目录
容器的资源限制
服务质量
requests( 资源需求,最低保障 ):
limits( 资源限制,硬限制 ):
CPU: 指CPU线程,一个线程 1000m
内存
QoS Class:自动生成
Guranteed(优先级高)
同时设置CPU与内存的request和limits
CPU.limits=CPU.request
memory.limits=CPU.request
Burstable(优先级中)
至少一个容器设置了CPU或memory的request
BestEffort(优先级低)
没有任何一个容器被设置了request和limits
当服务器的资源不够用的时候
- 会优先杀掉 优先级低 的容器。
- 按照需求量,占用 比率高 的被杀掉。
HeapSter+InfluxDB+Grafana(适用于1.10之前的版本,已经不建议使用)
资源使用量数据采集工具
- cAdvisor:集成与kunelet,收集node上 pod级别的用量
- HeapSter: 收集汇总数据
- InfluxDB:持久化数据
- Grafana:展示数据
https://github.com/huruizhi/kubeasz/blob/master/docs/guide/heapster.md
资源指标API 与 自定义指标API
- 资源指标
- 自定义指标
新一代架构
核心指标流水线:kubelet metric-server 与 API Server 提供的api;监控CPU累计使用率,内存实时使用率,Pod的资源占用与node的磁盘占用率。
监控流水线:从系统手机各种指标数据提供给终端用户、存储系统与HPA,非核心指标不能被k8s所解析。
metric-server
资源指标
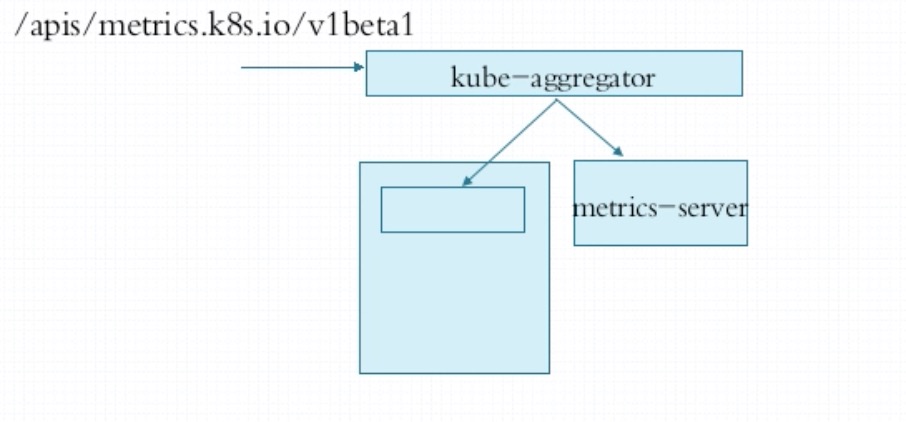
kube-aggregator 作为代理将核心指标的访问指向apiserver,将用户自定义的指标指向metric-server
prometheus + k8s-prometheus-adapter
自定义指标
https://github.com/kubernetes/kubernetes/tree/master/cluster/addons/prometheus
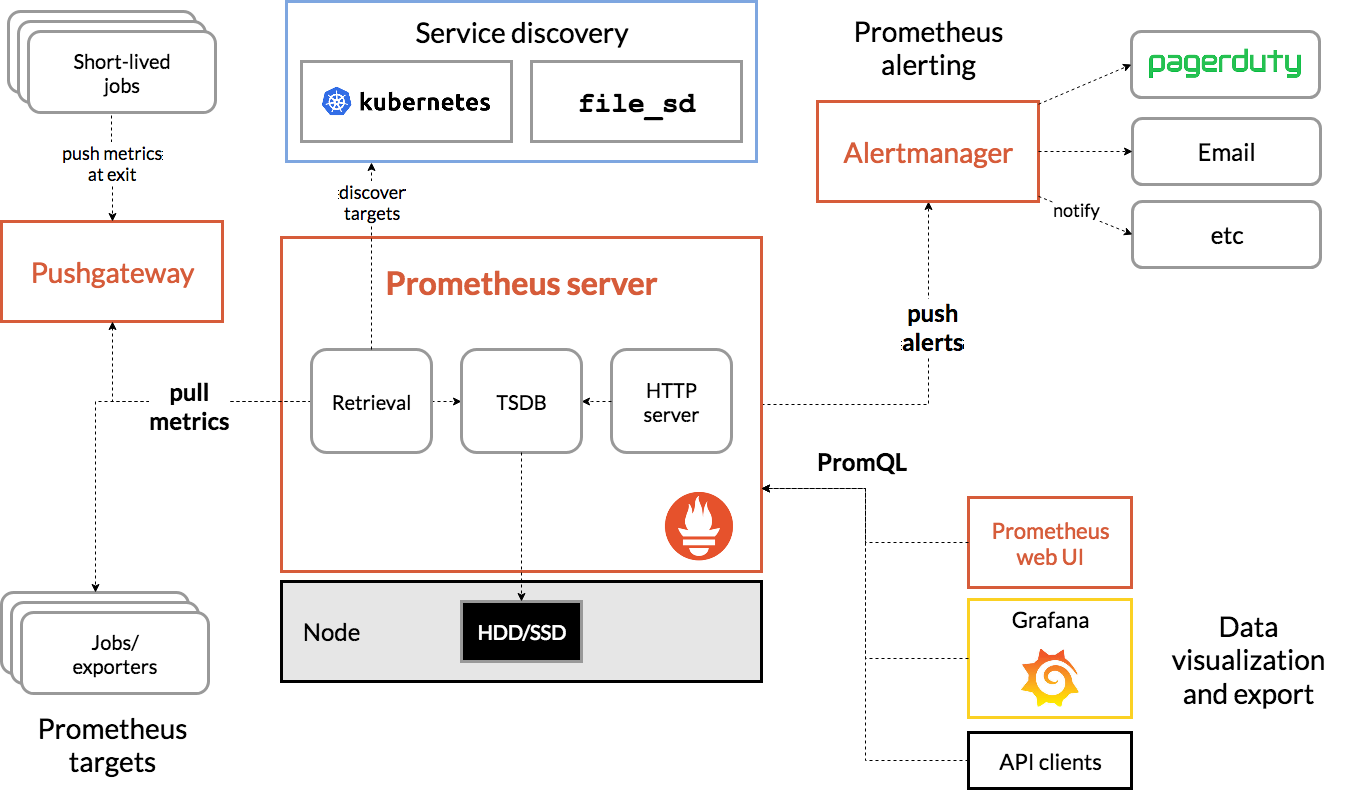
注意:推荐使用helm安装部署prometues
HPA 应用自动伸缩
kubectl autoscale (-f FILENAME | TYPE NAME | TYPE/NAME) [--min=MINPODS] --max=MAXPODS
[--cpu-percent=CPU] [options]
kubectl explain hpa.spec.scaleTargetRef