1.线程
在传统操作系统中,每个进程有一个地址空间,而且默认就有一个控制线程
线程顾名思义,就是一条流水线工作的过程,一条流水线必须属于一个车间,一个车间的工作过程是一个进程
车间负责把资源整合到一起,是一个资源单位,而一个车间内至少有一个流水线
流水线的工作需要电源,电源就相当于cpu
所以,进程只是用来把资源集中到一起(进程只是一个资源单位,或者说资源集合),而线程才是cpu上的执行单位。
多线程(即多个控制线程)的概念是,在一个进程中存在多个控制线程,多个控制线程共享该进程的地址空间,相当于一个车间内有多条流水线,都共用一个车间的资源。
例如,北京地铁与上海地铁是不同的进程,而北京地铁里的13号线是一个线程,北京地铁所有的线路共享北京地铁所有的资源,比如所有的乘客可以被所有线路拉。
所以我们之间学的进程起始根本就不是一个执行单位,进程其实是一个资源单位,每个进程内都自带一个线程,线程才是真正的执行单位
2.创建线程的开销远比进程要小
创建进程的开销要远大于线程?
如果我们的软件是一个工厂,该工厂有多条流水线,流水线工作需要电源,电源只有一个即cpu(单核cpu)
一个车间就是一个进程,一个车间至少一条流水线(一个进程至少一个线程)
创建一个进程,就是创建一个车间(申请空间,在该空间内建至少一条流水线)
而建线程,就只是在一个车间内造一条流水线,无需申请空间,所以创建开销小
进程之间是竞争关系,线程之间是协作关系?
车间(进程)之间是竞争/抢电源的关系,竞争(不同的进程直接是竞争关系,是不同的程序员写的程序运行的,迅雷抢占其他进程的网速,360把其他进程当做病毒干死)
一个车间的不同流水线式协同工作的关系(同一个进程的线程之间是合作关系,是同一个程序写的程序内开启动,迅雷内的线程是合作关系,不会自己干自己)
3.线程与进程之间的区别
- Threads share the address space of the process that created it; processes have their own address space.
- Threads have direct access to the data segment of its process; processes have their own copy of the data segment of the parent process.
- Threads can directly communicate with other threads of its process; processes must use interprocess communication to communicate with sibling processes.
- New threads are easily created; new processes require duplication of the parent process.
- Threads can exercise considerable control over threads of the same process; processes can only exercise control over child processes.
- Changes to the main thread (cancellation, priority change, etc.) may affect the behavior of the other threads of the process; changes to the parent process does not affect child processes.
4.为何要用多线程
多线程指的是,在一个进程中开启多个线程,简单的讲:如果多个任务共用一块地址空间,那么必须在一个进程内开启多个线程。详细的讲分为4点:
1. 多线程共享一个进程的地址空间
2. 线程比进程更轻量级,线程比进程更容易创建可撤销,在许多操作系统中,创建一个线程比创建一个进程要快10-100倍,在有大量线程需要动态和快速修改时,这一特性很有用
3. 若多个线程都是cpu密集型的,那么并不能获得性能上的增强,但是如果存在大量的计算和大量的I/O处理,拥有多个线程允许这些活动彼此重叠运行,从而会加快程序执行的速度。
4. 在多cpu系统中,为了最大限度的利用多核,可以开启多个线程,比开进程开销要小的多。(这一条并不适用于python)
5.进一步理解多线程概念
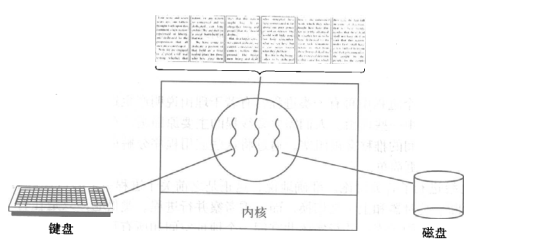
开启一个字处理软件进程,该进程肯定需要办不止一件事情,比如监听键盘输入,处理文字,定时自动将文字保存到硬盘,这三个任务操作的都是同一块数据,因而不能用多进程。只能在一个进程里并发地开启三个线程,如果是单线程,那就只能是,键盘输入时,不能处理文字和自动保存,自动保存时又不能输入和处理文字。
6.创建线程的两种方式


from threading import Thread import time def task(): print('running now') time.sleep(3) if __name__ == '__main__': t=Thread(target=task) t.start() print('主线程运行完毕') #是不是优点似曾相识的感觉~~~
from threading import Thread import time class Mythread(Thread): def run(self): print('running') time.sleep(3) if __name__ == '__main__': t=Thread() t.start() print('主线程运行完毕')
7.进一步理解守护进程的概念
from multiprocessing import Process,JoinableQueue#队列的一种,有自动计数队列中存—放数据个数,可解决多个生产消费者导致程序无法结束的情况 import time,random def producer(name,food,q): for i in range(5): res='%s%s'%(food,i) time.sleep(random.randint(1,3)) q.put(res) print('%s 生产了 %s'%(name,res)) q.task_done() #每次取都向q.join()发出信号,q.join()统计记录 def consumer(name,q): while True: res=q.get() if res==None: print('没货啦!!!') break time.sleep(random.randint(1,3)) print('%s 消费了 %s'%(name,res)) if __name__ == '__main__': q=JoinableQueue() p1=Process(target=producer,args=('egon','包子',q)) p2 = Process(target=producer, args=('杨军', '包子', q)) p3 = Process(target=producer, args=('lxx', '包子', q)) c1=Process(target=consumer,args=('alex',q)) c2= Process(target=consumer, args=('wuxx', q)) c1.daemon=True c2.daemon=True p1.start() p2.start() p3.start() c1.start() c2.start() #保证生产者全部生产完毕 p1.join() p2.join() p3.join() #在生产者生产完所有数据后,记录队列总个数,直到队列取空这行代码才会运行结束 q.join() print('主运行完毕') #这里的消费者全都被定义成了守护进程
from threading import Thread import time def foo(): print(123) time.sleep(1) print("end123") def bar(): print(456) time.sleep(3) print("end456") t1=Thread(target=foo) t2=Thread(target=bar) t1.daemon=True t1.start() t2.start() print("main-------")
守护进程和守护线程咋一看好像有点不一样,起始本质都是一样的:守护的真正涵义在于,只要一个进程或线程中不再有可执行的代码,守护者就被清除
本质:需要搞明白的是进程与进程之间是不同的内存空间,同一进程下的多个线程处于同一个内存空间,守护本质是守护同一个内存空间中无可执行代码~~~这样就很好理解,为什么守护进程在主进程代码读取完毕即立刻终止,而守护线程会等到同一进程下的所有非守护线程执行完毕才会终止运行,本质都是等同一空间下再无可执行代码!
无论是进程还是线程,都遵循:守护xxx会等待主xxx运行完毕后被销毁 需要强调的是:运行完毕并非终止运行 #1.对主进程来说,运行完毕指的是主进程代码运行完毕 #2.对主线程来说,运行完毕指的是主线程所在的进程内所有非守护线程统统运行完毕,主线程才算运行完毕 详细解释: #1 主进程在其代码结束后就已经算运行完毕了(守护进程在此时就被回收),然后主进程会一直等非守护的子进程都运行完毕后回收子进程的资源(否则会产生僵尸进程),才会结束, #2 主线程在其他非守护线程运行完毕后才算运行完毕(守护线程在此时就被回收)。因为主线程的结束意味着进程的结束,进程整体的资源都将被回收,而进程必须保证非守护线程都运行完毕后才能结束。
8.互斥锁与递归锁
from threading import Thread,Lock import time x=100 def task(metux): global x mutex.acquire() temp=x time.sleep(0.1) x=temp-1 mutex.release() if __name__ == '__main__': start=time.time() mutex=Lock() t_l=[] for i in range(10): t=Thread(target=task,args=(mutex,)) t_l.append(t) t.start() for t in t_l: t.join() print('主',x) print(time.time()-start)
进程也有死锁与递归锁,在进程那里忘记说了,放到这里一切说了额
所谓死锁: 是指两个或两个以上的进程或线程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程,如下就是死锁
from threading import Thread,Lock import time mutexA=Lock() mutexB=Lock() class MyThread(Thread): def run(self): self.func1() self.func2() def func1(self): mutexA.acquire() print('\033[41m%s 拿到A锁\033[0m' %self.name) mutexB.acquire() print('\033[42m%s 拿到B锁\033[0m' %self.name) mutexB.release() mutexA.release() def func2(self): mutexB.acquire() print('\033[43m%s 拿到B锁\033[0m' %self.name) time.sleep(2) mutexA.acquire() print('\033[44m%s 拿到A锁\033[0m' %self.name) mutexA.release() mutexB.release() if __name__ == '__main__': for i in range(10): t=MyThread() t.start() ''' Thread-1 拿到A锁 Thread-1 拿到B锁 Thread-1 拿到B锁 Thread-2 拿到A锁 然后就卡住,死锁了 '''
解决方法,递归锁,在Python中为了支持在同一线程中多次请求同一资源,python提供了可重入锁RLock。
这个RLock内部维护着一个Lock和一个counter变量,counter记录了acquire的次数,从而使得资源可以被多次require。直到一个线程所有的acquire都被release,其他的线程才能获得资源。上面的例子如果使用RLock代替Lock,则不会发生死锁:
from threading import Thread,RLock import time mutexA=mutexB=RLock() class MyThread(Thread): def run(self): self.f1() self.f2() def f1(self): mutexA.acquire() print('%s 拿到了A锁' %self.name) mutexB.acquire() print('%s 拿到了B锁' %self.name) mutexB.release() mutexA.release() def f2(self): mutexB.acquire() print('%s 拿到了B锁' %self.name) time.sleep(0.1) mutexA.acquire() print('%s 拿到了A锁' %self.name) mutexA.release() mutexB.release() if __name__ == '__main__': for i in range(10): t=MyThread() t.start() print('主') mutexA=mutexB=threading.RLock() #一个线程拿到锁,counter加1,该线程内又碰到加锁的情况,则counter继续加1,这期间所有其他线程都只能等待,等待该线程释放所有锁,即counter递减到0为止
小提示一下,上面的递归锁里锁A和锁B是一把锁,做了链式赋值,只是为了让演示效果更明显一点!
9.信号量
信号量这个词看上去很高大上,容我来解释一下就知道它有多low了,我们先来回忆一下互斥锁,相当于一间房子里只有一个厕所,多个人去争抢一把锁,而信号量就相当于公共厕所~~~你懂的,一个公共厕所有多个坑,也就意味着它可以产出多个锁,
同进程的一样
Semaphore管理一个内置的计数器,
每当调用acquire()时内置计数器-1;
调用release() 时内置计数器+1;
计数器不能小于0;当计数器为0时,acquire()将阻塞线程直到其他线程调用release()。
实例:(同时只有5个线程可以获得semaphore,即可以限制最大连接数为5):
from threading import Thread,Semaphore import threading import time # def func(): # if sm.acquire(): # print (threading.currentThread().getName() + ' get semaphore') # time.sleep(2) # sm.release() def func(): sm.acquire() print('%s get sm' %threading.current_thread().getName()) time.sleep(3) sm.release() if __name__ == '__main__': sm=Semaphore(5) for i in range(23): t=Thread(target=func) t.start()
与进程池是完全不同的概念,进程池Pool(4),最大只能产生4个进程,而且从头到尾都只是这四个进程,不会产生新的,而信号量是产生一堆线程/进程
详细:http://url.cn/5DMsS9r