的,只是使用之前都要将其转化成二进制的字节序列
但是消息设计出来还不够,之前也提到过,如何传递消息也是属于消息引擎设计机制的一部分。也就是说,我用什么方式将消息传递出去。常见的有两种办法:
点对点模型:点对点模型,也叫做消息队列模型。如果拿上面的那个下里巴人版的定义来说的话,那么系统A发送的消息只能被系统B接收,其他任何系统都不能接收A发来的消息。日常生活中就好电话客服服务,同一个客户呼入电话,只能被一位客服人员处理,第二个客服人员不能为该客户服务。发布/订阅模型:和点对点模型不同,它有一个主题(Topic)的概念。该模型也有发送方和接收方,只不过叫法不一样。发送方也被成为发布者(publisher),接收方成为订阅者(subscriber)。和点对点模型不一样,这个模型可以存在多个发布者和多个订阅者,它们都能接收到相同主题的消息。好比微信公众号,一个公众号可以有多个订阅者,一个订阅者也可以订阅多个公众号。
提到消息引擎系统,可能会有人好奇,它和jms是什么关系。jms是java message service,它也是支持上面这两种消息引擎模型的,并且严格来说,它并非传输协议而是一组api罢了。不过可能是jms太有名气(其实java垃圾)以至于很多主流消息引擎系统都支持jms规范,比如ActiveMQ,RabbitMQ、IBM的WebSphereMQ和Apache Kafka。当然kafka并未完全遵照jms规范(干得漂亮),相反,它另辟蹊径,探索出了一条特有的道路(坚持特色社会主义)
介绍完消息引擎系统以及模型,我们回过头来思考。还拿之前的例子,为什么系统A不直接向系统B发送消息,而是非要隔一个消息引擎呢?
答案是:削峰填谷,真的是非常形象的四个字。所谓的削峰填谷,就是指缓冲上下游瞬时突发流量,使其更平滑。特别是那种发送能力很强的上游系统,如果没有消息引擎的保护,脆弱的下游系统可能会直接被压垮导致全链路服务雪崩。但是,一旦有了消息引擎,它能够有效的对抗上游的流量冲击,真正做到将上游的"峰"填到"谷"中,避免了流量的震荡。消息引擎系统的另一大好处在于发送方和接收方的松耦合,这也在一定程度上简化了应用的开发,减少了系统间不必要的交互。
说了这么多,可能没有直观的感受,我们来举一个实际的例子。比如在京东购买商品。当点击购买的时候,会调用订单系统生成对应的订单,然而要处理该订单则会榆次调用下游系统的多个子服务,比如调用银行等支付接口、查询你的登录信息、验证商品信息等等。显然上游的订单操作比较简单,它的TPS要远高于处理订单的下游服务。因此如果上游和下游直接对接,势必会出现下游服务无法及时处理上游订单从而造成订单堆积的情况。特别是当出现双十一、双十二、类似秒杀这种业务的时候,上游订单流量会瞬间增加,可能出现的结果就是直接压垮下游子系统服务。解决此问题的一个常见的做法就是对上游系统进行限速,但是这种做法显然是不合理的,毕竟问题不是出现在它那里。况且你要是限速了,别人家网站双十一成交一千万笔单子,自家网站才成交一百万笔单子,这样钱送到嘴边都赚不到。所以更常见的办法就是引入像kafka这样的消息引擎系统来对抗这种上下游系统的TPS不一致以及瞬时峰值流量。
还是这个例子,当引入了kafka之后,上游系统不再直接与下游系统进行交互。当新订单生成之后它仅仅是向kafka broker发送一条消息即可。类似的,下游的各个子服务订阅kafka中的对应主题,并实时从该主题的各自分区(partition)中获取到订单消息进行处理,从而实现上游订单服务和下游订单处理服务的解耦。这样当出现秒杀业务的时候,kafka能够将瞬时增加的订单流量全部以消息的形式保存在对应的主题中。既不影响上游服务的TPS,同时也给下游服务流出了足够的时间去消费它们。这就是kafka这类消息引擎存在的最大意义所在。
目前我们介绍了什么是消息引擎,消息引擎是做什么的。关于broker、主题、分区等这些kakfa当中的术语不知道也没有关系,我们会在后面详细介绍。

02.搞定kafka专业术语
在kafka的世界中有很多概念和术语是需要我们提前理解并且熟练掌握的,下面来盘点一下。
之前我们提到过,kafka属于分布式的消息引擎系统,主要功能是提供一套完善的消息发布与订阅方案。在kafka中,发布订阅的对象是主题(topic),可以为每个业务、每个应用、甚至是每一类数据都创建专属的主题
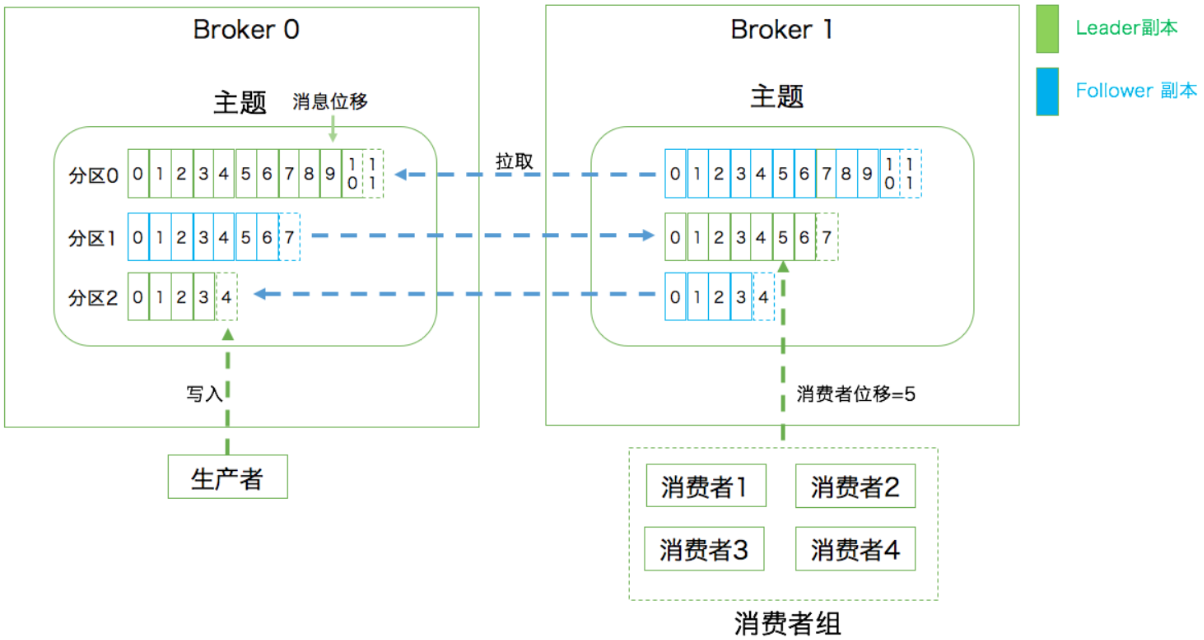
向主题发布消息的客户端应用程序成为生产者(producer),生产者通常持续不断地向一个或多个主题发送消息,而订阅这些主题获取消息的客户端应用程序就被称之为消费者(consumer)。和生产者类似,消费者也能同时订阅多个主题。我们把生产者和消费者统称为客户端(clients)。你可以同时运行多个生产者和消费者实例,这些实例不断地向kafka集群中的多个主题生产和消费消息。有客户端自然也就有服务端。kafka的服务器端由被称为broker的服务进程构成,即一个kafka集群由多个broker组成,broker负责接收和处理客户端发来的请求,以及对消息进行持久化。虽然多个broker进程能够运行在同一台机器上,但更常见的做法是将不同的broker分散运行在不同的机器上。这样即便集群中的某一台机器宕机,运行在其之上的broker进程挂掉了其他机器上的broker也依旧能对外提供服务。这其实就是kafka提供高可用的手段之一
在实现高可用的另一个手段就是备份机制(replication)。备份的思想很简单,就是把相同的数据拷贝到多台机器上,而这些相同的数据拷贝就叫做副本(replica)。副本的数量是可以配置的,这些副本保存着相同的数据,但却有不同的角色和作用。kafka定义了两种副本,领导者副本(leader replica)和追随者副本(follower replica)。前者对外提供服务,这里的对外指的是与客户端进行交互;而后者只是被动地追随领导者副本而已,不与外界进行交互。当然了,很多其他系统中追随者副本是可以对外提供服务的,比如mysql,从库是可以处理读操作的,也就是所谓的"主写从读",但是在kafka中追随者副本不会对外提供服务,至于为什么我们作为思考题解答。对了,关于领导者--追随者,之前其实是叫做主(master)--从(slave),但是不建议使用了,因为slave有奴隶的意思,政治上有点不合适,所以目前大部分的系统都改成leader-follower了。
副本的工作机制很简单:生产者向主题写的消息总是往领导者那里,消费者向主题获取消息也都是来自于领导者。也就是无论是读还是写,针对的都是领导者副本,至于追随者副本,它只做一件事情,那就是向领导者副本发送请求,请求领导者副本把最新生产的消息发送给它,这样便能够保持和领导者的同步。
虽然有了副本机制可以保证数据的持久化或者数据不丢失,但没有解决伸缩性的问题。伸缩性即所谓的scalability,是分布式系统中非常重要且必须谨慎对待的问题。什么事伸缩性呢?我们拿副本来说,虽然现在有了领导者副本和追随者副本,但倘若领导者副本积累了太多的数据以至于单台broker都无法容纳了,此时应该怎么办?有个很自然的想法就是,能否把数据分割成多分保存在不同的broker上?没错,kafka就是这么设计的。
这种机制就是所谓的分区(partition)。如果了解其他的分布式系统,那么可能听说过分片、分区域等提法,比如MongoDB和ElasticSearch中的sharding、Hbase中的region,其实它们都是相同的原理,只是partition是最标准的名称。
kafka中的分区机制指定的是将每个主题划分为多个分区,每个分区都是一组有序的消息日志。生产者生产的每一条消息只会被发到一个分区中,也就说如果向有两个分区的主题发送一条消息,那么这条消息要么在第一个分区中,要么在第二条分区中。而kafka的分区编号是从0开始的,如果某个topic有100个分区,那么它们的分区编号就是从0到99
到这里可能会有疑问,那就是刚才提到的副本如何与这里的分区联系在一起呢?实际上,副本是在分区这个层级定义的。每个分区下可以配置若干个副本,其中只能有1个领导者副本和N-1个追随者副本。生产者向分区写入消息,每条消息在分区中的位置由一个叫位移(offset)的数据来表征。分区位移总是从0开始,假设一个生产者向一个空分区写入了10条消息,那么这10条消息的位移依次是0、1、2、...、9
至此我们能完整地串联起kafka的三层消息架构
第一层是主题层,每个主题可以配置M个分区,每个分区又可以配置N个副本第二层是分区层,每个分区的N个副本中只能有一个副本来充当领导者角色,对外提供服务;其他的N-1个副本只是追随者副本,用来提供数据冗余之用。第三层是消息层,分区中包含若干条消息,每条消息的位移从0开始,依次递增。最后客户端程序只能与分区的领导者副本进行交互
那么kafka是如何持久化数据的呢?总的来说,kafka使用消息日志(log)来保存数据,一个日志就是磁盘上一个只能追加写(append-only)消息的物理文件。因为只能追加写入,故避免了缓慢的随机I/O操作,改为性能较好的顺序I/O操作,这也是实现kafka高吞吐量特性的一个重要手段。不过如果不停地向一个日志写入消息,最终也会耗尽所有的磁盘空间,因此kafka必然要定期地删除消息以回收磁盘。怎么删除?简单来说就是通过日志段(log segment)机制。在kafka底层,一个日志又进一步细分成多个日志段,消息被追加写到当前最新的日志段中,当写满了一个日志段后,kafka会自动切分出一个新的日志段,并将老的日志段封存起来。kafka在后台还有定时任务会定期地检查老的日志段是否能够被删除,从而实现回收磁盘的目的。
这里再重点说一下消费者,之前说过有两种消息模型,即点对点模型(peer to peer, p2p)和分布订阅模型。这里面的点对点指的是同一条消息只能被下游的一个消费者消费,其他消费者不能染指。在kafka中实现这种p2p模型的方法就是引入了消费者组(consumer group)。所谓的消费者组,指的是多个消费者实例共同组成一个组来消费一个主题。这个主题中的每个分区都只会被消费者组里面的一个消费者实例消费,其他消费者实例不能消费它。为什么要引入消费者组呢?主要是为了提升消费者端的吞吐量,多个消费者实例同时消费,加速了整个消费端的吞吐量(TPS)。关于消费者组的机制,后面会详细介绍,现在只需要知道消费者组就是多个消费者组成一个组来消费主题里面的消息、并且消息只会被组里面的一个消费者消费即可。此外,这里的消费者实例可以是运行消费者应用的进程,也可以是一个线程,它们都称为一个消费者实例(consumer instance)
消费者组里面的消费者不仅瓜分订阅主题的数据,而且更酷的是它们还能彼此协助。假设组内某个实例挂掉了,kafka能够自动检测,然后把这个Failed实例之前负责的分区转移给其他活着的消费者。这个过程就是大名鼎鼎的"重平衡(rebalance)"。嗯,其实即是大名鼎鼎,也是臭名昭著,因为由重平衡引发的消费者问题比比皆是。事实上,目前很多重平衡的bug,整个社区都无力解决。
每个消费者在消费消息的过程中,必然需要有个字段记录它当前消费到了分区的哪个位置上,这个字段就是消费者位移(consumer offset)。注意,我们之前说一个主题可以有多个分区、每个分区也是用位移来表示消息的位置。但是这两个位移完全不是一个概念,分区位移表示的是分区内的消息位置,它是不变的,一旦消息被成功写入一个分区上,那么它的位置就是固定了的。而消费者位移则不同,它可能是随时变化的,毕竟它是消费者消费进度的指示器嘛。另外每个消费者都有着自己的消费者位移,因此一定要区分这两类位移的区别。一个是分区位移,另一个是消费者位移
小结:
生产者,producer:向主题发布新消息的应用程序消费者,consumer:从主题订阅新消息的应用程序消息,record:kafka是消息引擎,这里的消息就是指kafka处理的主要对象主题,topic:主题是承载消息的逻辑容器,在实际使用中多用来区分具体的业务,即不同的业务对应不同的主题。分区,partition:一个有序不变的消息序列,每个主题下可以有多个分区。分区编号从0开始,分布在不同的broker上面,实现发布于订阅的负载均衡。生产者将消息发送到主题下的某个分区中,以分区偏移(offset)来标识一条消息在一个分区当中的位置(唯一性)分区位移,offset:表示分区中每条消息的位置信息,是一个单调递增且不变的值副本,replica:kafka中同一条数据能够被拷贝到多个地方以提供数据冗余,这便是所谓的副本。副本还分为领导者副本和追随者副本,各自有各自的功能职责。读写都是针对领导者副本来的,追随者副本只是用来和领导者副本进行数据同步、保证数据冗余、实现高可用。消费者位移,consumer offset:表示消费者消费进度,每个消费者都有自己的消费者位移消费者组,consumer group:多个消费者实例共同组成的一个组,同时消费多个分区以实现高吞吐。重平衡,rebalance:消费者组内某个消费者实例挂掉之后,其它消费者实例自动重新分配订阅主题分区的过程。重平衡是kafka消费者端实现高可用的重要手段
思考:为什么kafka不像mysql那样支持主写从读呢?
因为kafka的主题已经被分为多个分区,分布在不同的broker上,而不同的broker又分布在不同的机器上,因此从某种角度来说,kafka已经实现了负载均衡的效果。不像mysql,压力都在主上面,所以才要从读;另外,kafka保存的数据和数据库的数据有着实质性的差别,kafka保存的数据是流数据,具有消费的概念,而且需要消费者位移。所以如果支持从读,那么消费端控制offset会更复杂,而且领导者副本同步到追随者副本需要时间的,会造成数据不一致的问题;另外对于生产者来说,kafka是可以通过配置来控制是否等待follower对消息确认的,如果支持从读的话,那么也需要所有的follower都确认了才可以回复生产者,造成性能下降,而且follower出现了问题也不好处理。
03.kafka只是消息引擎系统吗
kafka真的只是消息引擎系统吗?要搞清楚这个问题,就要从kafka的发展历史说起,纵观kafka的发展历史,它确实是消息引擎起家的,但它不仅是一个消息引擎系统,同时也是一个分布式流处理平台(distributed stream processing platform)。如果这一节你只能记住一句户的话,那我希望你能记住,kafka虽然是消息引擎起家,但它不仅是一个消息引擎,还是一个分布式流处理平台。
总所周知,kafka是LinkedIn公司内部孵化的项目,LinkedIn最开始有强烈的数据强实时处理方面的需求,其内部的诸多子系统要执行多种类型的数据处理与分析,主要包括业务系统和应用程序性能监控,以及用户行为数据处理等。当时他们碰到的主要问题包括:
数据正确性不足。因为数据的收集主要采用轮询(polling)的方式,如何确定轮询的时间间隔就变成了一个高度经验化的事情。虽然可以采用一些类似于启发式算法来帮助评估间隔时间,但一旦指定不当,必然会造成较大的数据偏差。系统高度定制化,维护成本高。各个业务子系统都需要对接数据收集模块,引入了大量的定制开销和人工成本
为了解决这些问题,LinkedIn工程师尝试过使用ActiveMQ来解决这些问题,但效果并不理想。显然需要有一个"大一统"的系统来取代现有的工作方式,而这个系统就是kafka。因此kafka自诞生伊始是以消息引擎系统的面目出现在大众视野的,如果翻看比较老的kafka对应的官网的话,你会发现kafka社区将其清晰地定位为一个分布式、分区化且带备份功能的提交日志(commit log)服务。
因此,kafka在设计之初就旨在提供三个方面的特性:
提供一套API实现生产者和消费者降低网络传输和磁盘存储开销实现高伸缩架构
在现如今的大数据领域,kafka在承接上下游、串联数据流管道方面发挥了重要的作用:所有的数据几乎都要从一个系统流入kafka,然后再流入下游的另一个系统中 。这样使用方式屡见不鲜以至于引发了kafka社区的思考:与其我把数据从一个系统传递到下一个系统进行处理,我为何不自己实现一套流处理框架呢?基于这个考量,kafka社区在0.10.0.0版本推出了流处理组件kafka streams,也正是从这个版本开始,kafka正式变身为分布式的流处理平台,而不再仅仅只是消息引擎系统了。今天kafka是和storm、spark、flink同等级的实时流处理平台了。
那么作为流处理平台,kafka与其他大数据流式计算框架相比,优势在哪里呢?
第一点是更容易实现端到端的正确性(correctness)。流处理要最终替代它的兄弟批处理需要具备两点核心优势:要实现正确性和提供能够推导时间的工具。实现正确性是流处理能够匹敌批处理的基石。正确性一直是批处理的强项,而实现正确性的基石则是要求框架能提供'精确一次语义处理',即处理一条消息有且只有一次机会能够影响系统状态。目前主流的大数据流处理框架都宣称实现了'精确一次语义处理',但是这是有限定条件的,即它们只能实现框架内的精确一次语义处理,无法实现端到端的。这是为什么呢?因为当这些框架与外部消息引擎系统结合使用时,它们无法影响到外部系统的处理语义,所以如果你搭建了一套环境使得spark或flink从kafka读取消息之后进行有状态的数据计算,最后再写回kafka,那么你只能保证在spark或者flink内部,这条消息对于状态的影响只有一次。但是计算结果有可能多次写入的kafka,因为它们不能控制kafka的语义处理。相反地,kafka则不是这样,因为所有的数据流转和计算都在kafka内部完成,故kafka可以实现端到端的精确一次处理。第二点是kafka自己对于流式计算的定位。官网上明确表示kafka streams是一个用于搭建实时流处理的客户端库而非是一个完整地功能系统。这就是说,你不能期望着kafka提供类似于集群调度、弹性部署等开箱即用的运维特性,你需要自己选择合适的工具或者系统来帮助kafka流处理应用实现这些功能。读到这里可能觉得这怎么是有点呢?坦率的说,这是一个双刃剑的设计,也是kafka剑走偏锋不正面pk其他流计算框架的特意考量。大型公司的流处理平台一定是大规模部署的,因此具备集群调度功能以及灵活的部署方案是不可获取的要素。但毕竟世界上还存在着很多中小企业,它们的流处理数据量并不巨大,逻辑也不复杂,部署几台或者十几台机器足以应付。在这样的需求下,搭建重量级的完整性平台实在是'杀鸡用宰牛刀',而这正式kafka流处理组件的用武之地。因此从这个角度来说,未来在流处理框架当中,kafka应该是有着一席之地的。
这里再来解释一下什么是精确一次语义处理。举个例子,如果我们使用kafka计算某网页的pv,我们将每次网页访问都作为一个消息发送给kafka,pv的计算就是我们统计kafka总共接收了多少条这样的消息即可。精确一次语义处理表示每次网页访问都会产生、且只产生一条消息
处理消息引擎和流处理平台,kafka还有别的用途吗?当然有,kafka甚至能够被用作分布式存储系统,但是实际生产中,没有人会把kafka当中分布式存储系统来用的。kafka从一个优秀的消息引擎系统起家,逐渐演变成现在的分布式的流处理平台。我们不仅要熟练掌握它作为消息引擎系统的非凡特性以及使用技巧,最好还要多了解下其流处理组件的设计与案例应用。

04.应该选择哪种kafka
我们上一节谈了kafka当前的定位问题,kafka不再是一个单纯的消息引擎系统,而是能够实现精确一次(exactly-once)语义处理的实时流平台。我们到目前为止所说的kafka都是Apache kafka,kafka是Apache社区的一个顶级项目,如果我们把视角从流处理平台扩展到流处理生态圈,kafka其实还有很长的路要走,毕竟是半路出家转型成流处理平台的。前面我们提到过kafka streams组件,正是它提供了kafka实时处理流数据的能力。但是其实还有一个重要的组件没有提及,那就是kafka connect。
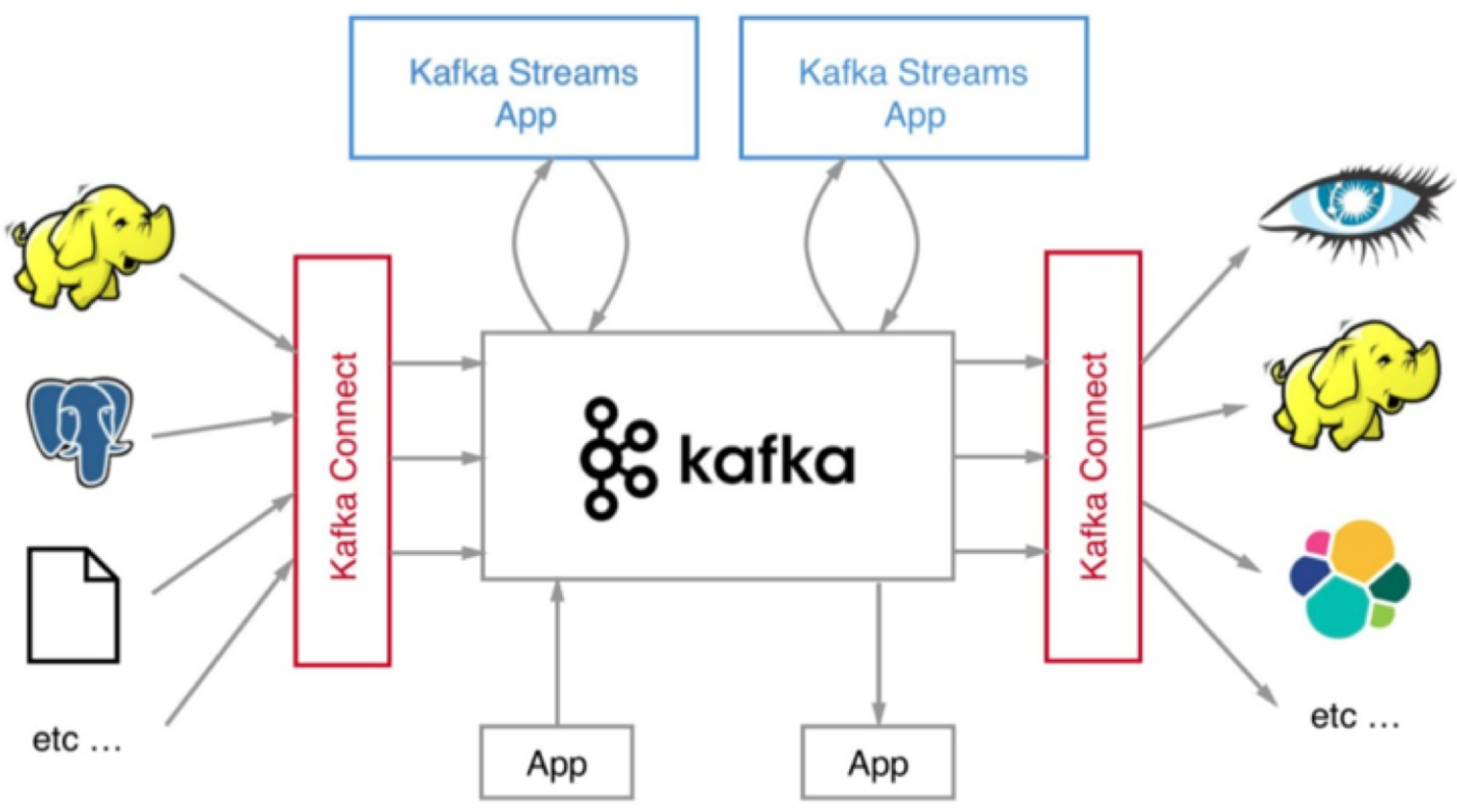
我们在评估流处理平台的时候,框架本身的性能、所提供操作算子(operator)的丰富程度固然是重要的评判指标,但是框架与上下游交互的能力也是非常重要的。能够与之进行数据传输的外部系统越多,围绕它打造的生态圈就越牢固,因而也就有更多的人愿意去使用它,从而形成正向反馈,不断地促进该生态圈的发展。就kafka而言,kafka connect通过一个个具体的连接器(connector),串联起上下游的外部系统。
整个kafka生态圈如下图所示,值得注意的是,这张图的外部系统只是kafka connect组件支持的一部分而已。目前还有一个可喜的趋势是使用kafka connect组件的用户越来越多,相信在未来会有越来越多的人开发自己的连接器。
说了这么多,可能会有人好奇这跟这一节的主题有什么关系呢?其实清晰地了解kafka的发展脉络和生态圈现状,对于我们选择合适的kafka版本大有裨益。下面我们就进入今天的主题---如何选择kafka版本
首先你知道几种kafka
咦?kafka不是一个开源框架吗?什么叫有几种kafka,实际上,kafka的确有好几种kafka啊?实际上,kafka的确有好几种,这里我不是指它的版本,而是指存在多个组织或者公司发布的不同kafka。就像linux的发行版,有Ubuntu、centos等等,虽说kafka没有发行版的概念,但姑且可以这样的近似的认为市面上的确存在着多个kafka"发行版"。当然用发行版这个词只是为了这里方便解释,但是发行版这个词在kafka生态圈非常陌生,以后聊天时不要用发行版这个词。下面我们就看看kafka都有哪些"发行版"
Apache kafka:Apache kafka是最"正宗"的kafka,也应该是最熟悉的发行版了。字kafka开源伊始,它便在Apache基金会孵化并最终毕业成为顶级项目,也被称之为社区版kafka。目前我也是以这个版本的kafka进行介绍的。更重要的是,它是后面其他所有发行版的基础。也就是说,其他的发行版要么是原封不动的继承了Apache kafka,要么是在其基础之上进行了扩展、添加了新功能,总之Apache kafka是我们学习和使用kafka的基础。
Confluent kafka:我先说说Confluent公司吧。2014年,kafka的3个创始人Jay Kreps、Naha Narkhede 和饶军离开 LinkedIn创办了Confluent公司,专注于提供基于kafka的企业级流处理解决方案。2019年1月,Confluent公司成功融资1.25亿美元,估值也到了25亿美元,足见资本市场的青睐。这里说点题外话,饶军是我们中国人,清华大学毕业的大神级人物。我们已经看到越来越多的Apache顶级项目创始人中出现了中国人的身影。另一个例子就是,Apache pulsar,它是一个以打败kafka为目标的新一代消息引擎系统,在开源社区中活跃的中国人数不胜数,这种现象实在令人振奋。还说回Confluent公司,它主要从事商业化的kafka工具开发,并在此基础上发布了Confluent kafka。Confluent kafka提供了Apache kafka没有的高级特性,比如跨数据中心备份、schema注册中心以及集群监控工具等等。
Cloudera/Hortonworks KafkaCloudera提供的CDH和Hortonworks提供的HDP是非常著名的大数据平台,里面集成了目前主流的大数据框架,能够帮助用户实现从分布式存储、集群调度、流处理到机器学习、实时数据库等全方位的数据处理。很多创业公司在搭建数据平台时首选就是这两个产品。不管是CDH还是HDP,里面都集成了Apache kafka,因此就把这款产品中的kafka称之为CDH kafka和HDP kafka
当然在2018年10月两家公司宣布合并,共同打造世界领先的数据平台,也许以后CDH和HDP也会合并成一款产品,但能肯定的是Apache kafka依然会包含其中,并作为新数据平台的一部分对外提供服务。
特点比较
okay,说完了目前市面上的这些kafka,我们来对比一下它们的优势和劣势
1.Apache kafka
对Apache kafka而言,它现在依旧是开发人数最多,版本迭代速度最快的kafka。在2018年度Apache基金会邮件列表中开发者数量最多的top5排行榜中,kafka社区邮件组排名第二位。如果你使用Apache kafka碰到任何问题并将问题提交到社区,社区都会比较及时的响应你。这对于我们kafka普通使用者来说无疑是非常友好的。
但是Apache kafka的劣势在于它仅仅提供最最基础的主组件,特别是对于前面提到的kafka connect而言,社区版kafka只提供一种连接器,即读写磁盘文件的连接器,而没有与其他外部系统交互的连接器,在实际使用过程中需要自行编写代码实现,这是它的一个劣势。另外Apache kafka没有提供任何监控框架或工具,而在线上环境不加监控肯定是不行的,你必然需要借助第三方的监控框架来对kafka进行监控。好消息是目前有一些开源的监控框架可以帮助用于监控kafka(比如kafka manager)
总而言之,如果仅仅需要一个消息引擎系统亦或是简单的流处理应用场景,同时需要对系统有较大把控度,那么我推荐你使用Apache kafka2.Confluent kafka
下面来看看Confluent kafka。Confluent kafka目前分为免费版和企业版两种。前者和Apache kafka非常相像,除了常规的组件之外,免费版还包含schema注册中心和rest proxy两大功能。前者是帮助你集中管理kafka消息格式以实现数据向前/向后兼容;后者用开放的HTTP接口的方式允许你通过网络访问kafka的各种功能,这两个都是Apache kafka所没有的。除此之外,免费版还包含了更多的连接器,它们都是Confluent公司开发并认证过的,你可以免费使用它们。至于企业版,它提供的功能就更多了,最有用的当属跨数据中心备份和集群监控两大功能了。多个数据中心之间数据的同步以及对集群的监控历来是kafka的痛点,Confluent kafka企业版提供了强大的解决方案来帮助你干掉它们。不过Confluent kafka没有发展国内业务的计划,相关资料以及技术支持都很欠缺,很多国内的使用者都无法找到对应的中文文档,因此目前Confluent kafka在国内的普及率是比较低的。
一言以蔽之,如果你需要使用kafka的一些高级特性,那么推荐你使用Confluent kafka。3.CDH/HDP kafka
最后说说大数据云公司发布的kafka,这些大数据平台天然继承了Apache kafka,通过便捷化的界面操作将kafka的安装、运维、管理、监控全部统一在控制台中。如果你是这些平台的用户一定觉得非常方便,因为所有的操作都可以在前段UI界面上完成,而不必执行复杂的kafka命令。另外这些平台的监控界面也非常友好,你通常不需要进行任何配置就能有效的监控kafka。
但是凡事有利就有弊,这样做的结果就是直接降低了你对kafka集群的掌握程度。毕竟你对下层的kafka集群一无所知,你怎么能够做到心中有数呢?这种kafka的另一个弊端在于它的滞后性,由于它有自己的发布周期,因此是否能及时地包含最新版本的kafka就成为了一个问题。比如CDH6.1.0版本发布时Apache kafka已经演进到了2.1.0版本,但CDH中的kafka仍然是2.0.0版本,显然那些在kafka2.1.0中修复的bug只能等到CDH下次版本更新时才有可能被真正修复。
简单来说,如果你需要快速的搭建消息引擎系统,或者你需要搭建的是多框架构成的数据平台且kafka只是其中的一个组件,那么建议使用这些大数据云公司提供的kafka。
小结
总结一下,我们今天讨论了不同的kafka"发行版"以及它们的优缺点,根据这些优缺点,我们可以有针对性地根据实际需求选择合适的kafka。最后我们回顾一下今天的内容:
Apache kafka,也成社区办kafka。优势在于迭代速度快,社区响应度高,使用它可以让你有更高的把控度;缺陷在于仅提供最基础的核心组件,缺失一些高级的特性。Confluent kafka,Confluent公司提供的kafka。优势在于集成了很多高级特性且由kafka原版人马打造,质量上有保证;缺陷在于相关资料不全,普及率较低,没有太多可供参考的范例。CDH/HPD kafka,大数据云公司提供的kafka,内嵌Apache kafka。优势在于操作简单,节省运维成本;缺陷在于把控度低,演进速度较慢。

05.聊聊kafka的版本号
今天聊聊kafka版本号的问题,这个问题实在是太重要了,我觉得甚至是日后能否用好kafka的关键。上一节我们介绍了kafka的几种发行版,其实不论是哪种kafka,本质上都内嵌了最核心的Apache kafka,也就是社区版kafka,那今天我们就说说Apache kafka版本号的问题。在开始之前,先强调一下,后面出现的所有"版本"这个词都表示kafka具体的版本号,而非上一节中介绍kafka种类,这一点要切记。
那么现在可能会有这样的疑问,我为什么要关心版本号的问题呢?直接使用最新版本不就好了吗?当然了,这的确是一种有效的版本选择的策略,但我想强调的是这种策略并非在任何场景下都适用。如果你不了解各个版本之间的差异和功能变化,你怎么能准确地评判某kafka版本是不是满足你的业务需求呢?因此在深入学习kafka之前,花些时间搞明白版本演进,实际上是非常划算的一件事。
kafka版本命名
当前Apache kafka已经迭代到2.2版本,社区正在为2.3.0发版日期进行投票,相信2.3.0也会马上发布。但是稍微有些令人吃惊的是,很多人对于kafka的版本命名理解存在歧义。比如我们在官网下载kafka时,会看到这样的版本。

于是有些人或许就会纳闷,难道kafka的版本号不是2.11或者2.12吗?其实不然,前面的版本号是编译kafka源代码的Scala编译器版本。kafka服务器端的代码完全由Scala语言编写,Scala同时支持面向对象编程和函数式编程,用Scala写的源代码编译之后也是普通".class"文件,因此我们说Scala是JVM系的语言,它的很多设计思想都是为人称道的。
事实上目前java新推出的很多功能都是在不断地向Scala靠近,比如lambda表达式、函数式接口、val变量等等。一个有意思的事情是,kafka新版客户端代码完全由java语言编写,于是有人展开了java vs Scala的讨论,并从语言特性的角度尝试分析kafka社区为什么放弃Scala转而使用java重写客户端代码。其实事情远没有那么复杂,仅仅是因为社区来了一批java程序员而已,而以前老的Scala程序员隐退罢了。可能有点跑题了,但是不管怎么样,我依然建议你有空学一学python语言。
回到刚才的版本号讨论,现在你应该知道了对于kafka-2.11-2.1.1的提法,真正的kafka版本号是2.1.1,那么这个2.1.1又表示什么呢?前面的2表示大版本号,即major version;中间的1表示小版本号或者次版本号,即minor version;最后的1表示修订版本号,也就是patch号。kafka社区在发布1.0.0版本后特意写过一篇文章,宣布kafka版本命名规则正式从4位演进到3位,比如0.11.0.0版本就是4位版本号。
kafka版本演进
于kafka目前总共演进了7个大版本,分别是0.7、0.8、0.9、0.10、0.11、1.0和2.0,其中的小版本和patch版本很多。哪些版本引入了哪些重大的功能改进?建议你最好做到如数家珍,因为这样不仅令你在和别人交谈时显得很酷,而且如果你要向架构师转型或者已然是架构师,那么这些都是能够帮助你进行技术选型、架构评估的重要依据。
我们先从0.7版本说起,实际上也没有什么可说的,这是最早开源时的上古版本了。这个版本只提供了最基础的消息队列功能,甚至连副本机制都没有,我实在想不出来有什么理由你要使用这个版本,因此如果有人要向你推荐这个版本,果断走开好了。
kafka从0.7时代演进到0.8之后正式引入了副本机制,至此kafka成为了一个真正意义上完备的分布式、高可靠消息队列解决方案。有了副本备份机制,kafka就能够比较好地做到消息无丢失。那时候生产和消费消息使用的还是老版本客户端的api,所谓老版本是指当你使用它们的api开发生产者和消费者应用时,你需要指定zookeeper的地址而非broker的地址。
如果你现在尚不能理解这两者的区别也没有关系,我会在后续继续介绍它们。老版本的客户端有很多的问题,特别是生产者api,它默认使用同步方式发送消息,可以想到其吞吐量一定不会太高。虽然它也支持异步的方式,但实际场景中消息有可能丢失,因此0.8.2.0版本社区引入了新版本producer api,即需要指定broker地址的producer。
据我所知,国内依然有少部分用户在使用0.8.1.1、0.8.2版本。我的建议是尽量使用比较新的版本,如果你不能升级大版本,我也建议你至少要升级到0.8.2.2这个版本,因为该版本中老版本消费者的api是比较稳定的。另外即使升级到了0.8.2.2,也不要使用新版本producer api,此时它的bug还非常的多。
时间来到了2015年11月,社区正式发布了0.9.0.0版本,在我看来这是一个重量级的大版本更迭,0.9大版本增加了基础的安全认证/权限功能,同时使用java重写了新版本消费者的api,另外还引入了kafka connect组件用于实现高性能的数据抽取。如果这么眼花缭乱的功能你一时无暇顾及,那么我希望你记住这个版本另一个好处,那就是新版本的producer api在这个版本中算比较稳定了。如果你使用0.9作为线上环境不妨切换到新版本producer,这是此版本一个不太为人所知的优势。但和0.8.2引入新api问题类似,不要使用新版本的consumer api,因为bug超级多,绝对用到你崩溃。即使你反馈问题到社区,社区也不管的,它会无脑的推荐你升级到新版本再试试,因此千万别用0.9新版本的consumer api。对于国内一些使用比较老的CDH的创业公司,鉴于其内嵌的就是0.9版本,所以要格外注意这些问题。
0.10.0.0是里程碑式的大版本,因为该版本引入了kafka streams。从这个版本起,kafka正式升级成为分布式流处理平台,虽然此时的kafka streams还不能上线部署使用。0.10大版本包含两个包含两个小版本:0.10.1和0.10.2,它们的主要功能变更都是在kafka streams组件上。如果把kafka作为消息引擎,实际上该版本并没有太多的功能提升。不过在我的印象中,自从0.10.2.2版本起,新版本consumer api算是比较稳定了。如果你依然在使用0.10大版本,那么我强烈建议你至少升级到0.10.2.2然后再使用新版本的consumer api。还有个事情不得不提,0.10.2.2修复了一个可能导致producer性能降低的bug。基于性能的缘故你也应该升级到0.10.2.2。
在2017年6月,社区发布了0.11.0.0版本,引入了两个重量级的功能变更:一个是提供幂等性producer api;另一个是对kafka消息格式做了重构。
前一个好像更加吸引眼球一些,毕竟producer实现幂等性以及支持事务都是kafka实现流处理结果正确性的基石。没有它们,kafka streams在做流处理时无法像批处理那样保证结果的正确性。当然同样是由于刚推出,此时的事务api有一些bug,不算十分稳定。另外事务api主要是为kafka streams应用服务的,实际使用场景中用户利用事务api自行编写程序的成功案例并不多见第二个改进是消息格式的变化。虽然它对用户是透明的,但是它带来的深远影响将一直持续。因为格式变更引起消息格式转换而导致的性能问题在生产环境中屡见不鲜,所以一定要谨慎对待0.11这个版本的变化。不得不说的是,在这个版本中,各个大功能组件都变得相当稳定了,国内该版本的用户也很多,应该算是目前最主流的版本之一了。也正是因为这个缘故,社区为0.11大版本特意退出了3个patch版本,足见它的受欢迎程度。我的建议是,如果你对1.0版本是否适用于线上环境依然感到困惑,那么至少将你的环境升级到0.11.0.3,因为这个版本的消息引擎功能已经非常完善了。
最后合并说一下1.0和2.0版本吧,因为在我看来这两个大版本主要还是kafka streams的各种改进,在消息引擎方面并未引入太多的重大功能特性。kafka streams的确在这两个版本有着非常大的变化,也必须承认kafka streams目前依然还在积极地发展着。如果你是kafka streams的用户,只要选择2.0.0版本吧。
去年8月国外出了一本书叫做kafka streams in action,中文译名:kafka streams实战,它是基于kafka streams1.0版本撰写的,但是用2.0版本去运行书中的很多例子,居然很多都已经无法编译了,足见两个版本的差别之大。不过如果你在意的依然是消息引擎,那么这两个大版本都是可以用于生产环境的。
最后还有个建议,不论你使用的是哪个版本,都请尽量保持服务器端版本和客户端版本一致,否则你将损失很多kafka为你提供的性能优化收益。

kafka的基本使用
06.kafka线上集群部署方案怎么做
前面几节,我们分别从kafka的定位,版本的变迁以及功能的演进等方面循序渐进地梳理了Apache kafka的发展脉络。那么现在我们就来看看生产环境中的kafka集群方案该怎么做。既然是集群,那必然就要有多个kafka节点机器,因为只有单台机器构成的kafka伪集群只能用于日常测试之用,根本无法满足实际的线上生产需求。而真正的线上环境需要仔细地考量各种因素,结合自身的业务需求而制定。下面我们就从操作系统、磁盘、磁盘容量和带宽等方面来讨论一下。
操作系统:
这个不多BB,果断选择linux。至于为什么?主要是在以下这三个方面
I/O模型的使用什么是I/O模型,可以近似的认为是操作系统执行I/O指令的方法。主流的I/O模型有五种:阻塞式I/O,非阻塞式I/O,I/O多路复用,信号驱动I/O,异步I/O。每种I/O模型都有各自的使用场景,但我们想要支持高并发的话,都会选择I/O多路复用,至于异步I/O,由于操作系统支持的不完美,所以不选择。对于I/O多路复用有三种,select、poll、epoll,epoll是在linux内核2.4中提出的,对于I/O轮询可以做到效率最大化,至于这三者的具体关系就不详细介绍了,只需要知道epoll"最好"就行了。说了这么多,那么I/O模型和kafka又有什么关系呢?实际上kafka客户端底层使用java的selector,selector会自动从select、poll、epoll中选择一个,而Windows只支持select。因此在这一点上linux是有优势的,因为能够获得更高效的I/O性能。
数据网络传输效率首先kafka生产和消费的消息都是通过网络传输的,而消息保存在哪里呢?肯定是磁盘,故kafka需要在磁盘和网络之间进行大量数据传输。如果你熟悉linux,那么你肯定听说过零拷贝(zero copy)技术,就是当数据在磁盘和网络进行传输时避免昂贵的内核态数据拷贝从而实现快速的数据传输。linux平台实现了这样的零拷贝机制,但有些遗憾的是在Windows平台上必须等到java8的60更新版本才能享受这个福利。一句话总结一下,在linux部署kafka能够享受到零拷贝技术所带来的快速数据传输特性。
社区支持度最后是社区支持度,这一点虽然不是什么明显的差别,但如果不了解的话,所造成的影响可能会比前两个因素更大。简单的来说,就是社区目前对Windows平台上发现的bug不做任何承诺。因此Windows平台上部署kafka只适合于个人测试或用于功能验证,千万不要用于生产环境。
磁盘:
如果要问哪种资源对kafka性能最重要,磁盘无疑是要排名靠前的。在对kafka集群进行磁盘规划时经常要面对的问题是,我应该选择普通的机械磁盘还是固态硬盘?前者成本低且容量大,但易损坏;后者性能优势大,不过单价高。个人建议:使用普通的机械硬盘即可。
kafka大量使用磁盘不假,可它使用的方式是多顺序读写操作,一定程度上规避了机械磁盘最大的劣势,即随机读写操作慢。从这一点上,使用ssd似乎没有太大的性能优势,毕竟从性价比是哪个来说,机械磁盘物美价廉,而它因易损坏而造成的可靠性差等缺陷,又有kafka在软件层面提供机制来保证,故使用普通机械磁盘是很划算的
关于磁盘选择另一个常常讨论的话题,到底是否应该使用磁盘阵列(raid)。使用磁盘阵列的两个优势在于:
提供冗余的磁盘存储空间提供负载均衡
以上两个优势对于任何一个分布式系统都很有吸引力。不过就kakfa而言,一方面kafka自己实现了冗余机制来提供高可靠性;另一方面通过分区的概念,kafka也能在软件层面自行实现负载均衡。如此一来磁盘阵列的优势就没有那么明显了,当然并不是说磁盘阵列不好,实际上依然有很多大厂是把确实是把kafka底层的存储交给磁盘阵列的,只是目前kafka在存储这方面提供了越来越便捷的高可靠性方案,因此在线上环境使用磁盘阵列似乎变得不那么重要了。综合以上的考量,个人给出的建议是:
追求性价比的公司可以不搭建磁盘阵列,使用普通磁盘组成存储空间即可。使用机械磁盘完全能够胜任kafka线上环境。
磁盘容量:
kafka集群到底需要多大的存储空间,这是一个非常经典的规划问题。kafka需要将消息保存在底层的磁盘上,这些消息默认会被保存一段时间然后自动被删除。虽然这段时间是可以配置的,但你应该如何结合自身业务场景和存储需求来规划kafka集群的存储容量呢?
我举一个简单的例子来说明如何思考这个问题,假设你所在公司有个业务每天需要向kafka集群发送1亿条消息,每条消息保存两份以防止数据丢失,另外消息默认保存两周时间。现在假设消息的平均大小是1KB,那么你能说出你的kafka集群需要为这个业务预留多少磁盘空间吗?
我们来计算一下,每天1亿条1KB大小的消息,保存两份且存两周的时间,那么总的空间大小就等于1亿 * 1KB * 2/ 1024 / 1024 。一般情况下,kafka集群除了消息数据还有其他类型的数据,比如索引数据等,因此我们需要再为这些数据预留出10%的磁盘空间,因此我们在原来的基础上乘上1.1,既然要保存两周,那么再乘上14,那么整体容量大概为21.5TB左右。由于kafka支持数据的压缩 ,假设数据的压缩比是0.75,那么最后你需要规划的存储空间是21.5 * 0.75=16.14TB左右。
总之在规划磁盘容量时你需要考虑下面这几个元素:
新增消息数消息留存时间平均消息大小备份数是否启用压缩
带宽:
对于kafka这种通过网络进行大量数据传输的框架而言,带宽特别容易成为瓶颈。事实上,在真实案例当中,带宽资源不足导致kafka出现性能问题的比例至少占60%以上。如果你的环境中还要涉及跨机房传输,那么情况情况可能更糟糕了。
如果你不是超级土豪的话,我会认为你使用的是普通的以太网,带宽也主要有两种:1Gbps的千兆网络,和10Gbps的万兆网络,特别是千兆网络应该是一般公司网络的标准配置了。下面我就以千兆网举一个实际的例子,来说明一下如何进行带宽资源的规划。
与其说是带宽资源的规划,其实真正要规划的是所需的kafka服务器的数量。假设你公司的机房环境是千兆网络,即1Gps,现在你有个业务,其业务目标或SLA是在1小时内处理1TB的业务数据。那么问题来了,你到底需要多少台kafka服务器来完成这个业务呢?
让我们来计算一下,由于带宽是1Gps,即每秒处理1Gb的数据,假设每台kafka服务器都是安装在专属的机器上,也就是说每台kafka机器上没有混布其他服务,但是真实环境中不建议这么做。通常情况下你只能假设kafka会用到70%的资源,因为总要为其他应用或者进程留一些资源。根据实际使用经验,超过70%的阈值就有网络丢包的可能性了,故70%的设定是一个比较合理的值,也就是说单台kafka服务器最多也就能使用700Mb的带宽资源。
稍等,这只是它能使用的最大带宽资源,你不能让kafka服务器常规性地使用这么多资源,故通常要再额外留出2/3的资源,即单台服务器使用带宽为700/3≈233MBps。需要提示的是,这里的2/3是相当保守的,你可以结合自己机器的使用情况酌情减少此值。
好了,有了240MBps,我们就可以计算1小时内处理1TB数据所需要的服务器数量了。根据这个目标,我们每秒需要处理1TB / 3600s * 8 ≈ 2336MB的数据,除以240,约等于10台服务器。如果消息还需要额外复制两份,那么总的服务器台数还要乘以3,即30台。

07.最最最重要的集群参数配置(上)
今天来聊聊最最最重要的 Kafka 集群配置。我这里用了 3 个“最”字并非哗众取宠,而是因为有些配置的重要性并未体现在官方文档中,并且从实际表现看,很多参数对系统的影响要比从文档上看更加明显,因此很有必要集中讨论一下。
我希望通过两节内容把这些重要的配置讲清楚。严格来说这些配置并不单单指 Kafka 服务器端的配置,其中既有 Broker 端参数,也有主题(后面我用我们更熟悉的 Topic 表示)级别的参数、JVM 端参数和操作系统级别的参数。下面我先从 Broker 端参数说起。
broker端参数
目前 Kafka Broker 提供了近 200 个参数,这其中绝大部分参数都不用你亲自过问。当谈及这些参数的用法时,网上的文章多是罗列出一些常见的参数然后一个一个地给出它们的定义,不过今天我打算换个方法,按照大的用途类别一组一组地介绍它们,希望可以更有针对性,也更方便你记忆。
首先 Broker 是需要配置存储信息的,即 Broker 使用哪些磁盘。那么针对存储信息的重要参数有以下这么几个:
log.dirs:这是非常重要的参数,指定了 Broker 需要使用的若干个文件目录路径。要知道这个参数是没有默认值的,这说明什么?这说明它必须由你亲自指定。log.dir:注意这是 dir,结尾没有 s,说明它只能表示单个路径,它是补充上一个参数用的。
这两个参数应该怎么设置呢?很简单,你只要设置log.dirs,即第一个参数就好了,不要设置log.dir。而且更重要的是,在线上生产环境中一定要为log.dirs配置多个路径,具体格式是一个 CSV 格式,也就是用逗号分隔的多个路径,比如/home/kafka1,/home/kafka2,/home/kafka3这样。如果有条件的话你最好保证这些目录挂载到不同的物理磁盘上。这样做有两个好处:
提升读写性能:比起单块磁盘,多块物理磁盘同时读写数据有更高的吞吐量。能够实现故障转移:能够实现故障转移:即 Failover。这是 Kafka 1.1 版本新引入的强大功能。要知道在以前,只要 Kafka Broker 使用的任何一块磁盘挂掉了,整个 Broker 进程都会关闭。但是自 1.1 开始,这种情况被修正了,坏掉的磁盘上的数据会自动地转移到其他正常的磁盘上,而且 Broker 还能正常工作。还记得上一期我们关于 Kafka 是否需要使用 RAID 的讨论吗?这个改进正是我们舍弃 RAID 方案的基础:没有这种 Failover 的话,我们只能依靠 RAID 来提供保障。
下面说说zookeeper的配置。首先 ZooKeeper 是做什么的呢?它是一个分布式协调框架,负责协调管理并保存 Kafka 集群的所有元数据信息,比如集群都有哪些 Broker 在运行、创建了哪些 Topic,每个 Topic 都有多少分区以及这些分区的 Leader 副本都在哪些机器上等信息。
Kafka 与 ZooKeeper 相关的最重要的参数当属zookeeper.connect。这也是一个 CSV 格式的参数,比如我可以指定它的值为zk1:2181,zk2:2181,zk3:2181。2181 是 ZooKeeper 的默认端口。现在问题来了,如果我让多个 Kafka 集群使用同一套 ZooKeeper 集群,那么这个参数应该怎么设置呢?这时候 chroot 就派上用场了。这个 chroot 是 ZooKeeper 的概念,类似于别名。
如果你有两套 Kafka 集群,假设分别叫它们 kafka1 和 kafka2,那么两套集群的zookeeper.connect参数可以这样指定:zk1:2181,zk2:2181,zk3:2181/kafka1和zk1:2181,zk2:2181,zk3:2181/kafka2。切记 chroot 只需要写一次,而且是加到最后的。我经常碰到有人这样指定:zk1:2181/kafka1,zk2:2181/kafka2,zk3:2181/kafka3,这样的格式是不对的。
第三组参数是与 Broker 连接相关的,即客户端程序或其他 Broker 如何与该 Broker 进行通信的设置。有以下三个参数:
listeners:学名叫监听器,其实就是告诉外部连接者要通过什么协议访问指定主机名和端口开放的 Kafka 服务。advertised.listeners:和 listeners 相比多了个 advertised。Advertised 的含义表示宣称的、公布的,就是说这组监听器是 Broker 用于对外发布的。host.name/port:列出这两个参数就是想说你把它们忘掉吧,压根不要为它们指定值,毕竟都是过期的参数了。
我们具体说说监听器的概念,从构成上来说,它是若干个逗号分隔的三元组,每个三元组的格式为<协议名称,主机名,端口号>。这里的协议名称可能是标准的名字,比如 PLAINTEXT 表示明文传输、SSL 表示使用 SSL 或 TLS 加密传输等;也可能是你自己定义的协议名字,比如CONTROLLER: //localhost:9092。
一旦你自己定义了协议名称,你必须还要指定listener.security.protocol.map参数告诉这个协议底层使用了哪种安全协议,比如指定listener.security.protocol.map=CONTROLLER:PLAINTEXT表示CONTROLLER这个自定义协议底层使用明文不加密传输数据。
至于三元组中的主机名和端口号则比较直观,不需要做过多解释。不过有个事情你还是要注意一下,经常有人会问主机名这个设置中我到底使用 IP 地址还是主机名。这里我给出统一的建议:最好全部使用主机名,即 Broker 端和 Client 端应用配置中全部填写主机名。 Broker 源代码中也使用的是主机名,如果你在某些地方使用了 IP 地址进行连接,可能会发生无法连接的问题。
第四组参数是关于 Topic 管理的。我来讲讲下面这三个参数:
auto.create.topics.enable:是否允许自动创建 Topic。unclean.leader.election.enable:是否允许 Unclean Leader 选举。auto.leader.rebalance.enable:是否允许定期进行 Leader 选举。
一个一个解释
auto.create.topics.enable参数我建议最好设置成 false,即不允许自动创建 Topic。在我们的线上环境里面有很多名字稀奇古怪的 Topic,我想大概都是因为该参数被设置成了 true 的缘故。你可能有这样的经历,要为名为 test 的 Topic 发送事件,但是不小心拼写错误了,把 test 写成了 tst,之后启动了生产者程序。恭喜你,一个名为 tst 的 Topic 就被自动创建了。所以我一直相信好的运维应该防止这种情形的发生,特别是对于那些大公司而言,每个部门被分配的 Topic 应该由运维严格把控,决不能允许自行创建任何 Topic。
第二个参数unclean.leader.election.enable是关闭 Unclean Leader 选举的。何谓 Unclean?还记得 Kafka 有多个副本这件事吗?每个分区都有多个副本来提供高可用。在这些副本中只能有一个副本对外提供服务,即所谓的 Leader 副本。那么问题来了,这些副本都有资格竞争 Leader 吗?显然不是,只有保存数据比较多的那些副本才有资格竞选,那些落后进度太多的副本没资格做这件事。好了,现在出现这种情况了:假设那些保存数据比较多的副本都挂了怎么办?我们还要不要进行 Leader 选举了?此时这个参数就派上用场了。如果设置成 false,那么就坚持之前的原则,坚决不能让那些落后太多的副本竞选 Leader。这样做的后果是这个分区就不可用了,因为没有 Leader 了。反之如果是 true,那么 Kafka 允许你从那些“跑得慢”的副本中选一个出来当 Leader。这样做的后果是数据有可能就丢失了,因为这些副本保存的数据本来就不全,当了 Leader 之后它本人就变得膨胀了,认为自己的数据才是权威的。这个参数在最新版的 Kafka 中默认就是 false,本来不需要我特意提的,但是比较搞笑的是社区对这个参数的默认值来来回回改了好几版了,鉴于我不知道你用的是哪个版本的 Kafka,所以建议你还是显式地把它设置成 false 吧。
第三个参数auto.leader.rebalance.enable的影响貌似没什么人提,但其实对生产环境影响非常大。设置它的值为 true 表示允许 Kafka 定期地对一些 Topic 分区进行 Leader 重选举,当然这个重选举不是无脑进行的,它要满足一定的条件才会发生。严格来说它与上一个参数中 Leader 选举的最大不同在于,它不是选 Leader,而是换 Leader!比如 Leader A 一直表现得很好,但若auto.leader.rebalance.enable=true,那么有可能一段时间后 Leader A 就要被强行卸任换成 Leader B。你要知道换一次 Leader 代价很高的,原本向 A 发送请求的所有客户端都要切换成向 B 发送请求,而且这种换 Leader 本质上没有任何性能收益,因此我建议你在生产环境中把这个参数设置成 false。
最后一组参数是数据留存方面的,即:
log.retention.{hour|minutes|ms}:这是个“三兄弟”,都是控制一条消息数据被保存多长时间。从优先级上来说 ms 设置最高、minutes 次之、hour 最低。log.retention.bytes:这是指定 Broker 为消息保存的总磁盘容量大小。message.max.bytes:控制 Broker 能够接收的最大消息大小。
先说这个“三兄弟”,虽然 ms 设置有最高的优先级,但是通常情况下我们还是设置 hour 级别的多一些,比如log.retention.hour=168表示默认保存 7 天的数据,自动删除 7 天前的数据。很多公司把 Kafka 当做存储来使用,那么这个值就要相应地调大。
其次是这个log.retention.bytes。这个值默认是 -1,表明你想在这台 Broker 上保存多少数据都可以,至少在容量方面 Broker 绝对为你开绿灯,不会做任何阻拦。这个参数真正发挥作用的场景其实是在云上构建多租户的 Kafka 集群:设想你要做一个云上的 Kafka 服务,每个租户只能使用 100GB 的磁盘空间,为了避免有个“恶意”租户使用过多的磁盘空间,设置这个参数就显得至关重要了。
最后说说message.max.bytes。实际上今天我和你说的重要参数都是指那些不能使用默认值的参数,这个参数也是一样,默认的 1000012 太少了,还不到 1MB。实际场景中突破 1MB 的消息都是屡见不鲜的,因此在线上环境中设置一个比较大的值还是比较保险的做法。毕竟它只是一个标尺而已,仅仅衡量 Broker 能够处理的最大消息大小,即使设置大一点也不会耗费什么磁盘空间的。
小结
再次强调一下,今天我和你分享的所有参数都是那些要修改默认值的参数,因为它们的默认值不适合一般的生产环境。当然,我并不是说其他 100 多个参数就不重要。事实上,在专栏的后面我们还会陆续提到其他的一些参数,特别是那些和性能息息相关的参数。所以今天我提到的所有参数,我希望作为一个最佳实践给到你,可以有的放矢地帮助你规划和调整你的 Kafka 生产环境。

08.最最最重要的集群参数配置(下)
今天我们继续来聊那些重要的 Kafka 集群配置,下半部分主要是 Topic 级别参数、JVM 参数以及操作系统参数的设置。
在上一节中,我们讨论了 Broker 端参数设置的一些法则,但其实 Kafka 也支持为不同的 Topic 设置不同的参数值。当前最新的 2.2 版本总共提供了大约 25 个 Topic 级别的参数,当然我们也不必全部了解它们的作用,这里我挑出了一些最关键的参数,你一定要把它们掌握清楚。除了 Topic 级别的参数,我今天还会给出一些重要的 JVM 参数和操作系统参数,正确设置这些参数是搭建高性能 Kafka 集群的关键因素。
Topic级别参数
说起 Topic 级别的参数,你可能会有这样的疑问:如果同时设置了 Topic 级别参数和全局 Broker 参数,到底听谁的呢?哪个说了算呢?答案就是 Topic 级别参数会覆盖全局 Broker 参数的值,而每个 Topic 都能设置自己的参数值,这就是所谓的 Topic 级别参数。
举个例子说明一下,上一期我提到了消息数据的留存时间参数,在实际生产环境中,如果为所有 Topic 的数据都保存相当长的时间,这样做既不高效也无必要。更适当的做法是允许不同部门的 Topic 根据自身业务需要,设置自己的留存时间。如果只能设置全局 Broker 参数,那么势必要提取所有业务留存时间的最大值作为全局参数值,此时设置 Topic 级别参数把它覆盖,就是一个不错的选择。
下面我们依然按照用途分组的方式引出重要的 Topic 级别参数。从保存消息方面来考量的话,下面这组参数是非常重要的:
retention.ms:规定了该 Topic 消息被保存的时长。默认是 7 天,即该 Topic 只保存最近 7 天的消息。一旦设置了这个值,它会覆盖掉 Broker 端的全局参数值。retention.bytes:规定了要为该 Topic 预留多大的磁盘空间。和全局参数作用相似,这个值通常在多租户的 Kafka 集群中会有用武之地。当前默认值是 -1,表示可以无限使用磁盘空间。
上面这些是从保存消息的维度来说的。如果从能处理的消息大小这个角度来看的话,有一个参数是必须要设置的,即max.message.bytes。它决定了 Kafka Broker 能够正常接收该 Topic 的最大消息大小。我知道目前在很多公司都把 Kafka 作为一个基础架构组件来运行,上面跑了很多的业务数据。如果在全局层面上,我们不好给出一个合适的最大消息值,那么不同业务部门能够自行设定这个 Topic 级别参数就显得非常必要了。在实际场景中,这种用法也确实是非常常见的。
好了,你要掌握的 Topic 级别的参数就这么几个。下面我来说说怎么设置 Topic 级别参数吧。其实说到这个事情,我是有点个人看法的:我本人不太赞同那种做一件事情开放给你很多种选择的设计方式,看上去好似给用户多种选择,但实际上只会增加用户的学习成本。特别是系统配置,如果你告诉我只能用一种办法来做,我会很努力地把它学会;反之,如果你告诉我说有两种方法甚至是多种方法都可以实现,那么我可能连学习任何一种方法的兴趣都没有了。Topic 级别参数的设置就是这种情况,我们有两种方式可以设置:
创建 Topic 时进行设置修改 Topic 时设置
我们先来看看如何在创建 Topic 时设置这些参数。我用上面提到的retention.ms和max.message.bytes举例。设想你的部门需要将交易数据发送到 Kafka 进行处理,需要保存最近半年的交易数据,同时这些数据很大,通常都有几 MB,但一般不会超过 5MB。现在让我们用以下命令来创建 Topic:
bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --topic transaction --partitions 1 --replication-factor 1 --config retention.ms=15552000000 --config max.message.bytes=5242880我们只需要知道 Kafka 开放了kafka-topics命令供我们来创建 Topic 即可。对于上面这样一条命令,请注意结尾处的--config设置,我们就是在 config 后面指定了想要设置的 Topic 级别参数。
下面看看使用另一个自带的命令kafka-configs来修改 Topic 级别参数。假设我们现在要发送最大值是 10MB 的消息,该如何修改呢?命令如下:
bin/kafka-configs.sh --zookeeper localhost:2181 --entity-type topics --entity-name transaction --alter --add-config max.message.bytes=10485760总体来说,你只能使用这么两种方式来设置 Topic 级别参数。我个人的建议是,你最好始终坚持使用第二种方式来设置,并且在未来,Kafka 社区很有可能统一使用kafka-configs脚本来调整 Topic 级别参数。
JVM参数
我在专栏前面提到过,Kafka 服务器端代码是用 Scala 语言编写的,但终归还是编译成 Class 文件在 JVM 上运行,因此 JVM 参数设置对于 Kafka 集群的重要性不言而喻。
首先我先说说 Java 版本,我个人极其不推荐将 Kafka 运行在 Java 6 或 7 的环境上。Java 6 实在是太过陈旧了,没有理由不升级到更新版本。另外 Kafka 自 2.0.0 版本开始,已经正式摒弃对 Java 7 的支持了,所以有条件的话至少使用 Java 8 吧。
首说到 JVM 端设置,堆大小这个参数至关重要。虽然在后面我们还会讨论如何调优 Kafka 性能的问题,但现在我想无脑给出一个通用的建议:将你的 JVM 堆大小设置成 6GB 吧,这是目前业界比较公认的一个合理值。我见过很多人就是使用默认的 Heap Size 来跑 Kafka,说实话默认的 1GB 有点小,毕竟 Kafka Broker 在与客户端进行交互时会在 JVM 堆上创建大量的 ByteBuffer 实例,Heap Size 不能太小。
JVM 端配置的另一个重要参数就是垃圾回收器的设置,也就是平时常说的 GC 设置。如果你依然在使用 Java 7,那么可以根据以下法则选择合适的垃圾回收器:
如果 Broker 所在机器的 CPU 资源非常充裕,建议使用 CMS 收集器。启用方法是指定-XX:+UseCurrentMarkSweepGC否则,使用吞吐量收集器。开启方法是指定-XX:+UseParallelGC
当然了,如果你已经在使用 Java 8 了,那么就用默认的 G1 收集器就好了。在没有任何调优的情况下,G1 表现得要比 CMS 出色,主要体现在更少的 Full GC,需要调整的参数更少等,所以使用 G1 就好了。
现在我们确定好了要设置的 JVM 参数,我们该如何为 Kafka 进行设置呢?有些奇怪的是,这个问题居然在 Kafka 官网没有被提及。其实设置的方法也很简单,你只需要设置下面这两个环境变量即可:
KAFKA_HEAP_OPTS:指定堆大小。KAFKA_JVM_PERFORMANCE_OPTS:指定 GC 参数。
比如你可以这样启动 Kafka Broker,即在启动 Kafka Broker 之前,先设置上这两个环境变量:
$> export KAFKA_HEAP_OPTS=--Xms6g --Xmx6g
$> export KAFKA_JVM_PERFORMANCE_OPTS= -server -XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:+ExplicitGCInvokesConcurrent -Djava.awt.headless=true
$> bin/kafka-server-start.sh config/server.properties操作系统参数
最后我们来聊聊 Kafka 集群通常都需要设置哪些操作系统参数。通常情况下,Kafka 并不需要设置太多的 OS 参数,但有些因素最好还是关注一下,比如下面这几个:
文件描述符限制文件系统类型Swappiness提交时间
首先是ulimit -n。我觉得任何一个 Java 项目最好都调整下这个值。实际上,文件描述符系统资源并不像我们想象的那样昂贵,你不用太担心调大此值会有什么不利的影响。通常情况下将它设置成一个超大的值是合理的做法,比如ulimit -n 1000000。还记得电影《让子弹飞》里的对话吗:“你和钱,谁对我更重要?都不重要,没有你对我很重要!”。这个参数也有点这么个意思。其实设置这个参数一点都不重要,但不设置的话后果很严重,比如你会经常看到“Too many open files”的错误。
其次是文件系统类型的选择。这里所说的文件系统指的是如 ext3、ext4 或 XFS 这样的日志型文件系统。根据官网的测试报告,XFS 的性能要强于 ext4,所以生产环境最好还是使用 XFS。
第三是 swap 的调优。网上很多文章都提到设置其为 0,将 swap 完全禁掉以防止 Kafka 进程使用 swap 空间。我个人反倒觉得还是不要设置成 0 比较好,我们可以设置成一个较小的值。为什么呢?因为一旦设置成 0,当物理内存耗尽时,操作系统会触发 OOM killer 这个组件,它会随机挑选一个进程然后 kill 掉,即根本不给用户任何的预警。但如果设置成一个比较小的值,当开始使用 swap 空间时,你至少能够观测到 Broker 性能开始出现急剧下降,从而给你进一步调优和诊断问题的时间。基于这个考虑,我个人建议将 swappniess 配置成一个接近 0 但不为 0 的值,比如 1。
最后是提交时间或者说是 Flush 落盘时间。向 Kafka 发送数据并不是真要等数据被写入磁盘才会认为成功,而是只要数据被写入到操作系统的页缓存(Page Cache)上就可以了,随后操作系统根据 LRU 算法会定期将页缓存上的“脏”数据落盘到物理磁盘上。这个定期就是由提交时间来确定的,默认是 5 秒。一般情况下我们会认为这个时间太频繁了,可以适当地增加提交间隔来降低物理磁盘的写操作。当然你可能会有这样的疑问:如果在页缓存中的数据在写入到磁盘前机器宕机了,那岂不是数据就丢失了。的确,这种情况数据确实就丢失了,但鉴于 Kafka 在软件层面已经提供了多副本的冗余机制,因此这里稍微拉大提交间隔去换取性能还是一个合理的做法。
小结
今天我和你分享了关于 Kafka 集群设置的各类配置,包括 Topic 级别参数、JVM 参数以及操作系统参数,连同上一篇一起构成了完整的 Kafka 参数配置列表。我希望这些最佳实践能够在你搭建 Kafka 集群时助你一臂之力,但切记配置因环境而异,一定要结合自身业务需要以及具体的测试来验证它们的有效性。
