第一;先说传参方式,一共有两种
JasperRunManager.runReportToPdfStream(is, servletOutputStream, map, data2); //1; 上面参数中的map,对应pdf中的Parmeter参数 //2; datasouce,参数中的第四位,对应pdf中的参数2,fields //map在官方解释中类似于sql的查询条件,DataSource就是具体的查询结果数据
第二;具体的数据参数形式
map,就是普通的hashmap就可以
//1;map,就是普通的hashmap就可以 HashMap map = new HashMap(); //传参对应方式 map(“”,XXX) //XXX可以是数据库,也可以是list,也可以是单个数据 //数据库 //要传入datasouce类型,获取的时候可以使用 使用方式 在ireport 组件list中使用 $P{REPORT_PARAMETERS_MAP}.get("XXX")直接获取 //表达式填入,图四 list //传入list,便利循环的时候要使用datasouce对应的格式转换 //要创建一个list field,然后更改这个field属性,图三我选择的是第一个 使用方式一 在ireport 组件list中使用,由于创建list时,就会自动附带subDataSource 所以在subDataSource其中的fields中加入传入的相应字段 //下面就是传入的是list<map>类型 new net.sf.jasperreports.engine.data.JRMapCollectionDataSource($P{list}) //表达式填入,图四 使用方式二 自行遍历使用 //单个数据 //直接在parameter加入相应元素,在页面使用$P{}使用
datasouce
//2; DataSource,数据库类型 //根据不同的传参数据类型主要是用的有几种形式 //a; 这个是list<bean>可以使用的 List<Bean> list = null; JRDataSource data = new JRBeanCollectionDataSource(list); //b; 这个是map[]可以使用的,这个map[0]中的数据主要用来对应图中的2的fields HashMap[] reportRows = new HashMap[1]; HashMap map = new HashMap(); reportRows[0] = map; //这个是map[]可以使用的 JRDataSource data2 = new JRMapArrayDataSource(reportRows); //c; 这个是list[Map]可以使用的 List<Map<>> list = null; JRDataSource data2 = new JRMapCollectionDataSource(reportRows);
第三,业务代码
try { //获取输出流 ServletOutputStream servletOutputStream = response.getOutputStream(); //文件名称位置 String pathName = "/report/reportallotment.jasper"; //获取资源 Resource resource = new ClassPathResource(pathName); //获取文件的输入流 InputStream is = resource.getInputStream(); //放入参数 JasperRunManager.runReportToPdfStream(is, servletOutputStream, map, data2); response.setContentType("application/pdf"); response.setHeader("content-disposition", "attachment;filename=report.pdf"); servletOutputStream.flush(); servletOutputStream.close(); return null; } catch (Exception e) { StringWriter stringWriter = new StringWriter(); PrintWriter printWriter = new PrintWriter(stringWriter); e.printStackTrace(printWriter); response.setContentType("text/plain"); try { response.getOutputStream().print(stringWriter.toString()); } catch (IOException e1) { e1.printStackTrace(); } } return null;
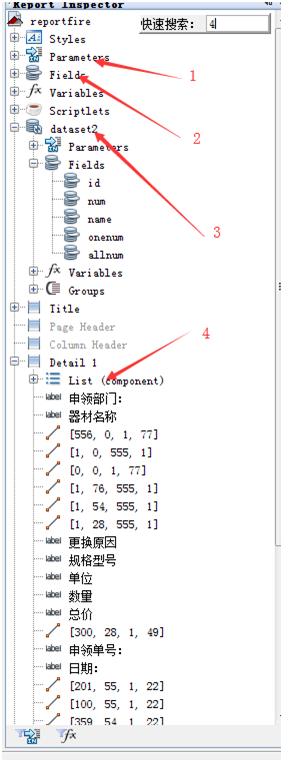
图一

图二
dataset2在打印过程中没有实际意义,它所具有的fields可以直接都写入2中的fields,
如果是子报表则需要
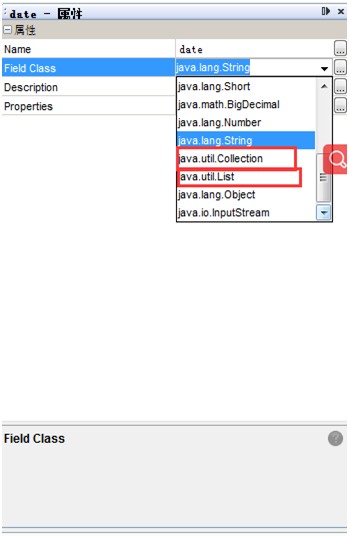
图三
我这里图中list的表达式

图四
注意,get()方法并不是获取了dataset2数据库的结果,而是我在后台传入的map中添加了这个参数
JRDataSource data = new JRBeanCollectionDataSource(list);map.put("dataset2", data);
list中的bean要与dataset2中的fields对应