前言
其实我现在还不懂内核树是个什么东西?
为什么写驱动要编译内核树,不是只用头文件就好了吗?
反正昨天是搭建好了驱动开发环境(仅仅是安装了对应的操作系统和一些工具),现在记录一下编译内核的过程。
编译好的内核
先来看下编译好之后的内核是个什么样子的。
这个图是刚启动的时候,如果啥也不干直接进入到 2.6.25-14 版本的内核中:
图 1 系统启动界面
然后上面有个提示:Press any key to enter the menu,我们随便安一个键:

图 2 内核选择界面
可以看到出现了两个版本:
- Fedora (2.6.29.4)
- Fedora (2.6.25-14.fc9.i686)
版本高的那个是我从书上照葫芦画瓢编译出来的,倒是没有出现啥问题,很顺利。
但是其实原理我是不知道的,比如:
- 虚拟机有两个内核共存的原理是什么?
- 以前安装的软件也是它们共用吗?不会有版本冲突么?
- make menuconfig 怎么用?
- 为什么要升级版本?
希望写完这篇,我自己能搞懂上面的问题,然后对于其他版本的内核树也可以随心所欲的编译和使用。
理论学习
内核
内核是一个提供硬件抽象层、磁盘及文件系统控制、多任务等功能的系统软件。
根据内核是否被修改过,可以将内核分为标准内核和厂商内核两类。
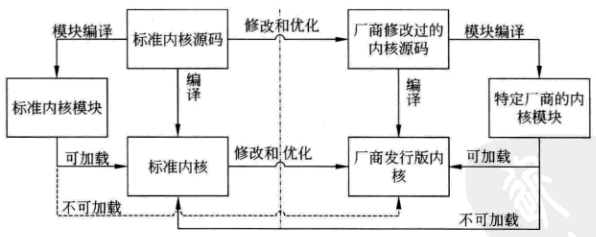
图 3 内核与模块版本之间的关系
标准内核源码和标准内核
标准内核源码是指从 kernel.org 官方网站下载的标准代码。
它是 Linux 内核开发者经过严格测试所构建的内核代码。
标准内核是将标准内核源码编译后得到的二进制映像文件,如图 3 左半部所示。
厂商内核源码和厂商内核
在某些情况下,发型版厂商会对标准内核源码进行适当的修改,以优化内核性能。
这种经过修改后的标准内核源码,就是厂商修改过的内核源码。
将厂商修改过的内核源码编译后,会形成厂商发型版内核。
所以,厂商发行版内核是对标准内核的修改和优化。
这里,需要注意的是,厂商发型版本内核和标准内核对于驱动程序是不兼容的,根据不同内核源码编译出来的驱动程序是不能互用的。
两者兼容性问题
构建驱动程序模块时,必须考虑驱动程序与内核的兼容性。
使用标准内核源码构建的内核模块,就是标准内核模块,其不能在厂商内核中使用。
使用厂商修改过的内核源码构建的内核模块,就是特定厂商的内核模块,其不能在标准内核中使用。
这里,需要注意的是,即使模块代码相同,标准内核模块和特定厂商的内核模块,其模块格式也是不同的。
标准内核模块可以加载进标准内核中,却不能加载进厂商发型内核中。
同理,特定厂商的内核模块可以加载进厂商发行版内核中,却不能加载进标准内核中。
Fedora Core 9 的内核版本是 2.6.25-14.fc9.i686,可以通过 uname -r 来查看。
如果要编写特定厂商的内核模块,那么就要找到 Fedora Core 9 的内核源码。
Fedora Core 9 并没有默认安装内核源码,并且程序员也很难找到该源码。
所以,这里将采用目前较新的标准内核源码来构建内核模块。
这就是将要升级内核的原因。
多个内核版本共存原理
找出系统已经安装的内核版本,删除Linux多余的内核
查询当前系统版本:cat /proc/version
找出系统已经安装的内核版本
ubuntu命令:$ dpkg --get-selections | grep linux-image
fedora命令:$ su -c 'rpm -qa kernel'
卸载旧的内核版本
ubuntu 命令:$ sudo apt-get remove linux-image-2.6.35-22-generic //删除旧的内核
fedora 命令:$ su -c 'yum remove kernel-3.10.0-693.el7.x86_64' //注意替换成上面列出的内核项目
重新启动:reboot
一个linux系统里面能有多个kernel吗?如果可以应该怎么添加呢?
能有多个 kernel 但这是启动系统的东西,只能用一个。
内核在 /boot 里面,vmlinuz 那些个就是,其他的文件都是辅助用的。其中还有用的是 initrd ,这东西是随内核一起被引导器——现在基本就是 GRUB ——一起读取到内存中,内核启动后会读取这里的文件,并且把它作为临时的根文件系统,之后再过渡启动到硬盘。不过 initrd 不是必须存在的,他因为在启动内核时一同读取到内存,所以他的硬件限制很少,可以作为提供驱动的数据文件,也可以实现一些挂载你的硬盘跟分区前的检测工作。
/lib/modules/ 里面都是按内核版本号分别保存的其他内核需要和提供的文件,主要是内核模块。以及针对这个内核的开发需要的相应文件(不光是头文件,虽然开发主要是需要 C Header)。
模块目录具体结构请看一些专业的介绍资料吧。
题外:/usr/src 里面一般存放内核的源代码,如果是自己编译的内核,或者某些特殊情况的内核。这里也会放一些东西。/lib/modules 里面的内核其他数据目录里面会有一些内容连接到这里的。这个规划具体看发行版的设计。不过一般大家的习惯是这里必然有内核源代码,所以很多驱动程序和内核有关的一些应用程序,都会直接来这里找开发数据。所以现在大部分系统偏向于这里保存一些内容。
加载内核镜像
内核映像并不是一个可执行的内核,而是一个压缩过的内核映像。通常它是一个 zImage(压缩映像,小于 512KB)或一个 bzImage(较大的压缩映像,大于 512KB),它是提前使用 zlib 进行压缩过的。在这个内核映像前面是一个例程,它实现少量硬件设置,并对内核映像中包含的内核进行解压,然后将其放入高端内存中,如果有初始 RAM 磁盘映像,就会将它移动到内存中,并标明以后使用。然后该例程会调用内核,并开始启动内核引导的过程。
当 bzImage(用于 i386 映像)被调用时,我们从 ./arch/i386/boot/head.S 的 start 汇编例程开始执行。
这个例程会执行一些基本的硬件设置,并调用 ./arch/i386/boot/compressed/head.S 中的 startup_32,设置一个基本的环境(堆栈等),并清除 Block Started by Symbol(BSS)。然后调用一个叫做 decompress_kernel 的 C 函数(在 ./arch/i386/boot/compressed/misc.c 中)来解压内核。当内核被解压到内存中之后,就可以调用它了。这是另外一个 startup_32 函数,但是这个函数在 ./arch/i386/kernel/head.S 中。
内核和根文件系统
待完成。
多个内核版本可以共用程序的原因
这其实是内核系统与应用程序的关系。
在Linux系统中,内核为用户程序提供了两方面的支持。其一是系统调用接口,另一方面是通过开发环境库函数或内核库函数与内核进行信息交流。不过内核库函数仅供内核创建的任务0和任务1使用,它们最终还是去调用系统调用。
系统调用主要提供给系统软件编程或者用于库函数的实现。而一般用户开发的程序则是通过调用像libc等库函数来访问内核资源。这些库中的函数或资源通常被称为应用程序编程接口(API),其中定义了应用程序使用的一组标准编程接口。通过调用这些库中的程序,应用程序代码能够完成各种常用工作,例如,打开和关闭对文件或设备的访问、进行科学计算、出错处理以及访问组和用户标识号ID等系统信息。
API与系统调用的区别在于:为了实现某一应用程序接口标准,例如POSIX,其中的API可以与一个系统调用对应,也可能由几个系统调用的功能共同实现。当然某些API函数可能根本就不需要使用系统调用,即不使用内核功能。因此函数库可以看做实现像POSIX标准的主体界面,应用程序不用管它与系统调用之间到底存在什么关系。无论一个操作系统提供的系统调用有多么大的区别,但只要它遵循同一个API标准,那么应用程序就可以在这些操作系统之间具有可移植性。
系统调用是内核与外界接口的最高层。在内核中,每个系统调用都有一个序列号(在include/unistd.h头文件中定义),并且常以宏的形式实现。应用程序不应该直接使用系统调用,因为这样的话,程序的移植性就不好了。因此目前Linux标准库(Linux Standard Base,LSB)和许多其他标准都不允许应用程序直接访问系统调用宏。
库函数一般包括C语言没有提供的执行高级功能的用户级函数,如输入/输出和字符串处理函数。某些库函数只是系统调用的增强功能版。例如,标准I/O库函数fopen和fclose提供了与系统调用open和close类似的功能,不过是在更高的层次上。在这种情况下,系统调用通常能提供比库函数略微好一些的性能,但是库函数却能提供更多的功能,而且更具检错能力。
结论:只要应用程序编程接口是相同的,那么不同的内核版本可以使用相同的应用程序,所以不同的内核版本在这个前提下是可以共用应用软件的。比如,有些程序可以在 Win 7 和 Win 10 下同时使用,就是因为不同的内核版本提供了相同的 API。
不知道这个理解对不对。
学了半天理论,下面开始正式进入内核树的编译了。
内核树的编译