作者:58沈剑
问题抽象:
(1)用户会员系统;
(2)用户会有分数流水,每个月要做一次分数统计,对不同分数等级的会员做不同业务处理;
数据假设: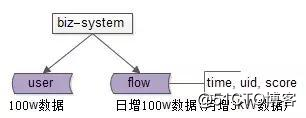
(1)假设用户在100w级别;
(2)假设用户日均1条流水,也就是说日增流水数据量在100W级别,月新增流水在3kW级别,3个月流水数据量在亿级别;
常见解决方案:
用一个定时任务,每个月的第一天计算一次。
//(1)查询出所有用户
uids[] = select uid from t_user;
//(2)遍历每个用户
foreach $uid in uids[]{
//(3)查询用户3个月内分数流水
scores[]= select score from t_flow
where uid=$uid and time=[3个月内];
//(4)遍历分数流水
foreach $score in scores[]{
//(5)计算总分数
sum+= $score;
}
//(6)根据分数做业务处理
switch(sum)
升级降级,发优惠券,发奖励;
}一个月执行一次的定时任务,会存在什么问题?
计算量很大,处理的数据量很大,耗时很久,按照水友的说法,需要1-2天。
画外音:外层循环100W级别用户;内层循环9kW级别流水;业务处理需要10几次数据库交互。
可不可以多线程并行处理?
可以,每个用户的流水处理不耦合。
改为多线程并行处理,例如按照用户拆分,会存在什么问题?
每个线程都要访问数据库做业务处理,数据库有可能扛不住。
这类问题的优化方向是:
(1)同一份数据,减少重复计算次数;
(2)分摊CPU计算时间,尽量分散处理,而不是集中处理;
(3)减少单次计算数据量;
如何减少同一份数据,重复计算次数?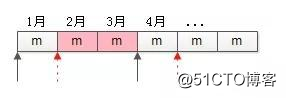
如上图,假设每一个方格是1个月的分数流水数据(约3kW)。
3月底计算时,要查询并计算1月,2月,3月三个月的9kW数据;
4月底计算时,要查询并计算2月,3月,4月三个月的9kW数据;
…
会发现,2月和3月的数据(粉色部分),被重复查询和计算了多次。
画外音:该业务,每个月的数据会被计算3次。
新增月积分流水汇总表,每次只计算当月增量:
flow_month_sum(month, uid, flow_sum)
(1)每到月底,只计算当月分数,数据量减少到1/3,耗时也减少到1/3;
(2)同时,把前2个月流水加和,就能得到最近3个月总分数(这个动作几乎不花时间);
画外音:该表的数量级和用户表数据量一致,100w级别。
这样一来,每条分数流水只会被计算一次。
如何分摊CPU计算时间,减少单次计算数据量呢?
业务需求是一个月重新计算一次分数,但一个月集中计算,数据量太大,耗时太久,可以将计算分摊到每天。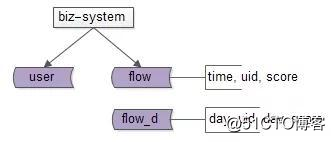
如上图,月积分流水汇总表,升级为,日积分流水汇总表。
把每月1次集中计算,分摊为30次分散计算,每次计算数据量减少到1/30,就只需要花几十分钟处理了。
甚至,每一个小时计算一次,每次计算数据量又能减少到1/24,每次就只需要花几分钟处理了。
虽然时间缩短了,但毕竟是定时任务,能不能实时计算分数流水呢?
每天只新增100w分数流水,完全可以实时累加计算“日积分流水汇总”。
使用DTS(或者canal)增加一个分数流水表的监听,当用户的分数变化时,实时进行日分数流水累加,将1小时一次的定时任务计算,均匀分摊到“每时每刻”,每天新增100w流水,数据库写压力每秒钟10多次,完全扛得住。
画外音:如果不能使用DTS/canal,可以使用MQ。
总结,对于这类一次性集中处理大量数据的定时任务,优化思路是:
(1)同一份数据,减少重复计算次数;
(2)分摊CPU计算时间,尽量分散处理(甚至可以实时),而不是集中处理;
(3)减少单次计算数据量;
希望大家有所启示,思路比结论重要。
最后
欢迎大家一起交流,喜欢文章记得点个赞哟,感谢支持!