Hive是什么?
- Hive是基于Hadoop之上的数据仓库;
- Hive是一种可以存储、查询、分析存储在hadoop中的大规模数据
- Hive定义了简单的类SQL查询语言,成为HQL,它允许熟悉SQL的用户查询数据
- 允许熟悉MapReduce开发者的开发自定义的mapper和reducer来处理内建的mapper和reducer无法完成的复杂的分析工作
- Hive没有专门的数据格式
- Hive:数据仓库。
- Hive:解释器,编译器,优化器等。
- Hive运行时,元数据存储在关系型数据库里面。
1. 为什么选择Hive
- 基于Hadoop的大数据的计算/扩展能力
- 支持SQL like查询语言
- 统一的元数据管理
- 简单编程
2.Hive内部是什么
Hive是建立在Hadoop上的数据仓库基础架构。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。Hive定义了简单的类SQL查询语言,称为QL,它允许熟悉SQL的用户查询数据。同时,这个语言也允许熟悉MapReduce开发者的开发自定义的mapper和reducer来处理内建的mapper和reducer无法完成的复杂的分析工作。
本质上讲,Hive是一个SQL解析引擎,Hive可以把SQL查询转换为MapReduce中的job来运行。Hive有一套映射工具,可以把SQL转换为MapReduce中的job,可以把SQL中的表、字段转换为HDFS中的文件(夹)以及文件中的列。这套映射工具称之为metastore,一般存放在derby、mysql中。
Hive是SQL解析引擎,它将SQL语句转译成M/R Job然后在Hadoop执行。
Hive的表其实就是HDFS的目录/文件,按表名把文件夹分开。如果是分区表,则分区值是子文件夹,可以直接在M/R Job里使用这些数据。
Hive在hdfs中的默认位置是/user/hive/warehouse
3. Hive的系统架构


- 用户接口
主要有3个:包括CLI,JDBC/ODBC,WebUI。
CLI,即Shell命令行;
JDBC/ODBC是Hive的Java,与使用传统数据库JDBC的方式类似
WebGUI是通过浏览器访问Hive
- 元数据存储
通常是存储在关系数据库如mysql,derby中。Hive将元数据存储在数据库中(metastore),目前只支持mysql,derby。Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
- 解释器、编译器、优化器、执行器
完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在HDFS中,并在随后有MapReduce调用执行。Hive的数据存储在HDFS中,大部分的查询由MapReduce完成(包含*的查询,比如select * from table不会生成MapReduce任务)
- Hadoop
用HDFS进行存储,利用MapReduce进行计算。
- HIVE的架构
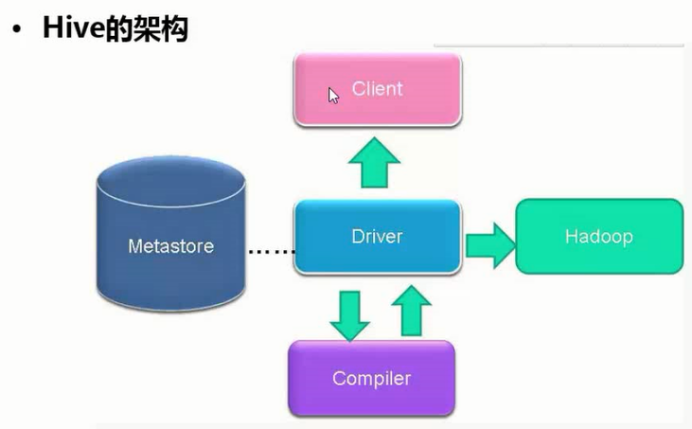
Hive的架构:
——编译器(compiler)将一个Hive QL转换操作符
——操作符是Hive的最小的处理单元
——每个操作符代表HDFS的一个操作或者一道MapReduce作业
Hive的三种模式:
——local模式,此模式连接到一个In-memory的数据块Derby,一般用于Unit Test.
——单用户模式,通过网络连接到一个数据库中,是最经常使用到的模式
——多用户模式,或者远程服务器模式。 用于非Java客户端访问元数据库,在服务器端启动MetaStoreServer,客户端利用Thrift协议通过MetaStoreServer访问元数据库。
local模式:
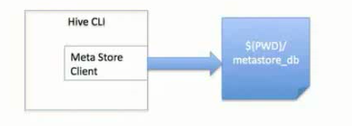
单用户模式:

多用户模式:(远程服务器模式)

HIVE的Metastore:
Metastore:hive元数据的集中存放地,metastore默认使用内嵌的derby数据库作为存储引擎。
Derby引擎的缺点,一次只能打开一个会话。
使用Mysql作为外置存储引擎,多用户同时访问。
4. 配置MySql的metastore
PS:metastore默认使用derby数据库作为存储引擎,但是一次只能打开一个会话,修改成Mysql作为外置存储引擎,进行多用户同时访问。
前提:已经安装MYSQL
未安装mysql,可参考文章:https://www.cnblogs.com/wendyw/p/11389741.html
- 1.上传mysql-connector-java-5.1.10.jar到$HIVE_HOME/lib
- 2.登录MYSQL,创建数据库hive
#mysql -uroot -pitcast
mysql>create database hive;
mysql>GRANT all ON hive.* TO root@'%' IDENTIFIED BY 'itcast';
mysql>flush privileges;
mysql>set global binlog_format='MIXED';
- 3.把mysql的数据库字符类型改为latin1
修改$HIVE_HOME/conf/hive-site.xml,其中hadoop表示自己当前虚拟机的主机名,用户名和密码都是mysql登录的用户名、密码,hive-site.xml配置文件如下:
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>itcast</value>
</property>