1. mongodb是什么?
NoSQL 非关系型数据库,主要用于数据的海量存储。分为server数据存储端和client数据操作端。
关系型与非关系型数据库的区别?
sql:数据库--表--数据
nosql:数据库---集合--文档
2.mongoddb优势
1. 扩展性
2. 大数据型,高性能
3. 灵活的数据模型
3.启动
1. 本地测试启动:功能受限,验证数据库的完整功能
+ ps aux|grep mongodb
+ ps -- process 进程
+ ps aux 显示所有进程
+ grep --- 文件查询
+ grep "#" /etc/mongodb.conf --- 把文件中所有带被注释的行显示出来
+ grep -v "#" /etc/mongodb.conf --- 把文件中所有有用的行显示出来
sudo service mongodb start
sudo service mongodb stop
2. 生产方式启动:
4.使用
4.1 数据库的操作
查看当前数据库: db 默认为test
查看磁盘上的数据库: show dbs/ show databases
注:db --- > test ---> show dbs ---> local 0.000GB 是因为test数据库不在磁盘上,在内存中。
4.2. 创建数据库
1.use python
2.db.test.insert({"key":"value"})
3.show dbs ---> python
4.3 删除数据库
db.dropDatabase()
4.4 集合的操作
1.选择要使用的数据库 use new
2.db.createCollection("new_col") 如果new这个数据库存在就在里面创建集合,如果数据库不存在,就先创建数据库new,然后在创建集合
默认是无限容量:cap:true
3.show dbs
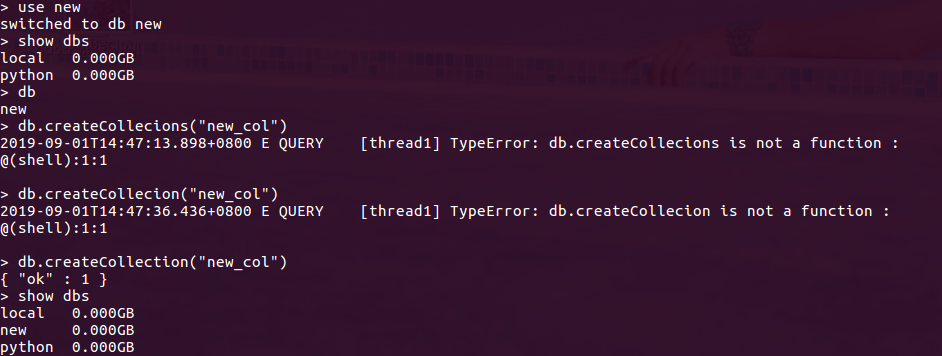
4.db.new_col 查看集合
5.db.new_col.insert({"a":"1"}) 指定集合插入数据
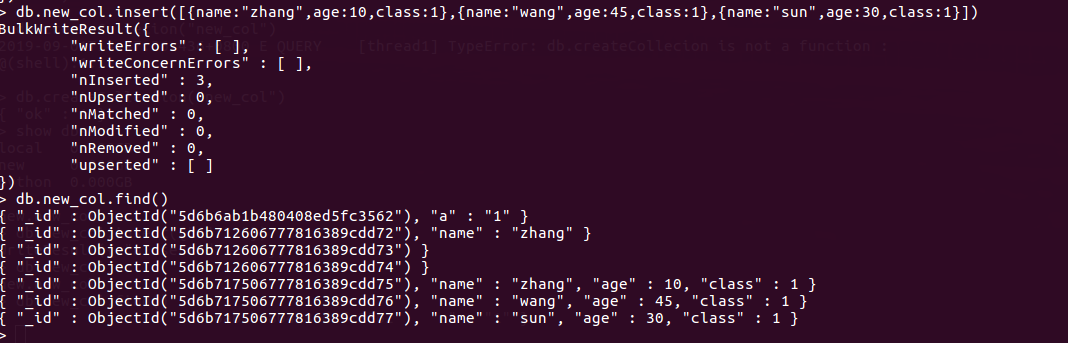
6.db.new_col.find() 查看指定集合的数据

说明:集合会自动插入一条id的字段,是一个十二位的十六进数。
前八位:5d6b6ab1是时间戳
接着六位:b48040 机器码,唯一标记机器
接着四位:8ed5 是进程号
最后六位:是简单的增量值
4.4 数据的增删改查
批量插入数据
[{ } , { } , { }]
db.new_col.insert([{name:"zhang",age:10,class:1},{name:"wang",age:11,class:1},{name:"sun",age:12,class:1}])
修改数据 --- 修改数据的依据是通过 "_id"的值取找,找到了之后,在id后面的字段判断值是否一致,不一致,把新的值覆盖原来的值。
db.new_col.save({"_id" : ObjectId("5d6b717506777816389cdd77"),"name":"mongo","age":100,"class":100})

如果:通过id值找不到,就会将后面的值作为新地值插入,id的值为查找的id的值。
查询数据
一般查询:db.new_col.find()
条件查询:
# 新插入一组数,进行演示。
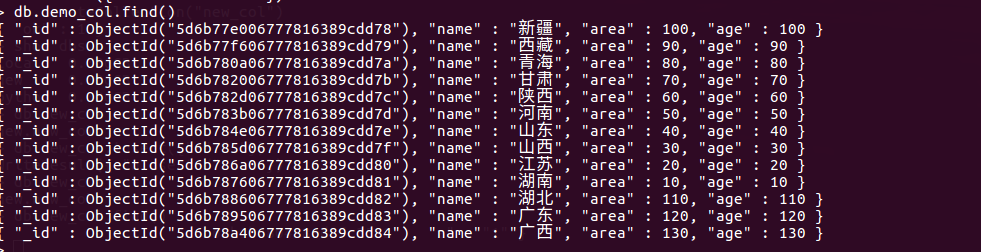
db.demo_col.findOne()

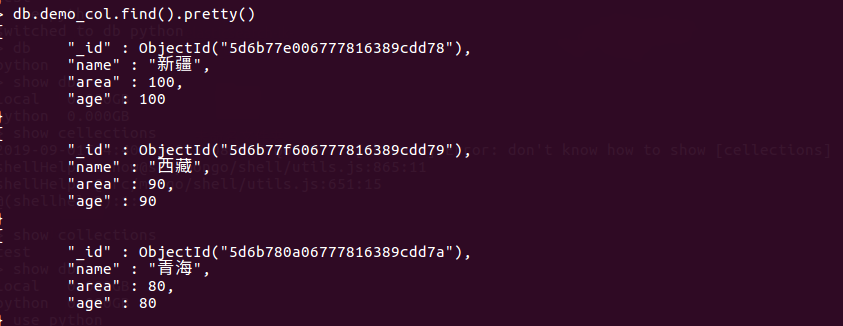
db.demo_col.find().pretty() 展示部分截图
1. 等于查询
db.demo_col.find({age:10})

2. 大于查询
db.demo_col.find({age:{$gt:50}}) $get 大于等于 $lt 小于 $lte小于等于

4. 不等于查询
db.demo_col.find({age:{$ne:50}})
5. and查询
db.demo_col.find({$and:[{area:{$gte:100}},{age:{$ne:110}}]})
