一、什么是爬虫
互联网就像一张蜘蛛网,爬虫相当于蜘蛛,数据相当于猎物
2、爬虫的具体定义:
模拟浏览器向后端发送请求,获取数据,解析并且获得我想要的数据,然后存储
3、爬虫的价值:
数据的价值
发送请求(requests)——获取数据——解析数据(bs4,pyquery,re)——存储数据
二、
1、请求
url:指明了我要去哪里
method:
get:传递数据:?&拼在url后面
post:请求体:formdata,files,json
请求头:
Cookie:验证用户的登录
扫描二维码关注公众号,回复:
6966405 查看本文章

Referer:告诉服务器你从哪里来(例子:图片防盗链)
User-Agent:告诉服务器你的身份
2、响应
Status Code状态码:
2xx:成功
3xx:重定向
响应头:
location
响应对象 = requests.get(......) 参数: url headers = {} # headers里面的Cookie优先级高于cookies cookies = {} params = {} # 参数 proxies = {'http':‘http://端口:ip’} # 代理ip timeout = 0.5 # 超时时间 allow_redirects = False # 允许重定向,不写默认是True。设置成False,不允许重定向
代码
import requests from requests.exceptions import ConnectTimeout url = 'http://httpbin.org/get' # url = 'http://www.baidu.com' headers = { 'Referer': 'https://baike.baidu.com/item/%E8%8B%8D%E4%BA%95%E7%A9%BA%E6%95%88%E5%BA%94/6527087?fr=aladdin', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36', 'Cookie': 'egon' } cookies = { 'xxx': 'dsb', 'yyy': 'hahaha', } params = { 'name': 'mac', 'age': '16' } try: r = requests.get(url=url, headers=headers, cookies=cookies, params=params, timeout=5) print(r.text) # r = requests.get(url=url, headers=headers, cookies=cookies, params=params, allow_redirects=False) # print(r.url) except ConnectTimeout: print('进行其他操作')
打印结果
{ "args": { "age": "16", "name": "mac" }, "headers": { "Accept": "*/*", "Accept-Encoding": "gzip, deflate", "Cookie": "egon", "Host": "httpbin.org", "Referer": "https://baike.baidu.com/item/%E8%8B%8D%E4%BA%95%E7%A9%BA%E6%95%88%E5%BA%94/6527087?fr=aladdin", "User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36" }, "origin": "223.167.30.218, 223.167.30.218", "url": "https://httpbin.org/get?name=mac&age=16" }
响应对象 = requests.post(......) 参数: url headers = {} cookies = {} data = {} json = {} files = {‘file’:open(...,‘rb’)} timeout = 0.5 allow_redirects = False
代码
import requests from requests.exceptions import ConnectTimeout url = 'http://httpbin.org/post' # url = 'http://www.baidu.com' headers = { 'Referer': 'https://baike.baidu.com/item/%E8%8B%8D%E4%BA%95%E7%A9%BA%E6%95%88%E5%BA%94/6527087?fr=aladdin', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36', 'Cookie': 'egon' } cookies = { 'xxx': 'dsb', 'yyy': 'hahaha', } data = { 'name': 'mac', 'password': 'abc123' } json = { 'xxx': 'xxx', 'yyy': 'yyy' } files = { 'file': open('1.txt', 'rb') } try: # r = requests.post(url=url, headers=headers, cookies=cookies, data=data, timeout=5) # data=data模拟form表单 # r = requests.post(url=url, headers=headers, cookies=cookies, json=json, timeout=5) # json=json发json数据 r = requests.post(url=url, headers=headers, cookies=cookies, data=data, files=files, timeout=5) # 模拟注册 print(r.text) # r = requests.get(url=url, headers=headers, cookies=cookies, data=data, allow_redirects=False) # print(r.url) except ConnectTimeout: print('进行其他操作')
打印结果
{ "args": {}, "data": "", "files": { "file": "abcdefghijklmn" }, "form": { "name": "mac", "password": "abc123" }, "headers": { "Accept": "*/*", "Accept-Encoding": "gzip, deflate", "Content-Length": "338", "Content-Type": "multipart/form-data; boundary=c7c8c676d7f232259827977daaa20412", "Cookie": "egon", "Host": "httpbin.org", "Referer": "https://baike.baidu.com/item/%E8%8B%8D%E4%BA%95%E7%A9%BA%E6%95%88%E5%BA%94/6527087?fr=aladdin", "User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36" }, "json": null, "origin": "223.167.30.218, 223.167.30.218", "url": "https://httpbin.org/post" }
自动保存cookie的请求
import requests session = requests.session() # 记录每一次请求的cookie url1 = 'https://www.lagou.com' r = session.get(url=url1) print(session.cookies) url2 = 'https://www.github.com' r2 = session.get(url=url2) print(session.cookies) 结果为: # <RequestsCookieJar[<Cookie JSESSIONID=ABAAABAABEEAAJA52562AD095370A108C9943E2088FDB22 for www.lagou.com/>]> # <RequestsCookieJar[<Cookie _octo=GH1.1.1145368561.1565088576 for .github.com/>, <Cookie logged_in=no for .github.com/>, <Cookie _gh_sess=YXhBUXgrcFNyWUFJOWNJdmtzYk9yT1l6WUVzR0xlTFIxVGhPbzBma05NZkI0M056aHdickh2STY2VDA5Q09VdHN4WFlGNW1waVAzaEVVMXl0dElqVTN1SXowNnQ5TmNsMTg4QVBicTc3Sko1QXhyY01lVTd5Yk1ad0d2U01Bbm1saFJCZnFxY2ZzeitKNWo1Z09QQ1ZVZy9IYkpCenFZdE1hTndSZHl5alQvSFd2RGtUTkJ5a2RyTjhhdkgxbjdyR2JtTlpLdzI1bTBFR2c0WjZPUzJCdz09LS1ZdVNtbjJaR2l6TzVRNE1aRXkvR0lBPT0%3D--5b92d0e4c31fe84e0a2acddc3c0529d863867c1c for github.com/>, <Cookie has_recent_activity=1 for github.com/>, <Cookie JSESSIONID=ABAAABAABEEAAJA52562AD095370A108C9943E2088FDB22 for www.lagou.com/>]>
补充:保存cookie到本地
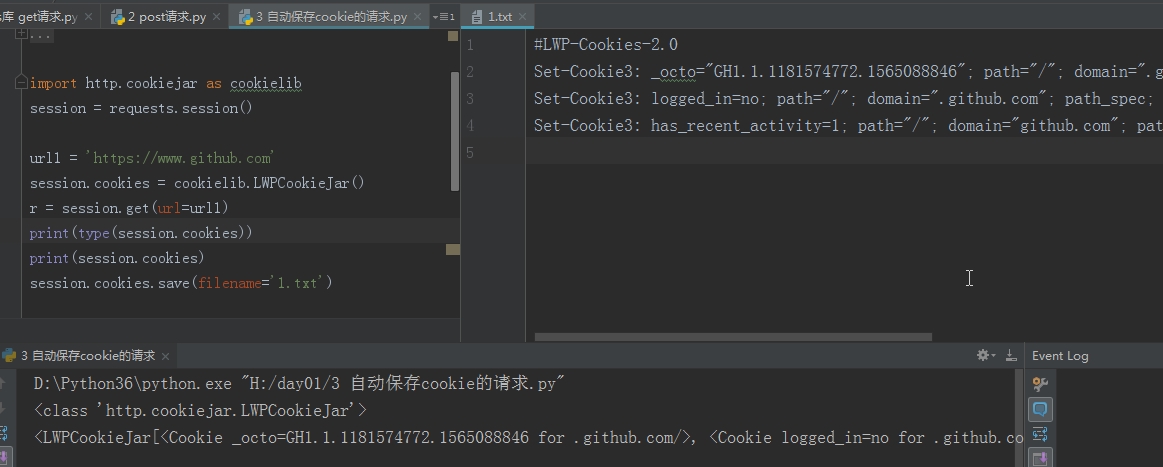
r.url r.text r.encoding = 'UTF-8' r.content r.json() r.status_code r.headers r.cookies r.history
代码
import requests session = requests.session() r = session.get('https://www.baidu.com') r.encoding = 'UTF-8' # 指定编码格式,不指定会乱码 print(r.text) r = session.get(url='https://movie.douban.com/j/new_search_subjects?sort=U&range=0,10&tags=&start=20') print(r.text) print(r.json()) # 转成python格式 print(r.status_code) r = session.get('http://www.tmall.com') print(r.url) # https://www.tmall.com/ print(r.status_code) # 200 print(r.history[0].status_code) # 302
1、类选择器 2、id选择器 3、标签选择器 4、后代选择器 5、子选择器 6、属性选择器 7、群组选择器 8、多条件选择器
from requests_html import HTMLSession session = HTMLSession() r = session.get('https://www.baidu.com') r = session.post('https://www.baidu.com') r = session.request(url='https://www.baidu.com', method='get')
from requests_html import HTMLSession session = HTMLSession() # r = session.get('http://www.xiaohuar.com/p-1-2077.html') # print(r.html.absolute_links) # 绝对链接 # print(r.html.links) # 原样链接 # print(r.html.base_url) # 基础链接 r = session.get('http://www.xiaohuar.com/p-3-230.html') r.html.encoding = 'GBK' # 不指定会乱码 # print(r.html.html) # print(r.html.text) # 文本内容 # print(r.html.raw_html) # 二进制流 # print(r.html.pq) # pyquery