Part one 格式化输出
%s:字符串
%d:digit 数字
%%:只是单纯的显示%
ps:格式化输出过程中要想输出%,再加一个% eg:3%% 前一个%相当于转义
3%%格式化输出 %%S格式化输出%S
模式一:
name=input('请输入姓名:') age=input('请输入年龄:') height=input('请输入身高:') msg='我叫%s,今年%s,身高%s' %(name,age,height) print(msg)

模式二:
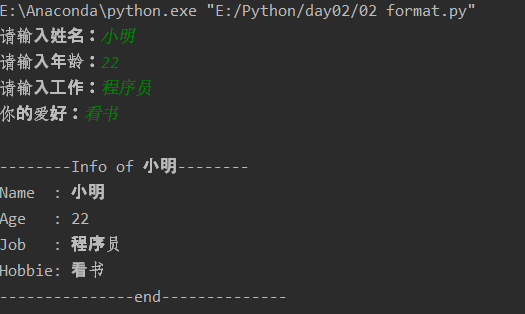
name=input('请输入姓名:') age=(int)(input('请输入年龄:')) job=input('请输入工作:') hobbie=input('你的爱好:') msg=''' --------Info of %s-------- Name : %s Age : %d Job : %s Hobbie: %s ---------------end--------------''' %(name,name,age,job,hobbie) print(msg)
模式三:
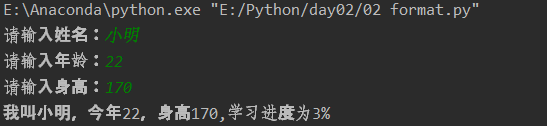
name=input('请输入姓名:') age=input('请输入年龄:') height=input('请输入身高:') msg='我叫%s,今年%s,身高%s,学习进度为3%%' %(name,age,height) print(msg)

Part two 流程控制---while语句
生活中经常会遇到需要循环的情境,比如:吃饭睡觉、听音乐等等。在程序代码的世界里不免也会存在很多需要循环进行的操作,在python中,我们应用while语句来对循环进行控制。其基本结构如下所示:
While 条件:
循环体
Ps:如果条件为真,name循环体则执行,否则不执行
那么当程序运行进入循环后,如何终止循环呢?
方法有四种:
1、 改变条件
2、 调用关键字break
3、 调用系统命令quit()、exit()。Ps:不建议使用
4、 调用关键字continue(终止本次循环)
有过其他编程语言经验的程序员都知道:else在大多数情况下都只于if搭配,但是在python中也存在while与else的搭配。while 后面的else 作用是指,当while 循环正常执行完,中间没有被break 中止的话,就会执行else后面的语句。如果执行过程中被break啦,就不会执行else的语句啦
count=0 while count<=5: count+=1 if count==3:break print("Loop",count) else: print("循环正常执行完了") print("------out of while loop ------")

Part three 基本运算符
计算机可以进行的运算有很多种,可不只加减乘除这么简单,运算按种类可分为算数运算、比较运算、逻辑运算、赋值运算、成员运算、身份运算、位运算。今天暂且接触其中的几种运算。
1、 算术运算
以下假设变量:a=10,b=20

2、 比较运算
以下假设变量:a=10,b=20

3、 赋值运算
以下假设变量:a=10,b=20

4、 逻辑运算

针对逻辑运算的进一步研究:
- ,在没有()的情况下not 优先级高于 and,and优先级高于or,即优先级关系为( )>not>and>or,同一优先级从左往右计算。
- x or y , x为真,值就是x,x为假,值是y;x and y, x为真,值是y,x为假,值是x。


1 #x or y x为非0则返回x 2 3 print(1 or 2) #1 4 print(0 or 2) #2 5 print(3 or 2) #3 6 print(0 or 100) #100 7 8 #ps int-->bool 非0转换为bool为True,0转换为bool为False 9 print(bool(0)) #False 10 print(bool(2)) #True 11 print(bool(-2)) #True 12 13 #bool-->int 14 print(int(True)) #1 15 print(int(False)) #0 16 17 #x and y x为True,则返回y 18 print(1 and 2) #2 19 print(0 and 2) #0
5、 成员运算
Python还支持成员运算符,测试实例中包含了一系列的成员,包括字符串,列表或元组。

判断子元素是否在原字符串(字典,列表,集合)中
6、 Python运算符优先级
以下表格列出了从最高到最低优先级的所有运算符:
| 运算符 | 描述 |
|---|---|
| ** | 指数 (最高优先级) |
| ~ + - | 按位翻转, 一元加号和减号 (最后两个的方法名为 +@ 和 -@) |
| * / % // | 乘,除,取模和取整除 |
| + - | 加法减法 |
| >> << | 右移,左移运算符 |
| & | 位 'AND' |
| ^ | | 位运算符 |
| <= < > >= | 比较运算符 |
| <> == != | 等于运算符 |
| = %= /= //= -= += *= **= | 赋值运算符 |
| is is not | 身份运算符 |
| in not in | 成员运算符 |
| not and or | 逻辑运算符 |
Part four 初识编码
计算机与人类的大脑不同,无法直接识别输入的各种类型的数据。在电脑中存在着成千上万的二极管,亮代表1不亮代表0,即实际上电脑存储和发送的数据均是由0和1组成的字符串,但是人们将其不同的0与1组合赋予不同的含义便可识别和传输人们想要的数据。
最初,计算机所使用的密码本是ASCII码American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统ASCII码中只包含英文字母,数字以及特殊字符与二进制的对应关系,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256,所以,ASCII码最多只能表示 256 个符号。
随着计算机的发展. 以及普及率的提高. 流⾏到欧洲和亚洲. 这时ASCII码就不合适了。比如: 中⽂汉字有几万个. 而ASCII 多也就256个位置. 所以ASCII不行了. 怎么办呢? 这时, 不同的国家就提出了不同的编码用来适用于各自的语言环境(每个国家都有每个国家的GBK,每个国家的GBK都只包含ASCII码中内容以及本国自己的文字). 比如, 中国的GBK, GB2312, BIG5, ISO-8859-1等等. 这时各个国家都可以使用计算机了.
经实际测试和查阅文档,GBK是采用单双字节变长编码,英文使用单字节编码,完全兼容ASCII字符编码,中文部分采用双字节编码。
对于ASCII码中的内容,GBK完全沿用的ASCII码,所以一个英文字母(数字,特殊字母)用一个字节表示,而对于中文来说,一个中文用两个字节表示
但是,随着全球化的普及,由于网络的连通,以及互联网产品的共用(不同国家的游戏,软件,建立联系等),各个国家都需要产生各种交集,此时急需一个密码本:要包含全世界所有的文字与二进制0101010的对应关系,所以创建了万国码:
Unicode: 包含全世界所有的文字与二进制0101001的对应关系。
起初:Unicode规定一个字符用两个字节表示:
英文: a b c 六个字节 一个英文2个字节
中文 中国 四个字节 一个中文用2个字节
但是这种也不行,这种最多有65535种可能,可是中国文字有9万多,所以改成一个字符用四个字节表示:.
a 01000001 01000010 01000011 00000001
b 01000001 01000010 01100011 00000001
中 01001001 01000010 01100011 00000001
这样虽然解决了问题,但是又引出一个新的问题就是原本a可以用1个字节表示,却必须用4个字节,这样非常浪费资源,所以对Uniocde进行升级。
UTF-8:包含全世界所有的文字与二进制0101001的对应关系(最少用8位一个字节表示一个字符)。
UTF-8 :最少用8位数,去表示一个字符.
英文: 8位,1个字节表示.
欧洲文字: 16位,两个字节表示一个字符.
中文,亚洲文字: 24位,三个字节表示.
Part five 基础数据类型
前一天已经接触过一些数据类型的知识了,现在我们来仔细学习一下基础数据类型。
Python中常用的数据类型由7种,分别是:整数(int) ,字符串(str),布尔值(bool),列表(list),元组(tuple),字典(dict),集合(set).
1、 整数(int)1,2,3 用于计算,这里不作详细介绍
python给咱们提供了一种方法:bit_length()就是帮助你快速的计算整数在内存中占用的二进制码的长度.
i=5
print(i.bit_length())

2、 字符串(str)
2.3.1、字符串的索引与切片。
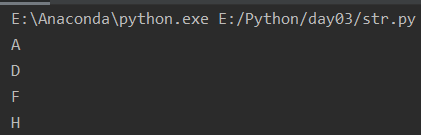
组成字符串的字符从左至右,依次排列,他们都是有顺序的,就好比是部队的队列,从左至右依次报号(从零开始) :0,1,2,3.... 索引即下标,就是字符串组成的元素从第一个开始,初始索引为0以此类推。
a = 'ABCDEFGHIJK' print(a[0]) print(a[3]) print(a[5]) print(a[7])
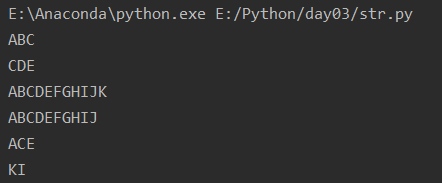
切片就是通过索引(索引:索引:步长)截取字符串的一段,形成新的字符串(原则就是顾头不顾腚)
a = 'ABCDEFGHIJK' print(a[0:3]) # print(a[:3]) 从开头开始取0可以默认不写 print(a[2:5]) print(a[:]) #默认到最后 print(a[:-1]) # -1 是列表中最后一个元素的索引,但是要满足顾头不顾腚的原则,所以取不到K元素 print(a[:5:2]) #加步长 print(a[-1:-5:-2]) #反向加步长
2.3.2、字符串常用方法。
字符串除了可以用切片(步长)之外,还有一些其他的操作方法。
#数字符串中的元素出现的个数。 # ret3 = a1.count("a",0,4) # 可切片 # print(ret3) a4 = "dkfjdkfasf54" #startswith 判断是否以...开头 #endswith 判断是否以...结尾 # ret4 = a4.endswith('jdk',3,6) # 顾头不顾腚 # print(ret4) # 返回的是布尔值 # ret5 = a4.startswith("kfj",1,4) # print(ret5) #split 以什么分割,最终形成一个列表此列表不含有这个分割的元素。 # ret9 = 'title,Tilte,atre,'.split('t') # print(ret9) # ret91 = 'title,Tilte,atre,'.rsplit('t',1) # print(ret91) #format的三种玩法 格式化输出 res='{} {} {}'.format('egon',18,'male') res='{1} {0} {1}'.format('egon',18,'male') res='{name} {age} {sex}'.format(sex='male',name='egon',age=18) #strip name='*barry**' print(name.strip('*')) print(name.lstrip('*')) print(name.rstrip('*')) #replace name='alex say :i have one tesla,my name is alex' print(name.replace('alex','SB',1)) #####is系列 name='taibai123' print(name.isalnum()) #字符串由字母或数字组成 print(name.isalpha()) #字符串只由字母组成 print(name.isdecimal()) #字符串只由十进制组成 #############下面这些方法在数据类型补充时会讲到,现在不讲#################### #寻找字符串中的元素是否存在 # ret6 = a4.find("fjdk",1,6) # print(ret6) # 返回的找到的元素的索引,如果找不到返回-1 # ret61 = a4.index("fjdk",4,6) # print(ret61) # 返回的找到的元素的索引,找不到报错。 #captalize,swapcase,title print(name.capitalize()) #首字母大写 print(name.swapcase()) #大小写翻转 msg='taibai say hi' print(msg.title()) #每个单词的首字母大写 # 内同居中,总长度,空白处填充 ret2 = a1.center(20,"*") print(ret2)
3、 布尔值(bool)
布尔值就两种:True,False。就是反应条件的正确与否。
真 1 True。
假 0 False。
这里补充一下int str bool 三者数据类型之间的转换。
#bool: True False #int-->str i=1 s=str(i) #str-->int s='123' i=int(s) #int-->bool 只要是0-->False 非0就是True i=3 b=bool(i) #bool-->int #True 1 #False 0 # str-->bool # s='' --->False # 非空字符串都是True # s="0"--->True
4、 列表(list)
python给咱们也提供了一类数据类型,他能承载多种数据类型,这类数据类型被称作容器类数据类型可以存储大量的数据。列表就属于容器类的数据类型。
列表是python的基础数据类型之一 ,其他编程语言也有类似的数据类型.比如JS中的数 组, java中的数组等等. 它是以[ ]括起来, 每个元素用' , '隔开而且可以存放各种数据类型
定义与输出:
#列表 li=['alex',[1,2,3],'wusir','egon','女神'] print(li[0]) #alex print(li[1]) #[1, 2, 3] print(li[0:3]) #['alex', [1, 2, 3], 'wusir']
增
#列表增append li=['alex',[1,2,3],'wusir','egon','女神'] li.append('小碗') print(li) #['alex', [1, 2, 3], 'wusir', 'egon', '女神', '小碗'] li.append(1) print(li) #['alex', [1, 2, 3], 'wusir', 'egon', '女神', '小碗', 1]
li=['alex',[1,2,3],'wusir','egon','女神'] li.insert(4,'春哥') print(li) #['alex', [1, 2, 3], 'wusir', 'egon', '春哥', '女神'] #迭代(可迭代的对象才行,123就不行) li.extend('二哥') li.extend([1,2,3]) print(li) #['alex', [1, 2, 3], 'wusir', 'egon', '春哥', '女神', '二', '哥', 1, 2, 3]
删
#删 li=['alex',[1,2,3],'wusir','egon','女神'] name=li.pop(1) print(name)#可返回删除的对象 [1, 2, 3] name1=li.pop()#默认删最后一个 print(name1) #女神 li.remove('egon')#按元素去删除 print(li) #['alex', 'wusir'] li.clear()#清空 也可 del li #切片删 del li[2:] print(li) #[]
改
#改 li=['alex',[1,2,3],'wusir','egon','女神'] li[0]='男神' #切片改 li[0:2]='小白' li[0:3]=[1,2,3,'春哥','xiaobai'] print(li) #[1, 2, 3, '春哥', 'xiaobai', 'egon', '女神']
查
#查 li=['alex',[1,2,3],'wusir','egon','女神'] for i in li: print(i) print(li[0:2])
公共方法
#公共方法: li=['alex',[1,2,3],'wusir','egon','女神'] l=len(li) print(l) #5 num=li.count('xiaobai') print(num) #0 print(li.index('wusir')) #2 #正向排序 li=[1,4,7,2,4,9,22] li.sort() print(li) #[1, 2, 4, 4, 7, 9, 22] #倒向排序 li.sort(reverse=True) print(li) #[22, 9, 7, 4, 4, 2, 1] #反转 li.reverse() print(li) #[1, 2, 4, 4, 7, 9, 22]
嵌套
#列表的嵌套 li=['taibai','wuli','袁和平',['Alex',89],23] print(li[1][1]) #u name=li[0].capitalize() print(name) #Taibai li[0]=name print(li) #['Taibai', 'wuli', '袁和平', ['Alex', 89], 23]
5、 元祖(tuple)
Why:对于容器型数据类型list,无论谁都可以对其增删改查,那么有一些重要的数据放在list中是不安全的,所以需要一种容器类的数据类型存放重要的数据,创建之初只能查看而不能增删改,这种数据类型就是元组。
what:这个容器型数据类型就是元组。
元组:俗称不可变的列表,又被成为只读列表,元祖也是python的基本数据类型之一,用小括号括起来,里面可以放任何数据类型的数据,查询可以,循环也可以,切片也可以.但就是不能改.只读列表,可循环查询,可切片
儿子不能改,孙子可能可以改
tu=(1,2,3,'alex',[2,3,4,'taibai'],'egon') print(tu[3]) print(tu[0:4]) for i in tu: print(i) tu[4][3]=tu[4][3].upper() print(tu)
用符号连接元素
s='Alex' s1='_'.join(s) print(s1) #A_l_e_x # #列表转换为字符串 join 列表--->字符串 # #字符串--->列表 split() li=['taibai','xiaobai','女神'] li1='*'.join(li) print(li1) #taibai*xiaobai*女神
6、 字典(dict)
数据类型划分:
可变数据类型:列表list、字典dict、集合set 不可哈希
不可变数据类型:元祖、bool、int、str 可哈希
dict的key必须是不可变数据类型,可哈希,value可谓任意数据类型
dict优点:二分法查找、存储大量的关系型数据
dict特点:无序的
字典的创建及输出:
dict ={ 'name':['小明','小红','小白'], 'cqu':[{'num':71,'avg_age':18}, {'num':71,'avg_age':18}, {'num':71,'avg_age':18},], True:1, (1,2,3):'gh', 2:'二哥', } print(dict)

增
dic={'age':18,'name':'wan','sex':'man'}
#增:
dic['height']=185 #没有键值对、添加
dic['age']=16 #如果有键则覆盖
print(dic) #{'age': 16, 'name': 'wan', 'sex': 'man', 'height': 185}
dic.setdefault('weight')#默认赋值为null
dic.setdefault('name','xiaoer')#有该键值对不做任何改变
print(dic) #{'age': 16, 'name': 'wan', 'sex': 'man', 'height': 185, 'weight': None}
删
#删 dic={'age':18,'name':'wan','sex':'man'} print(dic.pop('age'))#有返回值,按键去删除 18 print(dic.pop('二哥','没有此键'))#避免出错,可设置返回值 没有此键 print(dic) #{'name': 'wan', 'sex': 'man'} dic.popitem()#随机删除,有返回值:删除的键值 print(dic) #{'name': 'wan'} # # dic.clear()#清空字典 # del dic['name']#删除 # del dic
改
#改 dic={'age':18,'name':'wan','sex':'man'} dic['age']=16 dic={'age':18,'name':'wan','sex':'man'} dic1={'name':'Alex',"weight":75} dic1.update(dic)#覆盖添加 print(dic) #{'age': 18, 'name': 'wan', 'sex': 'man'} print(dic1) #{'name': 'wan', 'weight': 75, 'age': 18, 'sex': 'man'}
查
#查 dic={'age':18,'name':'wan','sex':'man'} print(dic.keys(),type(dic.keys()))#键 print(dic.values())#值 print(dic.items())#键值 for i in dic: print(i) #默认打出键 for i in dic.keys(): print(i) for i in dic.values(): print(i) for i in dic.items(): print(i) for k,v in dic.items(): print(k,v) print(dic['name'])

嵌套
dic={ 'name':['Alex','wuli','xiaoming'], 'cqu':{ 'qi':'2019', 'money':8000, 'address':'CQ', }, 'age':21 } dic['age'] = 56 # 改 dic['name'].append('haohao') print(dic) #{'name': ['Alex', 'wuli', 'xiaoming', 'haohao'], 'cqu': {'qi': '2019', 'money': 8000, 'address': 'CQ'}, 'age': 56} dic['name'][1]=dic['name'][1].upper() print(dic) #{'name': ['Alex', 'WULI', 'xiaoming', 'haohao'], 'cqu': {'qi': '2019', 'money': 8000, 'address': 'CQ'}, 'age': 56} dic['cqu']['female']=6 print(dic) #{'name': ['Alex', 'WULI', 'xiaoming', 'haohao'], 'cqu': {'qi': '2019', 'money': 8000, 'address': 'CQ', 'female': 6}, 'age': 56} #
7、 集合(set)
可变的数据类型,他里面的元素是不可变的数据类型,无序、不重复 {}
集合的创建、增、改、删、查(for遍历)
set1=set({1,2,3})
set2={1,2,3,[2,3],{'name','alex'}}#错的
set1={'xiaoming','xiaohong','xiaobai','xiaonan'} # #add set1.add('nvsheng') print(set1)#{'xiaobai', 'nvsheng', 'xiaoming', 'xiaonan', 'xiaohong'} #update set1.update('abc')#迭代加 print(set1)#{'xiaobai', 'nvsheng', 'b', 'c', 'xiaoming', 'a', 'xiaonan', 'xiaohong'} #delete set1.pop()#随机删除 print(set1.pop())#有返回值 c print(set1)#{'xiaonan', 'xiaohong', 'xiaoming', 'xiaobai', 'a', 'nvsheng'} set1.remove('xiaobai')#按元素删 print(set1)#{'xiaonan', 'xiaohong', 'xiaoming', 'a', 'nvsheng'} # set1.clear()#清空
集合的其他运算(交、并....)
#求交集 set1={1,2,3,4,5} set2={4,5,6,7,8} set3=set1&set2 print(set3) #{4, 5} print(set1.intersection(set2)) #{4, 5} #求并集 set1={1,2,3,4,5} set2={4,5,6,7,8} print(set1|set2) #{1, 2, 3, 4, 5, 6, 7, 8} print(set2.union(set1)) #{1, 2, 3, 4, 5, 6, 7, 8} #求反交集 set1={1,2,3,4,5} set2={4,5,6,7,8} print(set1^set2) #{1, 2, 3, 6, 7, 8} print(set1.symmetric_difference(set2)) #{1, 2, 3, 6, 7, 8} #求差集 set1={1,2,3,4,5} set2={4,5,6,7,8} print(set1-set2) #{1, 2, 3} print(set1.difference(set2)) #{1, 2, 3} #子集与超集 set1={1,2,3} set2={1,2,3,4,5} print(set1<set2) #True print(set1.issubset(set2)) #True print(set2>set1) #True print(set2.issuperset(set1)) #True #去重 li=[1,2,33,7,4,8,2] set1=set(li) print(set1) #{1, 2, 33, 4, 7, 8} li=list(set1) print(li) #{1, 2, 33, 4, 7, 8} s=frozenset('barry')#set本身是可变的数据类型,可用该方法将其变为不可变的数据类型 print(s,type(s)) #frozenset({'r', 'b', 'a', 'y'}) <class 'frozenset'>
Part six 其他(for、enumerate、range)
for循环:用户按照顺序循环可迭代对象的内容。

msg = '柳柳爱火锅'
for item in msg:
print(item)
li = ['alex','星仔','女神','egon','小伟']
for i in li:
print(i)
dic = {'name':'星仔','age':18,'sex':'man'}
for k,v in dic.items():
print(k,v)
enumerate:枚举,对于一个可迭代的(iterable)/可遍历的对象(如列表、字符串),enumerate将其组成一个索引序列,利用它可以同时获得索引和值。
li = ['alex','星仔','女神','egon','小伟']
for i in enumerate(li):
print(i)
for index,name in enumerate(li,1):
print(index,name)
for index, name in enumerate(li, 100): # 起始位置默认是0,可更改
print(index, name)
range:指定范围,生成指定数字。
for i in range(1,10):
print(i)
for i in range(1,10,2): # 步长
print(i)
for i in range(10,1,-2): # 反向步长
print(i)