怎么说呢,静态的页面,但我也写了动态的接口支持,方便后续爬取别的新闻网站使用。
一个接口,接口有一个抽象方法pullNews用于拉新闻,有一个默认方法用于获取新闻首页:
public interface NewsPuller {
void pullNews();
// url:即新闻首页url
// useHtmlUnit:是否使用htmlunit
default Document getHtmlFromUrl(String url, boolean useHtmlUnit) throws Exception {
if (!useHtmlUnit) {
return Jsoup.connect(url)
//模拟火狐浏览器
.userAgent("Mozilla/4.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)")
.get();
} else {
WebClient webClient = new WebClient(BrowserVersion.CHROME);
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setActiveXNative(false);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setThrowExceptionOnScriptError(false);
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);
webClient.getOptions().setTimeout(10000);
HtmlPage htmlPage = null;
try {
htmlPage = webClient.getPage(url);
webClient.waitForBackgroundJavaScript(10000);
String htmlString = htmlPage.asXml();
return Jsoup.parse(htmlString);
} finally {
webClient.close();
}
}
}
}
之后就是爬虫;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.FailingHttpStatusCodeException;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.WebConsole.Logger;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
import java.io.IOException;
import java.net.MalformedURLException;
import java.util.Date;
import java.util.HashSet;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.slf4j.LoggerFactory;
public class SohuNewsPuller implements NewsPuller {
public static void main(String []args) {
System.out.println("123");
SohuNewsPuller ss=new SohuNewsPuller();
ss.pullNews();
}
private String url="http://news.sohu.com/";
public void pullNews() {
Document html= null;
try {
html = getHtmlFromUrl(url, false);
} catch (Exception e) {
e.printStackTrace();
return;
}
// 2.jsoup获取新闻<a>标签
Elements newsATags = html.select("div.focus-news")
.select("div.list16")
.select("li")
.select("a");
for (Element a : newsATags) {
String url = a.attr("href");
System.out.println("内容"+a.text());
Document newsHtml = null;
try {
newsHtml = getHtmlFromUrl(url, false);
Element newsContent = newsHtml.select("div#article-container")
.select("div.main")
.select("div.text")
.first();
String title1 = newsContent.select("div.text-title").select("h1").text();
String content = newsContent.select("article.article").first().text();
System.out.println("url"+"\n"+title1+"\n"+content);
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
结果:
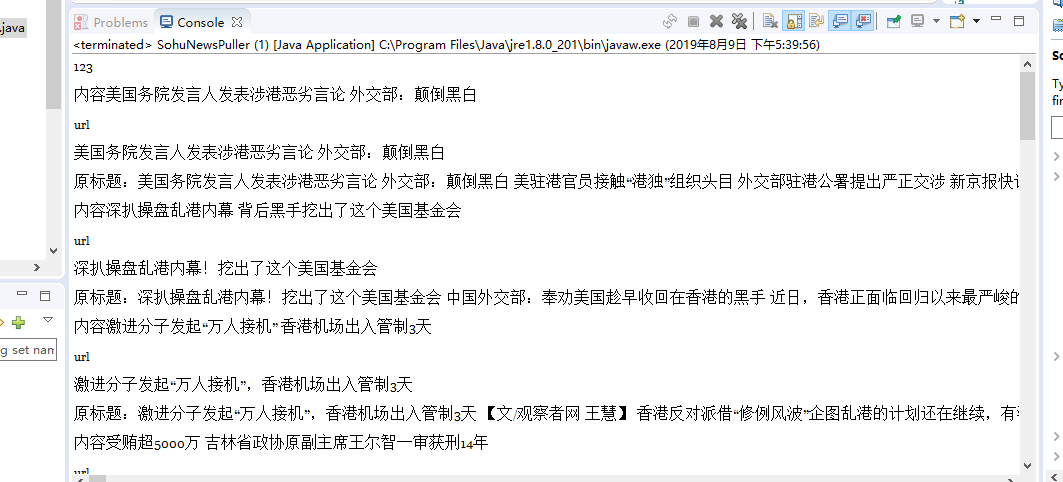
当然还没有清洗内容,后续会清洗以及爬取动态网站啥的。
参考博客:https://blog.csdn.net/gx304419380/article/details/80619043#commentsedit
代码已上传github:https://github.com/mmmjh/GetSouhuNews
欢迎吐槽!!!!
绝大部分代码是参考的人家的博客。我只是把项目还原了。