一 .ORM连表高级操作
https://www.cnblogs.com/dangrui0725/p/9616192.html
1.ORM分组操作用于实现聚合group by查询
from django.db.models import Count, Min, Max, Sum
res=models.Emp.objects.filter(age='22').order_by('id') # asc print(res) # <QuerySet [<Emp: Emp object (3)>, <Emp: Emp object (4)>]> res=models.Emp.objects.filter(age='22').order_by('-id') # desc print(res) # <QuerySet [<Emp: Emp object (4)>, <Emp: Emp object (3)>]> res=models.Emp.objects.filter(id=1).values('name').annotate(c=Count('age')) # <QuerySet [{'name': '张三', 'c': 1}]> res= models.Emp.objects.filter(id=2).values('name').annotate(c=Count('age')) # <QuerySet [{'name': '李四', 'c': 1}]> print(res.query) #SELECT `app01_emp`.`name`, COUNT(`app01_emp`.`age`) AS `c` FROM `app01_emp` WHERE `app01_emp`.`id` = 2 GROUP BY `app01_emp`.`name` ORDER BY NULL res=models.Emp.objects.values("nid_id").annotate(cc=Count("id")).filter(age__gt=2) print(res) #<QuerySet [{'nid_id': 1, 'cc': 2}, {'nid_id': 2, 'cc': 1}, {'nid_id': 3, 'cc': 1}, {'nid_id': 4, 'cc': 1}]> <QuerySet [{'nid_id': 1, 'cc': 2}, {'nid_id': 2, 'cc': 1}, {'nid_id': 3, 'cc': 1}, {'nid_id': 4, 'cc': 1}]> print(res.query)#SELECT `app01_emp`.`nid_id`, COUNT(`app01_emp`.`id`) AS `cc` FROM `app01_emp` WHERE `app01_emp`.`age` > 2 GROUP BY `app01_emp`.`nid_id` ORDER BY NULL res=models.Emp.objects.filter(id__gt=2).values("nid_id").annotate(cc=Count("id")).filter(age__gt=2) print(res) <QuerySet [{'nid_id': 1, 'cc': 1}, {'nid_id': 3, 'cc': 1}, {'nid_id': 4, 'cc': 1}]> print(res.query)#SELECT `app01_emp`.`nid_id`, COUNT(`app01_emp`.`id`) AS `cc` FROM `app01_emp` WHERE (`app01_emp`.`id` > 2 AND `app01_emp`.`age` > 2) GROUP BY `app01_emp`.`nid_id` ORDER BY NULL
v = models.UserInfo.objects.values('u_id').annotate(uid=Count('u_id'))
# SELECT u_id, COUNT(ui) AS `uid` FROM UserInfo GROUP BY u_id
v = models.UserInfo.objects.values('u_id').annotate(uid=Count('u_id')).filter(uid__gt=1)
# SELECT u_id, COUNT(ui_id) AS `uid` FROM UserInfo GROUP BY u_id having count(u_id) > 1
v = models.UserInfo.objects.values('u_id').annotate(uid=Count('u_id',distinct=True)).filter(uid__gt=1)
# SELECT u_id, COUNT( DISTINCT ui_id) AS `uid` FROM UserInfo GROUP BY u_id having count(u_id) > 1
2. F查询(更新数据时获取原数据值)
在之前的所有的例子中,我们构造的过滤器都只是将字段值与某个常量做比较。如果我们要对两个字段的值做比较,那该怎么做呢?
Django 提供 F() 来做这样的比较。F() 的实例可以在查询中引用字段,来比较同一个 model 实例中两个不同字段的值
查询评论数大于收藏数的书籍 from django.db.models import F models.Book.objects.filter(commnet_num__gt=F('keep_num')) Django 支持 F() 对象之间以及 F() 对象和常数之间的加减乘除和取模的操作。 models.Book.objects.filter(commnet_num__lt=F('keep_num')*2) 修改操作也可以使用F函数,比如将每一本书的价格提高30元 models.Book.objects.all().update(price=F("price")+30)
models.Emp.objects.all().update(age=F("age")+22)
3. Q查询(用于构造复杂条件)
Q查询可以组合使用 “&”, “|” 操作符,当一个操作符是用于两个Q的对象,它产生一个新的Q对象,Q对象可以用 “~” 操作符放在前面表示否定,也可允许否定与不否定形式的组合。
Q对象可以与关键字参数查询一起使用,不过一定要把Q对象放在关键字参数查询的前面。
filter() 等方法中的关键字参数查询都是一起进行“AND” 的。 如果你需要执行更复杂的查询(例如OR语句),你可以使用Q对象
models.Book.objects.filter(Q(authors__name="小仙女")|Q(authors__name="小魔女")) 你可以组合& 和| 操作符以及使用括号进行分组来编写任意复杂的Q 对象。同时,Q 对象可以使用~ 操作符取反,这允许组合正常的查询和取反(NOT) 查询。 示例:查询作者名字是小仙女并且不是2018年出版的书的书名。 >>> models.Book.objects.filter(Q(author__name="小仙女") & ~Q(publish_date__year=2018)).values_list("title") <QuerySet [('番茄物语',)]> 查询函数可以混合使用Q 对象和关键字参数。所有提供给查询函数的参数(关键字参数或Q 对象)都将"AND”在一起。但是,如果出现Q 对象,它必须位于所有关键字参数的前面。 例如:查询出版年份是2017或2018,书名中带物语的所有书。 >>> models.Book.objects.filter(Q(publish_date__year=2018) | Q(publish_date__year=2017), title__icontains="物语") <QuerySet [<Book: 番茄物语>, <Book: 香蕉物语>, <Book: 橘子物语>]>
方式一: Q(nid__gt=10) Q(nid=8) | Q(nid__gt=10) Q(Q(nid=8) | Q(nid__gt=10)) & Q(caption='root') 方式二: con = Q() q1 = Q() q1.connector = 'OR' q1.children.append(('id', 1)) q1.children.append(('id', 10)) q1.children.append(('id', 9))
q2 = Q() q2.connector = 'OR' q2.children.append(('c1', 1)) q2.children.append(('c1', 10)) q2.children.append(('c1', 9)) con.add(q1, 'AND') con.add(q2, 'AND')
models.Tb1.objects.filter(con)
from django.db.models import Q print(Book.objects.filter(Q(id=3))[0]) # 因为获取的结果是一个QuerySet,所以使用下标的方式获取结果 print(Book.objects.filter(Q(id=3)|Q(title="Go"))[0]) # 查询id=3或者标题是“Go”的书 print(Book.objects.filter(Q(price__gte=70)&Q(title__startswith="J"))) # 查询价格大于等于70并且标题是“J”开头的书 print(Book.objects.filter(Q(title__startswith="J") & ~Q(id=3))) # 查询标题是“J”开头并且id不是3的书 print(Book.objects.filter(Q(price=70)|Q(title="Python"), publication_date="2017-09-26")) # Q对象可以与关键字参数查询一起使用,必须把普通关键字查询放到Q对象查询的后面
from django.db.models import Q con = Q() q1 = Q() q1.connector = "AND" q1.children.append(("email", "[email protected]")) q1.children.append(("password", "abc123")) q2 = Q() q2.connector = "AND" q2.children.append(("username", "abc")) q2.children.append(("password", "xyz123")) con.add(q1, "OR") con.add(q2, "OR") obj = models.UserInfo.objects.filter(con).first() # 查询[email protected]和password=abc123 或者 username=abc和password=xyz123的用户信息
aa={ "id":1, "name":"李四" } res=models.Emp.objects.filter(**aa) print(res)
4. Django原生sql
from django.db import connection, connections cursor = connection.cursor() # cursor = connections['default'].cursor() 默认是default数据库 也可是其他数据库 cursor.execute("""SELECT * from auth_user where id = %s""", [1]) row = cursor.fetchone()
# row = cursor.fetchall()
DATABASES = { 'default': { 默认数据库 'ENGINE': 'django.db.backends.mysql', 'NAME': "db7", #create DATABASE Dear1; 'USER': "root", 'PASSWORD':'root', 'HOST':'localhost', 'PORT':'3306', }, 'db1': { 'ENGINE': 'django.db.backends.sqlite3', 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'), } }
5 .extra 构造额外的查询条件或者映射
extra(self, select=None, where=None, params=None, tables=None, order_by=None, select_params=None)
# 构造额外的查询条件或者映射,如:子查询 Entry.objects.extra(select={'new_id': "select col from sometable where othercol > %s"}, select_params=(1,)) Entry.objects.extra(where=['headline=%s'], params=['Lennon']) Entry.objects.extra(where=["foo='a' OR bar = 'a'", "baz = 'a'"]) Entry.objects.extra(select={'new_id': "select id from tb where id > %s"}, select_params=(1,), order_by=['-nid'])
res= models.Emp.objects.extra( select={'new_nid':'select count(1) from app01_emp where id>%s'}, select_params=[1,], where=['age>%s'], params=[22,], order_by=['-age'], tables=[' app01_emp'] ) print(res)
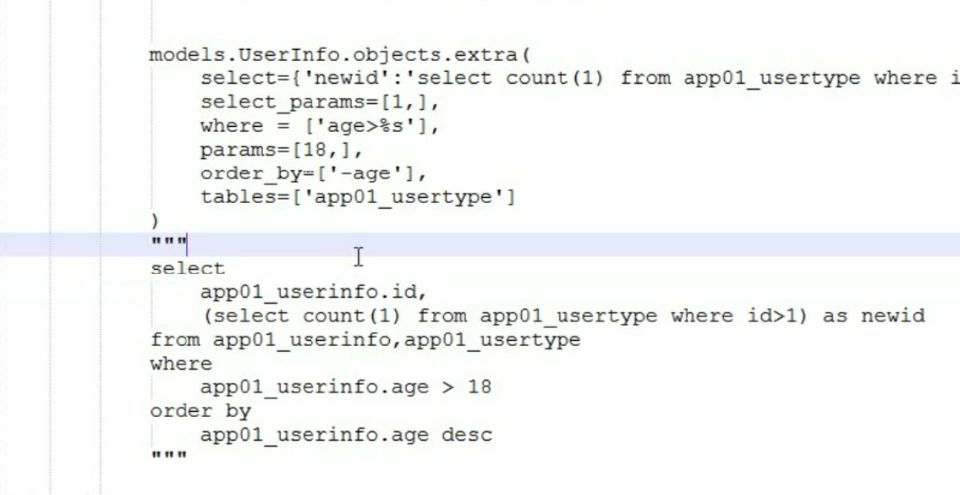
res= models.Emp.objects.extra( where=["id=1","name='李四'"] ) res = models.Emp.objects.extra( where=["id=1 or id=%s", "name=%s"], params=[1,"李四"] )
res= models.Emp.objects.filter(id__gt=2).extra( where=[" app01_emp.id<3"] ) print(res.query) #SELECT `app01_emp`.`id`, `app01_emp`.`name`, `app01_emp`.`hobby`, `app01_emp`.`age`, `app01_emp`.`nid_id` FROM `app01_emp` WHERE (`app01_emp`.`id` > 2 AND ( app01_emp.id<3))
def find_show(request): res= models.Emp.objects.filter(id__gt=2).extra( where=[" app01_emp.id<%s"], params=[4,] ) print(res.query)
res= models.Emp.objects.filter(id__gt=2).extra( where=[" app01_emp.id<%s"], params=[4,], tables=["app01_emp"] ) print(res.query) #SELECT `app01_emp`.`id`, `app01_emp`.`name`, `app01_emp`.`hobby`, `app01_emp`.`age`, `app01_emp`.`nid_id` FROM `app01_emp` WHERE (`app01_emp`.`id` > 2 AND ( app01_emp.id<4))
res= models.Emp.objects.filter(id__gt=2).extra( where=[" app01_emp.id<%s"], params=[4,], tables=["app01_emp"], order_by=["app01_emp.id"] ) print(res.query) #SELECT `app01_emp`.`id`, `app01_emp`.`name`, `app01_emp`.`hobby`, `app01_emp`.`age`, `app01_emp`.`nid_id` FROM `app01_emp` WHERE (`app01_emp`.`id` > 2 AND ( app01_emp.id<4)) ORDER BY (`app01_emp`.id) ASC
res= models.Emp.objects.filter(id__gt=2).extra( where=[" app01_emp.id<%s"], params=[4,], tables=["app01_emp"], order_by=["app01_emp.id"], select={"nid":1,"sw":"select count(1) from app01_emp"} ) print(res.query) #SELECT (1) AS `nid`, (select count(1) from app01_emp) AS `sw`, `app01_emp`.`id`, `app01_emp`.`name`, `app01_emp`.`hobby`, `app01_emp`.`age`, `app01_emp`.`nid_id` FROM `app01_emp` WHERE (`app01_emp`.`id` > 2 AND ( app01_emp.id<4)) ORDER BY (`app01_emp`.id) ASC
6. 其他操作
https://www.cnblogs.com/wupeiqi/articles/6216618.html
用于distinct去重 models.UserInfo.objects.values('nid').distinct() 用于排序 models.UserInfo.objects.all().order_by('-id','age') 倒序 models.UserInfo.objects.all().order_by('-nid').reverse() 仅取某个表中的数据 models.UserInfo.objects.only('username','id') 映射中排除某列数据 models.UserInfo.objects.defer('username','id') models.UserInfo.objects.filter(...).defer('username','id') 性能相关:表之间进行join连表操作,一次性获取关联的数据。 model.tb.objects.all().select_related() model.tb.objects.all().select_related('外键字段') model.tb.objects.all().select_related('外键字段__外键字段') 执行原生SQL models.UserInfo.objects.raw('select * from userinfo') 如果SQL是其他表时,必须将名字设置为当前UserInfo对象的主键列名 models.UserInfo.objects.raw('select id as nid from 其他表') 为原生SQL设置参数 models.UserInfo.objects.raw('select id as nid from userinfo where nid>%s', params=[12,]) 将获取的到列名转换为指定列名 name_map = {'first': 'first_name', 'last': 'last_name', 'bd': 'birth_date', 'pk': 'id'} Person.objects.raw('SELECT * FROM some_other_table', translations=name_map) 指定数据库 models.UserInfo.objects.raw('select * from userinfo', using="default"
models.UserInfo.objects.all().using("db2")
如果存在,则获取,否则,创建 defaults 指定创建时,其他字段的值 obj, created = models.UserInfo.objects.get_or_create(username='root1', defaults={'email': '1111111','u_id': 2, 't_id': 2}) 如果存在,则更新,否则,创建 defaults 指定创建时或更新时的其他字段 obj, created = models.UserInfo.objects.update_or_create(username='root1', defaults={'email': '1111111','u_id': 2, 't_id': 1}) 批量插入 batch_size表示一次插入的个数 objs = [ models.DDD(name='r11'), models.DDD(name='r22') ] models.DDD.objects.bulk_create(objs, 10) 数字自增、字符串更新 # 数字自增 from django.db.models import F models.UserInfo.objects.update(num=F('num') + 1) # 字符串更新 from django.db.models.functions import Concat from django.db.models import Value models.UserInfo.objects.update(name=Concat('name', 'pwd')) models.UserInfo.objects.update(name=Concat('name', Value('666'))) ORM函数相关 # ########### 基础函数 ########### # 1. Concat,用于做类型转换 # v = models.UserInfo.objects.annotate(c=Cast('pwd', FloatField())) # 2. Coalesce,从前向后,查询第一个不为空的值 # v = models.UserInfo.objects.annotate(c=Coalesce('name', 'pwd')) # v = models.UserInfo.objects.annotate(c=Coalesce(Value('666'),'name', 'pwd')) # 3. Concat,拼接 # models.UserInfo.objects.update(name=Concat('name', 'pwd')) # models.UserInfo.objects.update(name=Concat('name', Value('666'))) # models.UserInfo.objects.update(name=Concat('name', Value('666'),Value('999'))) # 4.ConcatPair,拼接(仅两个参数) # v = models.UserInfo.objects.annotate(c=ConcatPair('name', 'pwd')) # v = models.UserInfo.objects.annotate(c=ConcatPair('name', Value('666'))) # 5.Greatest,获取比较大的值;least 获取比较小的值; # v = models.UserInfo.objects.annotate(c=Greatest('id', 'pwd',output_field=FloatField())) # 6.Length,获取长度 # v = models.UserInfo.objects.annotate(c=Length('name')) # 7. Lower,Upper,变大小写 # v = models.UserInfo.objects.annotate(c=Lower('name')) # v = models.UserInfo.objects.annotate(c=Upper('name')) # 8. Now,获取当前时间 # v = models.UserInfo.objects.annotate(c=Now()) # 9. substr,子序列 # v = models.UserInfo.objects.annotate(c=Substr('name',1,2)) # ########### 时间类函数 ########### # 1. 时间截取,不保留其他:Extract, ExtractDay, ExtractHour, ExtractMinute, ExtractMonth,ExtractSecond, ExtractWeekDay, ExtractYear, # v = models.UserInfo.objects.annotate(c=functions.ExtractYear('ctime')) # v = models.UserInfo.objects.annotate(c=functions.ExtractMonth('ctime')) # v = models.UserInfo.objects.annotate(c=functions.ExtractDay('ctime')) # # v = models.UserInfo.objects.annotate(c=functions.Extract('ctime', 'year')) # v = models.UserInfo.objects.annotate(c=functions.Extract('ctime', 'month')) # v = models.UserInfo.objects.annotate(c=functions.Extract('ctime', 'year_month'))
# Book.objects.filter(id=2) #取集合数据 Book_list=Book.objects.all() #查询所有数据 # Book_list=Book.objects.all()[:3] #只截取前三条数据 # Book_list=Book.objects.all()[::-1] #倒序去数据 # Book_list=Book.objects.all()[::2] #按照步长取数据 # Book_list=Book.objects.first() #取第一个数据 # Book_list=Book.objects.last() #取第最后一个数据 # Book_list=Book.objects.get(id=2) #条件筛选取数据 只能一条一条的数据取 不然会报错 # Book_list=Book.objects.filter(author="李四").values("name") #filter条件筛选取数据 返回来的数据是是字典类型 # Book_list=Book.objects.filter(author="李四").values_list("name") #filter条件筛选取数据 返回来的数据是列表类型 # Book_list=Book.objects.exclude(author="李四").values("name") # 它包含了与给的筛选条件不匹配的对象 与filter()相反 # Book_list=Book.objects.order_by() # 对查询结果排序 # Book_list=Book.objects.reverse() # 对查询结果反相排序 # Book_list=Book.objects.all().values("author").distinct() # distinct() 从结果集中删除重复记录 要加条件 # Book_list=Book.objects.all().values("author").distinct().count() # 意思去除重复后的 数据个数 # Book_list=Book.objects.filter(price__gt=50).values("name","price") # 读取大于50数据 # Book_list=Book.objects.filter(id__gt=3).values("name","price") # id读取大于3数据 # Book_list=Book.objects.filter(name__icontains="P").values("name","price") # 不区分大小写 # print( Book_list) return render(request,"html_app/04mysql.html",{"book":Book_list}) # return HttpResponse("删除成功了!!!!!!!!!!!!!!!!!!!")