2019-08-01
关键字:Android解析XML、XML格式、XML含义
本文简要介绍了 XML 以及它在 Android 下的解析方法。
1、XML 简介
XML 是一种用于传输和存储数据的数据格式。全称为 Extensible markup language。XML 是纯文本形式的,它的语法与格式要求很简单,因此在互联网领域有着非常广泛的应用。
XML的结构
以下是一个标准的 XML 数据结构形式:
1 <?xml version="1.0" encoding="utf-8"?> 2 <address> 3 <server> 4 <ip>224.1.1.2</ip> 5 <port>2002</port> 6 </server> 7 </address>
XML 主要由两个部分构成:声明体与内容体。
上述示例第 1 行所示即是声明体。它一般用于描述该 XML 语法的版本与字符编码。一般都不需要去关注这部分的内容,解析器在解析 XML 格式时也会自动跳过这部分内容。
内容体则对应着上述示例的第 2 ~ 7 行。它是整个 XML 的核心。所有要被传输和存储的数据都记载在这个内容体里。一般一个 XML 文件就包含一个根标签,就是上面示例的 <address> </address> 标签对。根标签的作用可以与 Linux 文件系统类比,在 Linux 中,整个文件系统都是从根目录 / 开始的,XML 中也一样,所有要传输和存储的数据都是从这个根标签开始的。
从上述示例中可以看到,XML 的语法是支持嵌套的。这就意味着,我们可以自由地设计嵌套关系,以便更清晰合理地管理数据。
XML的语法
XML 的语法规则并不复杂,以下列出几个常见的语法规则。
规则一:闭合
XML 要求所有的标签都得是闭合的。即必须显式声明起始标签和结束标签。
起始标签和结束标签在字符内容上完全一样,唯一的区别就是结束标签的字符前面有一个 / 符号。
例如: <server> </server> , <ip> </ip>。
数据内容可以直接放在起始标签和结束标签之间。例如,一个记录手机号码的 XML 标签格式为:<phone>13172717561</phone>。
另外,结束标签可以简写。
如果一个 XML 标签在起始和结束标签之间不需要记载什么信息,那么结束标签可以简写。例如,这以下两个标签是完全等价的:
<server> </server> , <server />
规则二:大小写敏感
XML 标签对大小写是敏感的。一对标签中,所有字符的大小写必须一致。
这是正确的标签形式: <server> </server>
这是错误的标签形式: <server> </Server>
规则三:嵌套
XML 标签是支持嵌套的,并且不限嵌套次数。这点从文章首部的示例就可以看出来。
并且,XML 的标签层级关系与 Linux 的文件系统层级关系如出一辙。
在 Linux 的文件系统中,一个路径下即可以直接保存数据,也可以嵌套保存子目录,进而在子目录中保存数据。XML 如是。一个 XML 标签内既可以创建子标签,也可以直接保存数据,子标签和数据当然也可以共存。
例如,下图所示的 XML 语法是正确的:
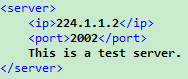
在上图所示的 XML 标签中,可以正确地读取到标签 ip 的内容是 224.1.1.2,可以正确读取到标签 port 的内容是 2002,当然也可以正确地读取到标签 server 的内容是 This is a test server.。
不过这里有一点需要注意的是:起始标签和结束标签之间所有没有子标签修饰的内容都是该标签的内容。
怎么理解呢?即在上图示例中,标签 server 的内容可不仅仅是 "This is a test server." 而已。标签 server 的内容除了那些看得见的文本,还包含它前面和后面那些看不见的空格字符、Tab 字符或者其它看不见的字符。如果这句话是多行的,那标签 server 的内容也是多行的。所以,假设上图示例字符串前面是四个空格字符,那么标签 server 的内容应该是 " This is a test server."。
规则四:属性值标引号
XML 的起始标签内部允许添加若干个属性键值对。这些键值对也可以存储信息。例如:

当然,一般我们为了层级关系更清晰,会做一些适当的排版操作。形如:

这些属性键值对的值必须以双引号修饰。
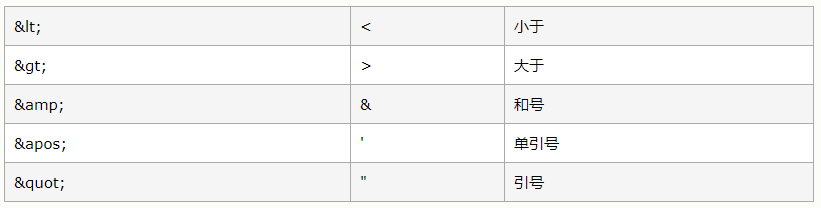
规则五:转义
在 XML 中有几个特殊字符不能直接出现在内容中,否则可能会引发解析错误。这些特殊字符应以转义形式代替。具体如下所示
规则六:注释
XML 中注释的格式为: <!-- 注释内容 -->
规则七:空格合并
XML 中内容里的空格数量不会被压缩。你原本有几个空格字符,解析出来后就是几个。不像 HTML 标签那样连续多个空格字符会被压缩成一个。
2、Android下如何解析XML?
XML 的语法和结构还是比较简单的。因此如果有兴趣的话我们完全可以自己开发一个 XML 解析器出来。当然,网上已经有很多非常成熟的 XML 解析器了,想缩短开发周期的话也可以直接使用现成的解析接口。
Android 本身并没有提供 XML 解析程序。但是它集成了打包在 Java 中的解析器。在编程过程中也是可以直接使用的。
XML 的解析目前主要有三种形式:
1、SAL
2、DOM
3、PULL
SAL
这种形式是在扫描到标签的起始与结束时发出相应的通知。然后根据你在相应的通知回调方法处的实现方式来解析标签内容与属性。
这种形式是比较麻烦的一种形式。因为它需要我们根据不同类型的 XML 编写不同形式的解析实现。它会灵活一点,但同时它的工作量也比较大。
它的读取形式是流式的。
这种形式的特点是解析速度比较快,并且占用的内存比较小。
SAL 解析形式被封装在 org.xml.sax.helpers.DefaultHandler 中。
DOM
这种形式是一次性将整个 XML 都读入到内存中。它的使用比较简单,也没有什么工作量。缺点就是对于大 XML 文件,内存的占用会比较高。
DOM 解析形式被封装在 javax.xml.parsers.DocumentBuilderFactory 与 javax.xml.parsers.DocumentBuilder 中。
PULL
这种形式与 SAL 形式类似。好处就是不需要我们编写解析实现方法。它会按顺序逐个读取标签中的属性与内容。
它的读取形式也是流式的。
PULL 解析形式被封装在 org.xmlpull.v1.XmlPullParserFactory 与 org.xmlpull.v1.XmlPullParser 中。
3、XML 解析实例
日常工作中常见的 XML 形式无非就是些嵌套的、带属性的、带内容的。笔者这里以 PULL 解析形式写一个解析这种形式的 XML 的示例程序。
假设要解析的 XML 如下所示:
<?xml version="1.0" encoding="utf-8"?> <address> <server location="lab1" manager="chorm"> <ip>224.1.1.1</ip> <port>2001</port> </server> <Computer brand="lenovo" user="lemontea"> <system>cent os 7</system> <password value="admin" /> The memory is up to 32GB. </Computer> </address>
下面开始在 Android 上编写解析代码。
第一步是创建 PULL 型 XML 解析器对象。
XmlPullParserFactory factory = XmlPullParserFactory.newInstance(); XmlPullParser xpp = factory.newPullParser(); xpp.setInput(new FileInputStream("address.xml"), "UTF-8");
第二步是读取事件类型。
int et = xpp.getEventType();
第三步是编写解析这些标签的逻辑代码。
while(et != XmlPullParser.END_DOCUMENT) { switch(et) { case XmlPullParser.START_DOCUMENT:{ // do nothing. }break; case XmlPullParser.START_TAG:{ String tagName = xpp.getName(); if("server".equals(tagName)) { log("server"); String location = xpp.getAttributeValue(null, "location"); String manager = xpp.getAttributeValue(null, "manager"); log("location:" + location + ",manager:" + manager); }else if("ip".equals(tagName)) { //直接读取这个标签后面的内容。 //执行了 nextText() 以后,标签ip内部的属性就读取不到了。 final String ip = xpp.nextText(); log("ip:" + ip); }else if("port".equals(tagName)) { final String port = xpp.nextText(); log("port:" + port); }else if("Computer".equals(tagName)) { log("Computer"); //遍历内部的所有属性。 for(int i = 0; i < xpp.getAttributeCount(); i++) { log(xpp.getAttributeName(i) + ":" + xpp.getAttributeValue(i)); } }else if("system".equals(tagName)){ String system = xpp.nextText(); log("system:" + system); }else if("password".equals(tagName)){ String psw = xpp.getAttributeValue(null, "value"); log("password:" + psw); }else { } }break; case XmlPullParser.TEXT:{ String txt = xpp.getText(); log("+" + txt); }break; case XmlPullParser.END_TAG:{ // do nothing. }break; } et = xpp.next(); }
这段代码运行以后得到的打印结果如下:
D/VAM (17133): + D/VAM (17133): D/VAM (17133): D/VAM (17133): server D/VAM (17133): location:lab1,manager:chorm D/VAM (17133): + D/VAM (17133): D/VAM (17133): D/VAM (17133): ip:224.1.1.1 D/VAM (17133): + D/VAM (17133): D/VAM (17133): port:2001 D/VAM (17133): + D/VAM (17133): D/VAM (17133): + D/VAM (17133): D/VAM (17133): D/VAM (17133): Computer D/VAM (17133): brand:lenovo D/VAM (17133): user:lemontea D/VAM (17133): + D/VAM (17133): D/VAM (17133): D/VAM (17133): system:cent os 7 D/VAM (17133): + D/VAM (17133): D/VAM (17133): password:admin D/VAM (17133): + D/VAM (17133): The memory is up to 32GB. D/VAM (17133): D/VAM (17133): D/VAM (17133): D/VAM (17133): + D/VAM (17133):
是不是感觉这个打印有点奇怪?为什么会有这么多的空行呢?
其实,产生这么多空行的根本原因还是在于前面提到过的:PULL 解析也是流式的以及起始标签与结束标签之间的非标签修饰字符都属于内容。
我们用 notepad++ 来打开待解析的 XML 文档,看看它的字符形式是什么样的:

流式解析意味着它会按照顺序从头解析到尾,再根据我们写的处理代码,读到什么打印什么。
首先读取到的是起始标签 <address>。然后是内容,第一个读取到的内容是 CRLF 与一个 Tab 字符,然后又是一个 CRLF 字符,再然后又是一个 Tag 字符。再往下就读到起始标签 <server> 了,到这就暂停了。前面读取到的一串都属性 “内容”,要先打印出来。根据上面我们写的代码:

打印出来以后的形式就是

所以,前面我们得到的打印是正确的!
除了我们看得见的字符,还应该注意不要忽略那些我们看不见的字符。照着这种解析规则逐一解析整个 XML 文档,就得到上面贴出来的打印形式了。
上面的解析 XML 的代码中,也变换了好几种读取属性与内容的方法调用。大家根据自己的实际业务需要来选择使用就可以了。
参考文献: https://www.runoob.com/w3cnote/android-tutorial-xml.html