8.6 GIL锁**
Global interpreter Lock 全局解释器锁 实际就是一把解释器级的互斥锁
In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple
native threads from executing Python bytecodes at once. This lock is necessary mainly
because CPython’s memory management is not thread-safe. (However, since the GIL
exists, other features have grown to depend on the guarantees that it enforces.)
大意:在CPython解释器中,同一个进程下如果有多个线程同时启动,那么CPython一次只允许一个线程执行,这种规则由GIL完成
需要明确的事情是:GIL不是python的特性,而是 CPython解释器的特性
8.6.1 GIL的介绍
既然上文提到了GIL是一把互斥锁,所以它也是满足互斥锁的一些特性,是将并发运行变成串行,一次来保证在同一时间内公共数据只能被一个任务修改,从而保证数据的安全性。
一个py文件就是一个进程,这个进程下有一个主线程以及由主线程开启的子线程,那么这个进程执行的流程是:在内存中申请一块空间 --> 把py文件的内容加载到申请的内存中 --> 各个线程开始执行 --> 先经过CPython,这时需要经过GIL --> 经解释器编译转成机器语言 --> 交由CPU处理 --> 当线程遇到IO或者执行完毕时,CPU会切换执行其他任务,此时GIL锁自动release并给下一个线程加锁
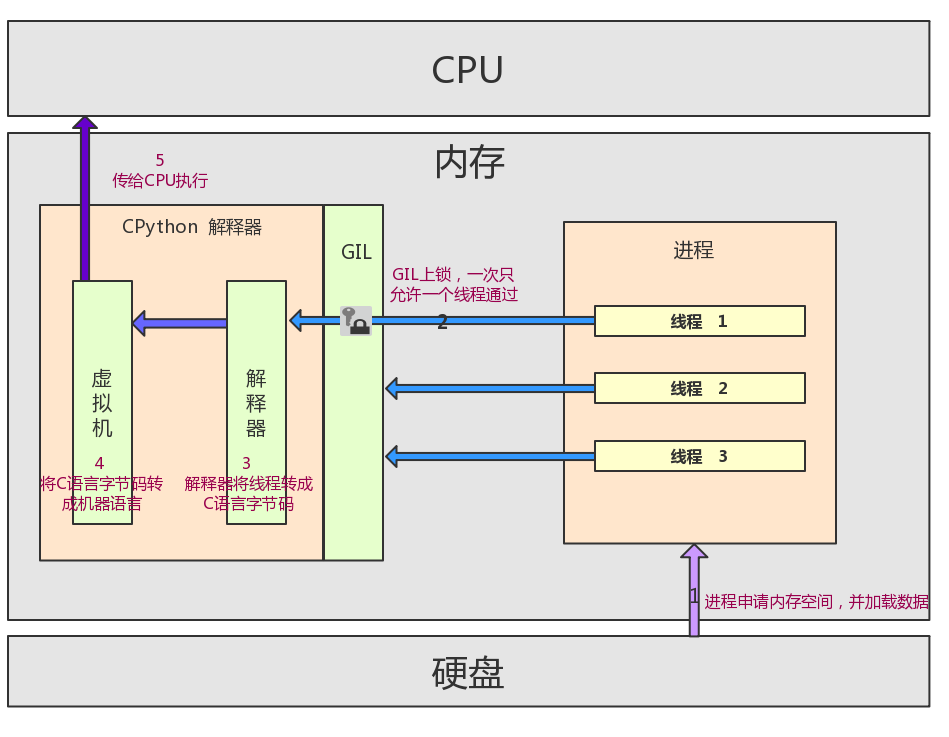
GIL的优点:保证了解释器的数据安全;减轻了开发人员的负担
GIL的缺点:单进程的多线程不能利用多核CPU(多进程的多线程是可以利用多个CPU的)
8.6.2 GIL与Lock
GIL保护的是解释器级的数据安全,Lock是需要手动添加的保护线程和进程数据安全
8.6.3 GIL与多线程
我们常常会有这样的疑问,既然python多线程不能发挥多核CPU的优势,那为啥还要用python呢?
对于这个问题,我们首先要明确的几个事情是:
- CPU是用来做计算的,不是用来处理IO的
- 多核意味着多个CPU并行执行运算,可以提升计算性能
- 每个CPU在遇到IO阻塞时,仍然需要等待或是切换去执行其他任务,所以多核对IO操作是没有太大帮助的
简而言之就是,对于计算来说多核可以大大提高效率,而对于IO来说,多核与单核的差距其实并不会非常大。更何况,python的多进程是可以利用多核的。
单核情况下
假设现在由四个任务需要处理,那么我们可以采用开启四个进程或者一个进程里启用四个线程两种方式。
既然是单核条件,那么这四个任务必然是并发进行的,并发就意味着串行执行,如果这四个任务都是计算密集型的任务,使用四个进程的话,其效果是不如后者的,因为进程的创建和开启速度都是低于线程的。如果这四个任务是IO密集型的任务,同样的道理,创建进程的开销大,且CPU在线程间切换的速度也是比在进程间切换的速度快。
【总结】单核情况下,线程的优势是大于进程的
多核的情况下
同样是上述的假设,计算密集型任务使用多个进程利用多核CPU速度是大于线程利用单核CPU的;而对于IO密集型任务,多核又不能解决IO问题,所以单核多线程的执行效率还是比多核多进程的效率高的
使用代码进行数据密集型任务验证
# 多进程模式下
from multiprocessing import Process
import time
def f():
s = 0
for i in range(100000000):
s += i
if __name__ == '__main__':
start_time = time.time()
l = []
for i in range (4):
p = Process(target=f)
l.append(p)
p.start()
for j in l:
j.join()
print(f"runing time {time.time()-start_time}")
#输出 runing time 8.005989789962769
#多进程模式下
from threading import Thread
import time
def f():
s = 0
for i in range(100000000):
s += i
if __name__ == '__main__':
start_time = time.time()
l = []
for i in range (4):
p = Thread(target=f)
l.append(p)
p.start()
for j in l:
j.join()
print(f"runing time {time.time()-start_time}")
# 输出runing time 21.031033754348755【结论】计算密集型多任务使用多进程效率高于单核多线程
使用代码进行IO集型任务验证
# 多进程
from multiprocessing import Process
import time
def f():
time.sleep(3)
if __name__ == '__main__':
start_time = time.time()
l = []
for i in range (150):
p = Process(target=f)
l.append(p)
p.start()
for j in l:
j.join()
print(f"runing time {time.time()-start_time}")
# 输出runing time 5.10007905960083
# 多线程
from threading import Thread
import time
def f():
time.sleep(3)
if __name__ == '__main__':
start_time = time.time()
l = []
for i in range (150):
p = Thread(target=f)
l.append(p)
p.start()
for j in l:
j.join()
print(f"runing time {time.time()-start_time}")
# 输出runing time 3.0351216793060303【结论】IO密集型多任务使用多线程效率高于多进程
其实并不是CPython不想利用多核,只是当时开发时只有单核,而现在要想改变的话,工作量就非常非常巨大了。
8.7 进程池和线程池
首先,我们是不能无线创建进程和线程的,为了保证运行的效率和资源的合理使用,要学会使用进程和线程池。通俗来说就是定义一个容器,在里面放置固定数量的进程或是线程,当有任务执行时,就这个容器中调度一个进程或是线程来处理任务,等到处理完毕,再将进程和线程放回容器里,等待其他任务调用。既然这里的线程和进程的数量是有限的,所以同一时间最多能处理的任务就是有限的,这样既节省了开支,合理化操作系统的调度。
使用线程池和进程池来管理并发编程,那么只要将相应的task函数将给线程池和进程池,剩下的就交给它们来处理就好了。
8.7.1 ProcessPollExecutor和threadPollExecutor
线程池和进程池的基类是concurrent.futures模块中的Executor,Executor提供了两个子类,其中threadPollExecutor用于创建线程池,ProcessPollExecutor用于创建进程池。Executor中提供了高度封装的异步调用接口。
Executor提供了一下常用的方法:
- submit(fn, *args,**kwargs) 将fn函提交给池子;*args是传给fn函数的参数;**kwargs表示以关键字参数的形式为fn的参数
- map(func, *iterables, timeout=None, chunksize=1) 类似于全局函数的map,只是该函数将会启动多个线程,以异步的方式立即对*iterables执行map处理,就是把for循环和submit结合在一起了
- shutdown(wait=True) 关闭池子,wait=True时等待池内所有任务执行完毕回收完资源后才继续;wait=False时立即返回,并不会等待池内的任务执行完毕;但不管wait参数为何值,整个程序都会等到所有任务执行完毕才会清空池子,所以submit和map必须在shutdown之前执行
程序将task函数submit之后,submit会返回一个Future对象,Future类主要用于获取线程或进程任务函数的返回值。Future中提供了一下方法:
- cancel() 取消Future代表的线程或者进程任务,如果任务正在执行,不可取消,返回False;否则任务取消,返回Ture
- cancelled() 返回Future代表的任务是否被成功取消
- running() 返回Future代表的任务是否增正在执行
- done() 返回Future代表的任务是否已经结束
- result(timmeout=None) 返回Future代表的任务的结果,如果任务没有完成,该方法将会阻塞当前线程,timeout指定阻塞多长时间
- exception() 返回Future代表的任务的异常,如果没有异常,则返回None
- add_done_callback(fn) 给Future代表的任务加一个'回调函数',当该任务成功之后,执行这个fn函数
8.7.2 实例
ProcessPollExecutor
import time,threading
from concurrent.futures import ProcessPoolExecutor
def f(n):
time.sleep(2)
print(f"打印{os.getpid()}",n)
return n*n
if __name__ == '__main__':
p_pool = ProcessPoolExecutor(max_workers=5) # 定义一个进程池对象,一般进程的设置数量不超过CPU个数
p_l = []
for i in range(5):
t = p_pool.submit(f,i)
p_l.append(t)
p_pool.shutdown(wait = True)
print('__main__')
for i in p_l:
print('===',i.result())threadPollExecutor
import time,threading
from concurrent.futures import ThreadPoolExecutor
def f(n):
time.sleep(2)
print(f"打印{threading.get_ident()}",n)
return n*n
if __name__ == '__main__':
t_pool = ThreadPoolExecutor(max_workers=5) # 定义一个线程池对象,一般进程的设置数量不超过CPU个数*5
t_l = []
for i in range(1,5):
t = t_pool.submit(f,i)
t_l.append(t)
t_pool.shutdown()
print('__main__')
for i in t_l:
print('===',i.result())map的使用
import time,threading
from concurrent.futures import ThreadPoolExecutor
def f(n):
time.sleep(1)
print(f"打印{threading.get_ident()}",n)
return n*n
if __name__ == '__main__':
t_pool = ThreadPoolExecutor(max_workers=5)
t_l = []
s = t_pool.map(f,range(1,5))
time.sleep(2)
print([i for i in s])回调函数
import time,threading
from concurrent.futures import ThreadPoolExecutor
def f(n):
time.sleep(1)
print(f"打印{threading.get_ident()}",n)
return n*n
def f1(x):
print(f"the result is {x.result()}")
if __name__ == '__main__':
t_pool = ThreadPoolExecutor(max_workers=5)
t_l = []
for i in range(1,5):
r = t_pool.submit(f,i).add_done_callback(f1) 异步与回调机制
异步:一口气发完所有任务,然后等待通知或者回调函数后再回来处理
requests模块简单介绍
requests这个模块的get方法请求页面,就和我们在浏览器上输入一个网址然后回车去请求别人的网站的效果是一样的。requests是个第三方模块,需要手动安装 pip3 install requests
简单爬虫示例
# 第一步: 爬取服务端的文件(IO阻塞).
# 第二步: 拿到文件,进行数据分析,(非IO,IO极少)
# 版本一
from concurrent.futures import ProcessPoolExecutor
import os,time,random
import requests
def get_text(url) :
response = requests.get(url)
print(f"{os.getpid()} is getting infomition")
time.sleep(random.randint(1,2))
if response.status_code == 200:
return response.text # 以文本的格式返回结果,当然也可以以其他方式
def parse(text):
print(f"{os.getpid()} 分析结果:{len(text)}") #用len来简单模拟一下数据分析过程
if __name__ == '__main__':
ls = [
'http://www.taobao.com',
'http://www.JD.com',
'http://www.baidu.com',
'http://www.JD.com',
'http://www.baidu.com',
'https://www.cnblogs.com/jin-xin/articles/11232151.html',
'https://www.cnblogs.com/jin-xin/articles/10078845.html',
'http://www.sina.com.cn',
'https://www.sohu.com',
'https://www.youku.com',
]
pool = ProcessPoolExecutor(4)
l = []
for url in ls:
obj = pool.submit(get_text,url) # 异步调用submit命名
l.append(obj)
pool.shutdown(wait=True)
for item in l:
parse(item.result()) #分析数据这种方法有两个问题:一是数据分析阶段,代码是串行的,效率低;二是在取到所有不同信息之后,放到一起进行的分析
我们更希望的是,获取到一个信息,我就分析一个(这里假设我的分析阶段是纯计算的),就像获取信息阶段一样能够异步完成,下面来了版本二
# 版本二
from concurrent.futures import ProcessPoolExecutor
import os,time,random
import requests
def get_text(url) :
response = requests.get(url)
print(f"{os.getpid()} is getting infomition")
time.sleep(random.randint(1,2))
if response.status_code == 200:
parse(response.text) # 获取信息后立马分析
def parse(text):
print(f"{os.getpid()} 分析结果:{len(text)}")
if __name__ == '__main__':
ls = [
'http://www.taobao.com',
'http://www.JD.com',
'http://www.baidu.com',
'http://www.JD.com',
'http://www.baidu.com',
'https://www.cnblogs.com/jin-xin/articles/11232151.html',
'https://www.cnblogs.com/jin-xin/articles/10078845.html',
'http://www.sina.com.cn',
'https://www.sohu.com',
'https://www.youku.com',
]
pool = ProcessPoolExecutor(4)
for url in ls:
obj = pool.submit(get_text,url)版本几乎接近完美,但是有一点很让人介意就是,数据分析和信息获取的耦合性有点大,这是就是回调函数该发挥作用的时候了
from concurrent.futures import ProcessPoolExecutor
import os,time,random
import requests
def get_text(url) :
response = requests.get(url)
print(f"{os.getpid()} is getting infomition")
time.sleep(random.randint(1,2))
if response.status_code == 200:
return response.text
def parse(obj):
print(f"{os.getpid()} 分析结果:{len(obj.result())}")
if __name__ == '__main__':
ls = [
'http://www.taobao.com',
'http://www.JD.com',
'http://www.baidu.com',
'http://www.JD.com',
'http://www.baidu.com',
'https://www.cnblogs.com/jin-xin/articles/11232151.html',
'https://www.cnblogs.com/jin-xin/articles/10078845.html',
'http://www.sina.com.cn',
'https://www.sohu.com',
'https://www.youku.com',
]
pool = ProcessPoolExecutor(4)
for url in ls:
obj = pool.submit(get_text,url)
obj.add_done_callback(parse)
pool.shutdown(wait=True)回调函数,降低了两者耦合性
【注意】我们这个情景下的回调的函数是计算密集型,如果回调的函数是IO密集的函数时,那就要考虑要不要用回调函数了,这个时候就需要牺牲开销,再增加一个线程池专门进行数据分析了
| 回调的函数 | 处理方式 |
|---|---|
| 计算密集型 | 使用异步+回调 |
| IO<<多个任务的IO | 使用异步+回调 |
| IO>>多个任务的IO | 使用第二种方式或者使用两个进程池 |
【强调】回调和异步时两个概念
8.7.3 multiprocess.Pool模块
是另一种进程池的,使用方法与上边的进程池类似
- apply(func [, args [, kwargs]]):在一个池工作进程中执行func(*args,**kwargs),然后返回结果
- .apply_async(func [, args [, kwargs]]):在一个池工作进程中执行func(*args,**kwargs),然后返回结果
- .close():关闭进程池,防止进一步操作。如果所有操作持续挂起,它们将在工作进程终止前完成
- .jion():等待所有工作进程退出。此方法只能在close()或teminate()之后调用
import os,time
from multiprocessing import Process,Pool
def f(n):
print(f"{os.getpid()}")
time.sleep(1)
return n*n
if __name__ == '__main__':
p = Pool(3) #进程池中从无到有创建三个进程,以后一直是这三个进程在执行任务
p_l = []
for i in range(1,10):
re = p.apply(f,args=(i,))
p_l.append(re)
print(p_l)它也是有回调函数的
from multiprocessing import Process,Pool
import os,time,random
import requests
def get_text(url) :
response = requests.get(url)
print(f"{os.getpid()} is getting infomition")
time.sleep(random.randint(1,2))
if response.status_code == 200:
return response.text
def parse(text):
print(f"{os.getpid()} 分析结果:{len(text)}")
if __name__ == '__main__':
ls = [
'http://www.taobao.com',
'http://www.JD.com',
'http://www.baidu.com',
'http://www.JD.com',
'http://www.baidu.com',
'https://www.cnblogs.com/jin-xin/articles/11232151.html',
'https://www.cnblogs.com/jin-xin/articles/10078845.html',
'http://www.sina.com.cn',
'https://www.sohu.com',
'https://www.youku.com',
]
pool = Pool(4)
for url in ls:
pool.apply_async(func=get_text,args=(url,),callback=parse)
pool.close()
pool.join() # pool.apply_async使用的化必须要跟join,而join的条件pool的状态CLOSE或者TERMINATE
# 所以它前边就需要加上close