发现问题
日常巡查数据入库情况时,发现最新数据的入库时间停在了凌晨。立刻登录远程服务器,尝试定位问题。
定时任务是否正常工作,是否有报错信息
crontab -l经检查发现,定时任务工作正常,也没有运行报错的记录。
查看系统进程,采集程序是否运行
ps -ef | grep xxxappspider输出信息如下

可以看到进程在凌晨 01:40 成功启动了,但是一直没有执行完成,推测是代码出现了死锁等问题?查看日志也没有记录到有用的信息。
检查代码,尝试复现该bug
在服务器手动执行程序,均能正常运行。简单复查代码,也没有发现哪里会导致死锁。
解决问题
由于手头还有比较急的任务,只是给程序加上了更详细的日志记录,然后 kill 掉卡住的进程,让定时任务重新运行起来。
第二天问题再次出现,同样是凌晨的定时任务出现了卡死的情况。首先排除服务器原因,相同服务器其他任务均正常运行。其次排除存储原因,我们的采集结果是统一入到 Kafka 队列,经过一系列的操作后存储到数据库的。这个 Kafka 队列所有应用都在使用,如果出现问题不会只这一个任务。然后大致可以确定,是这个任务在凌晨运行时,会因为某些原因导致卡死。

好了,是时候祭出我们的大杀器: py-spy
这是一个 Python 的性能分析工具,我是在听《捕蛇者说》的时候了解到的这个库,现在正好拿来用用。
先简单看下怎么用:
[test@localhost ~]# py-spy --help
py-spy 0.1.11
A sampling profiler for Python programs
USAGE:
py-spy [FLAGS] [OPTIONS] --pid <pid> [python_program]...
FLAGS:
--dump Dump the current stack traces to stdout
-F, --function Aggregate samples by function name instead of by line number
-h, --help Prints help information
--nonblocking Don't pause the python process when collecting samples. Setting this option will reduce the
perfomance impact of sampling, but may lead to inaccurate results
-V, --version Prints version information
OPTIONS:
-d, --duration <duration> The number of seconds to sample for when generating a flame graph [default: 2]
-f, --flame <flamefile> Generate a flame graph and write to a file
-p, --pid <pid> PID of a running python program to spy on
-r, --rate <rate> The number of samples to collect per second [default: 100]
ARGS:
<python_program>... commandline of a python program to run
只需要输入 Python 进程的 pid 就能直观的显示该进程中各项任务的耗时情况。更重要的是,它不需要重启代码就能运行,非常适合我们现在遇到的情况。
安装很简单:
pip install py-spy使用很简单:
# 先找到这个卡住的Python进程的pid
ps -ef |grep python |grep ***
# 启动 py-spy 观察这进程
py-spy --pid 32179输出信息如下:
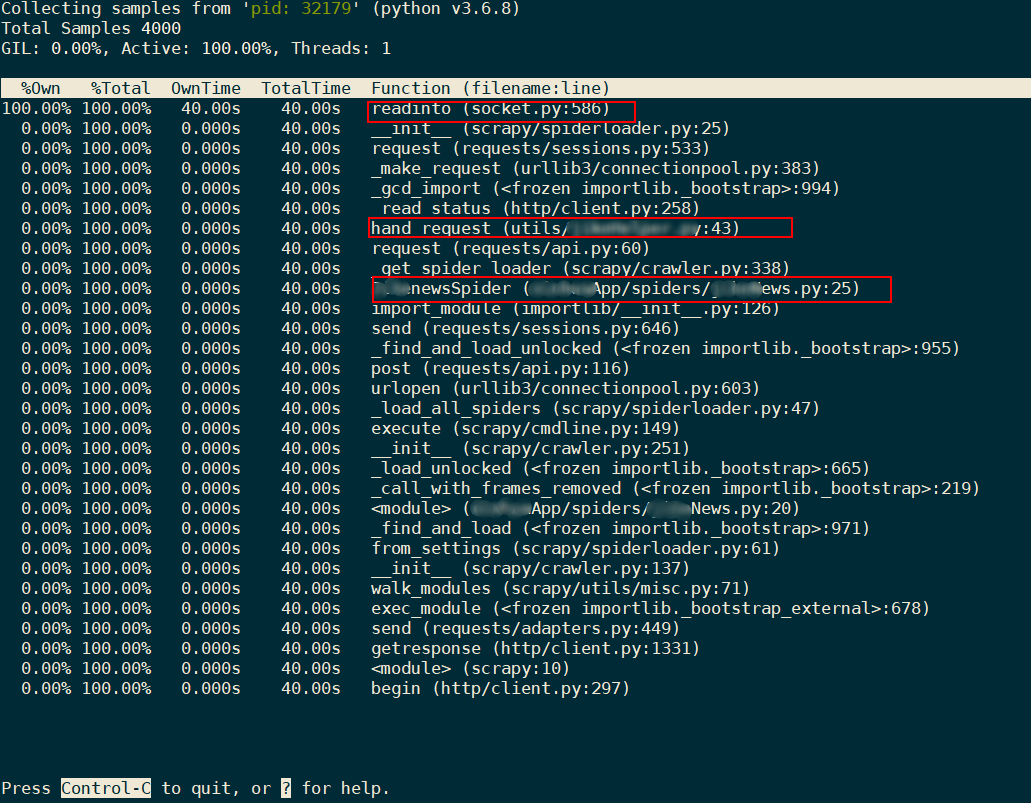
可以看到,程序是卡在了建立网络连接的部分。hand_request是一个为某个App请求签名的函数,被单独放在了utils这个目录下。接下来就简单了,找到这个函数,在第43行,发现了一个 post 请求。嗯,其实不管是 post 还是 get 都不要紧,重要的是这个请求没有加 timeout 参数!!!
Requests 文档里写的很清楚了,如果没有超时参数,程序有可能永远失去响应。
超时
你可以告诉 requests 在经过以
timeout参数设定的秒数时间之后停止等待响应。基本上所有的生产代码都应该使用这一参数。如果不使用,你的程序可能会永远失去响应:>>> requests.get('http://github.com', timeout=0.001) Traceback (most recent call last): File "<stdin>", line 1, in <module> requests.exceptions.Timeout: HTTPConnectionPool(host='github.com', port=80): Request timed out. (timeout=0.001)注意
timeout仅对连接过程有效,与响应体的下载无关。timeout并不是整个下载响应的时间限制,而是如果服务器在timeout秒内没有应答,将会引发一个异常(更精确地说,是在timeout秒内没有从基础套接字上接收到任何字节的数据时)If no timeout is specified explicitly, requests do not time out.
至此,Debug完成。
总结
这么低级的 bug,确实是我自己写的。
当初写的时候忽视了这个问题,测试的时候没有发现问题也就过去了。第一次发现问题的时候,查问题并不仔细,只简单看了spiders目录下的几个爬虫代码,没有去检查utils目录下的工具类的代码,故而并没有找到具体问题。第二次通过 py-spy 的帮助,成功找到并解决了问题。
解决问题后,反思下原因:很可能是这个 App 会在凌晨进行维护,导致请求没有得到响应,同时没有设置超时函数,程序就会一直卡在哪里。
最后,推荐一下《捕蛇者说》,这是一个关于“编程、程序员、Python”的中文博客。没事听听大佬们唠嗑,真的很涨知识。