2.1什么是多线程并发编程
并发:是指在同一时间段内,多个任务同时在执行,并且执行没有结束(同一时间段又包括多个单位时间,也就是说一个cpu执行多个任务)
并行:是指在单位时间内多个任务在同时执行(也就是多个cpu同时执行任务)
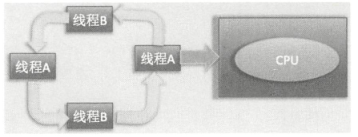

而在多线程编程实践中,线程的个数一般是多于cpu的个数的
2.2为什么要多线程并发编程
多个cpu同时执行多个任务,减少了线程上下文切换的开销
2.3线程安全问题
共享资源:就是说该资源可以被多个线程持有,或者说能够被多个线程访问。
对共享资源的修改会造成线程安全问题。
2.4共享变量的内存可见性问题
java内存模型(JMM)规定,所有的变量都存储在主内存中,当线程使用变量时,会将主内存中的变量复制一份到自己的工作内存,之后线程操作的变量都是自己工作内存(L1缓存或者L2缓存或者寄存器)中的变量。
这样对于内存不可见(没有使用volatile修改的变量)的变量来说,在不同线程中就可能存在不同的值。就那下图一个双核cpu系统来说,当操作一个共享变量X时,线程A就会获取当前内存中的变量X,由于线程A是第一次操作,当前工作内存中没有该变量,此时,线程A就会将主内存中的变量X复制一份到自己的工作内存(L1/L2缓存),线程A给变量X重新赋值(假设主内存中默认值为1,线程A修改为2),修改后,线程A会将修改后的值重新刷会主内存,此时线程A是正常工作的。然后线程B也要操作变量X,同样的也会将主内存中的变量X复制一份到自己的工作内存(此时变量X的值为2),此时获取的变量X(值为2)就是线程A操作后的值,那么线程B同样修改该变量,改为3,修改后线程B也会将变量重新刷回到主内存,此时,主内存中的变量X的值为3,线程A缓存中的值为2,线程B缓存中的值为3,那么线程A再要操作变量X的时候,就会直接操作缓存中的数据2,此时该值就不是正确的值了,出现内存可见性的问题。
解决内存可见性,就是讲共享变量X使用volatile或synchronized关键字。

2.5synchronized关键字
synchronized也能够解决共享变量的内存可见性问题,通常是用来解决原子性问题。
synchronized内存语义:就是在进入synchrinize代码块时,把块内使用到的变量从线程的工作内存中清除,直接使用主内存中的变量数据,同样在退出synchronize块时,将对共享变量的操作刷新到主内存。(也是枷锁和解锁的语义,加锁是清空线程工作缓存中共享变量的值,在使用的时候直接加载主内存中的数据,释放锁的时候,将线程内共享变量的数据刷回到主内存中)
2.6volatile关键字
volatile可以保证在对共享变量操作时对其他线程是可见的。volatile能够保证可见性,但是不能保证原子性(synchronized能够保证可见性和原子性)
2.7原子操作
原子操作:指的就是一系列操作要么都执行成功,要么都失败。
例如程序计数器 ++count; 操作就不是一个原子操作,因为它内部设计到读-改-写三个操作。
2.8CAS操作
CAS即campare and swap操作是jdk提供的非阻塞的原子操作,它通过硬件来保证“比较-更新”操作的原子性。
CAS中的一个经典问题ABA问题,该问题产生的原因就是变量产生了环形转换,也就是变量A->B->A
AtomicStampedReference能够解决ABA问题(通过给每一个变量加了一个时间戳)
2.9Unsafe类
提供了硬件级别的原子操作方法(不建议在代码中使用该类)。
2.10指令重拍
java内存模型允许编译器和处理器对指令进行重排序以提供性能,并且只会对不存在数据依赖行的指令重排序。
在单线程下指令重排序对最终结果没有影响,但是在多线程下就会存在问题。
2.11伪共享
要理解伪共享需要先理解cpu缓存(1级缓存,2级缓存,3级缓存)、缓存行等
CPU 是计算机的心脏,所有运算和程序最终都要由它来执行。为了解决cpu和主内存运行速度差的问题,会在CPU 和主内存之间设置好几级缓存,因为即使直接访问主内存也是非常慢的。
如果对一块数据做相同的运算多次,那么在执行运算的时候把它加载到离 CPU 很近的地方就有意义了(离cpu远近的缓存处理速度越快,其大小也就越小),比如一个循环计数,你不想每次循环都跑到主内存去取这个数据来增长它吧。

越靠近 CPU 的缓存越快也越小,所以 L1 缓存很小但很快,并且紧靠着在使用它的 CPU 内核。
L2 大一些,也慢一些,并且仍然只能被一个单独的 CPU 核使用。L3 在现代多核机器中更普遍,仍然更大,更慢,并且被单个插槽上的所有 CPU 核共享。
最后,主存保存着程序运行的所有数据,它更大,更慢,由全部插槽上的所有 CPU 核共享。
当 CPU 执行运算的时候,它先去 L1 查找所需的数据,再去 L2,然后是 L3,最后如果这些缓存中都没有,所需的数据就要去主内存拿,走得越远,运算耗费的时间就越长,所以如果进行一些很频繁的运算,要确保数据在 L1 缓存中。
cpu缓存行
缓存是由缓存行组成的,通常是 2的幂次数字节,例如64 字节(常用处理器的缓存行是 64 字节的,比较旧的处理器缓存行是 32 字节),并且它有效地引用主内存中的一块地址。
一个 Java 的 long 类型是 8 字节,因此在一个缓存行中可以存 8 个 long 类型的变量。


在程序运行的过程中,缓存每次更新都从主内存中加载连续的 64 个字节。因此,如果访问一个 long 类型的数组时,当数组中的一个值被加载到缓存中时,另外 7 个元素也会被加载到缓存中。
但是,如果使用的数据结构中的项在内存中不是彼此相邻的,比如链表,那么将得不到免费缓存加载带来的好处。
不过,这种免费加载也有一个坏处。设想如果我们有个 long 类型的变量 a,它不是数组的一部分,而是一个单独的变量,并且还有另外一个 long 类型的变量 b 紧挨着它,那么当加载 a 的时候将免费加载 b(前提这两个变量都是volatile修饰的)。
看起来似乎没有什么毛病,但是如果一个 CPU 核心的线程在对 a 进行修改,另一个 CPU 核心的线程却在对 b 进行读取。
当前者修改 a 时,会把 a 和 b 同时加载到前者核心的缓存行中,更新完 a 后其它所有包含 a 的缓存行都将失效,因为其它缓存中的 a 不是最新值了。而当后者读取 b 时,发现这个缓存行已经失效了,需要从主内存中重新加载。
请记住,我们的缓存都是以缓存行作为一个单位来处理的,所以失效 a 的缓存的同时,也会把 b 失效,反之亦然。

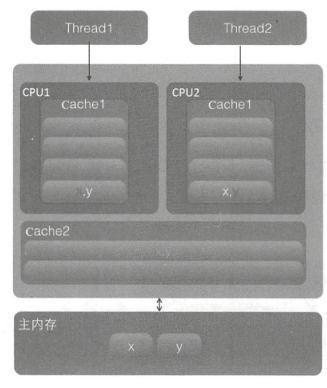
这样就出现了一个问题,b 和 a 完全不相干,每次却要因为 a 的更新需要从主内存重新读取,它被缓存未命中给拖慢了。这就是伪共享。
当多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,这就是伪共享。
我们来看看下面这个例子,充分说明了伪共享是怎么回事。
public class FalseSharingTest { public static void main(String[] args) throws InterruptedException { testPointer(new Pointer()); } private static void testPointer(Pointer pointer) throws InterruptedException { long start = System.currentTimeMillis(); Thread t1 = new Thread(() -> { for (int i = 0; i < 100000000; i++) { pointer.x++; } }); Thread t2 = new Thread(() -> { for (int i = 0; i < 100000000; i++) { pointer.y++; } }); t1.start(); t2.start(); t1.join(); t2.join(); System.out.println(System.currentTimeMillis() - start); System.out.println(pointer); } } class Pointer { volatile long x; volatile long y; }
这个例子中,我们声明了一个 Pointer 的类,它包含 x 和 y 两个变量(必须声明为volatile,保证可见性,关于内存屏障的东西我们后面再讲),一个线程对 x 进行自增1亿次,一个线程对 y 进行自增1亿次。
可以看到,x 和 y 完全没有任何关系,但是更新 x 的时候会把其它包含 x 的缓存行失效,同时也就失效了 y,运行这段程序输出的时间为3890ms。
伪共享的原理我们知道了,一个缓存行是 64 个字节,一个 long 类型是 8 个字节,所以避免伪共享也很简单,大概有以下三种方式:
(1)在两个 long 类型的变量之间再加 7 个 long 类型
我们把上面的Pointer改成下面这个结构:
class Pointer { volatile long x; long p1, p2, p3, p4, p5, p6, p7; // 添加这7个变量的原因就是让x和y不在一个缓存行中,这样修改x的时候,就不会影响到对y的操作 volatile long y; }
再次运行程序,会发现输出时间神奇的缩短为了695ms。
(2)重新创建自己的 long 类型,而不是 java 自带的 long
修改Pointer如下:
class Pointer { MyLong x = new MyLong(); MyLong y = new MyLong(); } class MyLong { volatile long value; long p1, p2, p3, p4, p5, p6, p7; // 同样是占用缓冲行的位置 }
同时把 pointer.x++; 修改为 pointer.x.value++;,把 pointer.y++; 修改为 pointer.y.value++;,再次运行程序发现时间是724ms。
(3)使用 @sun.misc.Contended 注解(java8)
修改 MyLong 如下:
@sun.misc.Contended class MyLong { volatile long value; }
默认使用这个注解是无效的,需要在JVM启动参数加上-XX:-RestrictContended才会生效,,再次运行程序发现时间是718ms。
注意,以上三种方式中的前两种是通过加字段的形式实现的,加的字段又没有地方使用,可能会被jvm优化掉,所以建议使用第三种方式。
(1)CPU具有多级缓存,越接近CPU的缓存越小也越快;
(2)CPU缓存中的数据是以缓存行为单位处理的;
(3)CPU缓存行能带来免费加载数据的好处,所以处理数组性能非常高;
(4)CPU缓存行也带来了弊端,多线程处理不相干的变量时会相互影响,也就是伪共享;
(5)避免伪共享的主要思路就是让不相干的变量不要出现在同一个缓存行中;
(6)一是每两个变量之间加七个 long 类型;
(7)二是创建自己的 long 类型,而不是用原生的;
(8)三是使用 java8 提供的注解;
2.12锁
乐观锁和悲观锁:事务性
公平锁和非公平锁:获取所的机制(先到先得就是公平,随机抢占就是非公平的)
独占所和共享锁:能够被多个线程共同持有
可重入锁:持有锁的对象是自己时,不会被阻塞
自旋锁:当线程在获取锁的时候,发现锁已被其他线程占用,此时该线程并不会立刻阻塞,而是循环多次获取(默认次数为10次),扔获取不到时,才会阻塞线程。其中阻塞此时可以设置-XX:PreBlockSpinsh