https://blog.csdn.net/weixin_33690963/article/details/91698279
kafka序列化: 生产者在将消息传入kafka之前需要将其序列化成byte, 如原来消息的value是Thrift 的一个struct类型,需先将其自定义序列化.
kafka反序列化: 消费者从kafka中获取数据之后需将拿到的数据反序列化, 才能进行相关的业务逻辑处理.
一 . 相关函数:
ConsumerRecords API:
ConsumerRecord API用于从Kafka集群接收记录。 此API由主题名称,分区号(从中接收记录)和指向Kafka分区中的记录的偏移量组成。ConsumerRecord类用于创建具有特定主题名称,分区计数和< key,value>的消费者记录。 对。 它有以下签名。
public ConsumerRecord(string topic,int partition, long offset,K key, V value)
-
主题 - 从Kafka集群接收的使用者记录的主题名称。
-
分区 - 主题的分区。
-
键 - 记录的键,如果没有键存在null将被返回。
-
值 - 记录内容。
ConsumerRecords API充当ConsumerRecord的容器。 此API用于保存特定主题的每个分区的ConsumerRecord列表。 它的构造器定义如下。
public ConsumerRecords(java.util.Map<TopicPartition,java.util.List <Consumer-Record>K,V>>> records)
-
- TopicPartition - 返回特定主题的分区地图。
- 记录 - ConsumerRecord的返回列表。
二. 序列化
1. 传统的序列化

很明显这种序列化有一个问题,虽然能满足append的存储模式,但无法从中读取第n个对象,每次得从第一个开始读。
kafka作为一种C-S架构,C端需要和S端进行通信,批量向S端传送序列化的对象,达到batch.size(8K)或者时间达到linger.ms(5ms)向server端传送数据,据此推断C端和S端的通信应该使用的是长连接,而不会是每次传送数据打开一个socket,并且还支持压缩,高效稳定的通信和存储是这类软件必备的特质之一。
2. 事务提交


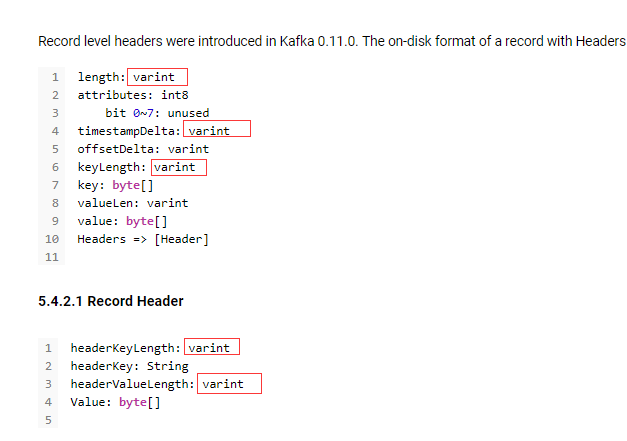
可以看出key和value都被序列化为byte[],每跳过length个byte就是跳过了一组key-value,因此可以根据这个进行寻找第offset个key-value
如何将一个Object序列化为byte[] ,很明显需将Object的所有字段进行序列化,进而最终转化为基本数据类型和String等的序列化。
以下是将Double进行序列化和反序列化

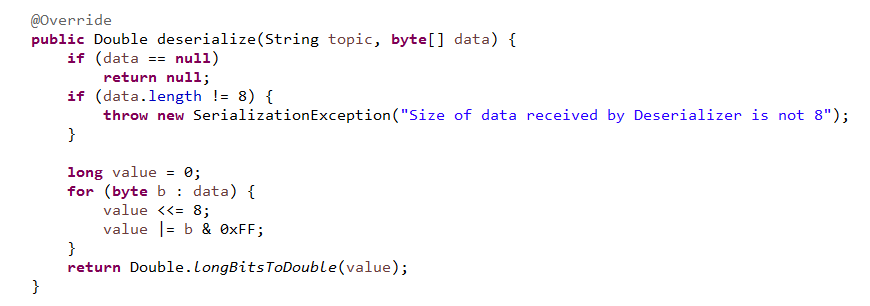
相比较而言使用kafka的序列化,一个Double占用8个字节,
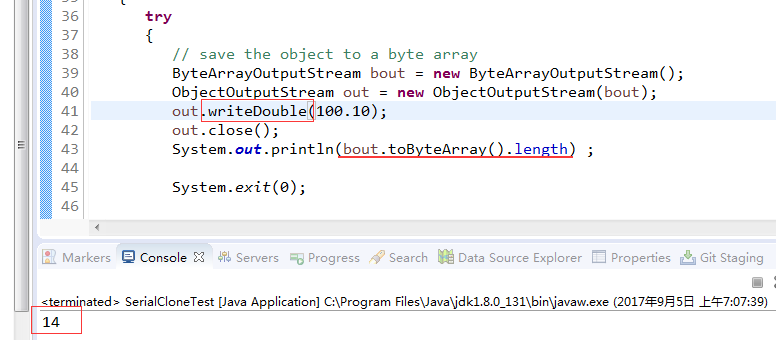
而使用writeDouble进行序列化则占用了14个字节
而使用writeObject进行序列化则占用了84个字节。务必请慎用,占用大量字节,进而占内存和带宽。。。
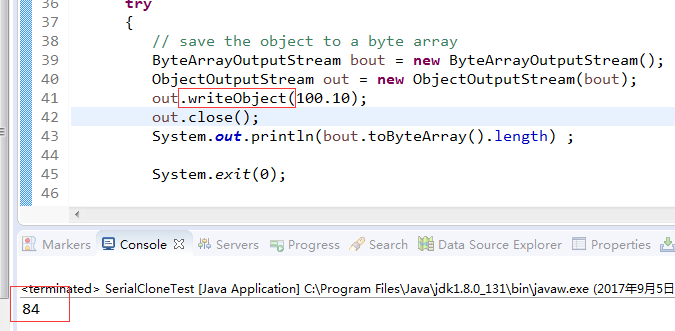
也许序列化的本质就是将对象转换为可识别的字节流。
有时会想为什么不这样存储?
key1
value1
key2
value2
key3
value3
首先这种存储面临一个问题, 换行回车符号需进行转义存储。二是这种存储和读取高效么,一行一行进行处理。仅仅是推测,具体实现是不是这样没有考究。一行一行的读取无非是一个一个字节的读取,读到\n便是一行,这种读取方式应该不是很高明。