>>> from urllib import urlretrieve >>> urlretrieve('http://table.finance.yahoo.com/table.csv?s=000001.sz',r'C:\视频\python高效实践技巧笔记\6数据编码与处理相关话题\pingan.csv',’pingan.csv’)
Urlretrieve模块第一个参数是url,第二个参数是要将打开的文件保存的文件。
对CSV文件读写使用CSV接口的reader()和writer()函数
因这个网址已经打不开了,所以在网上下载一个CSV文件直接操作
一、打开并读一个csv文件


>>> help(csv.reader) Help on built-in function reader in module _csv: reader(...) csv_reader = reader(iterable [, dialect='excel'] [optional keyword args]) for row in csv_reader: process(row) The "iterable" argument can be any object that returns a line of input for each iteration, such as a file object or a list. The optional "dialect" parameter is discussed below. The function also accepts optional keyword arguments which override settings provided by the dialect. The returned object is an iterator. Each iteration returns a row of the CSV file (which can span multiple input lines).
参数是一个打开文件的文件对象,返回的是一个迭代器。
>>> import csv >>> >>> rf = open(r"C:\视频\python高效实践技巧笔记\6数据编码与处理相关话题\bank-data.csv",'rb') #注意打开csv文件需要使用二进制打开方式 >>> reader = csv.reader(rf) >>> reader.next() #csv.reader()返回的是迭代器,查看需要使用next()方法 ['id', 'age', 'sex', 'region', 'income', 'married', 'children', 'car', 'save_act', 'current_act', 'mortgage', 'pep'] >>> reader.next() ['ID12101', '48', 'FEMALE', 'INNER_CITY', '17546.0', 'NO', '1', 'NO', 'NO', 'NO', 'NO', 'YES']

查看reader()返回迭代对象的方法
>>> help(reader) Help on reader object: class reader(__builtin__.object) | CSV reader | | Reader objects are responsible for reading and parsing tabular data | in CSV format. | | Methods defined here: | | __iter__(...) | x.__iter__() <==> iter(x) | | next(...) | x.next() -> the next value, or raise StopIteration | | ---------------------------------------------------------------------- | Data descriptors defined here: | | dialect | | line_num
二、打开并写一个文件
>>> writer = csv.writer(wf)
>>> help(csv.writer) Help on built-in function writer in module _csv: writer(...) csv_writer = csv.writer(fileobj [, dialect='excel'] [optional keyword args]) for row in sequence: csv_writer.writerow(row) [or] csv_writer = csv.writer(fileobj [, dialect='excel'] [optional keyword args]) csv_writer.writerows(rows) The "fileobj" argument can be any object that supports the file API.
同reader()一样,参数是一个打开文件的对象,返回值是一个迭代器,打开文件的方式 需要使用二进制方式
>>> wf = open(r'C:\视频\python高效实践技巧笔记\6数据编码与处理相关话题\bank-databak.csv','wb') >>> writer = csv.writer(wf) >>> writer.writerow(['id', 'age', 'sex', 'region', 'income', 'married', 'children', 'car', 'save_act', 'current_act', 'mortgage', 'pep']) >>> writer.writerow(reader.next()) >>> writer.writerow(reader.next()) >>> wf.flush() #和c语言的flush()作用相同,及时将文件缓冲区内容输出到文件上。

查看writer()返回的迭代器的方法主要是writerow()写行
>>> help(writer) Help on writer object: class writer(__builtin__.object) | CSV writer | | Writer objects are responsible for generating tabular data | in CSV format from sequence input. | | Methods defined here: | | writerow(...) | writerow(sequence) | | Construct and write a CSV record from a sequence of fields. Non-string | elements will be converted to string. | | writerows(...) | writerows(sequence of sequences) | | Construct and write a series of sequences to a csv file. Non-string | elements will be converted to string. | | ---------------------------------------------------------------------- | Data descriptors defined here: | | dialect
Bank-data.csv是一份收入情况,现编写脚本,将文件中年龄在30-40之间,收入大于10000的另存到一个bank-databak.csv文件中.现编写脚本如下:
# -*- coding: cp936 -*- import csv with open(r'C:\视频\python高效实践技巧笔记\6数据编码与处理相关话题\bank-data.csv','rb') as rf: reader = csv.reader(rf) with open(r'C:\视频\python高效实践技巧笔记\6数据编码与处理相关话题\bank-databak.csv','wb') as wf: writer = csv.writer(wf) header = reader.next() #将文件的头读出 writer.writerow(header) #将文件的头写入文件 for row in reader: #迭代执行判断,文件中第一个字段代表age第4个字段代表收入 #文件中读出的是字符,所以在比较时要将字符转成int或float. #python中判断数字区间可以用数学中的表达方式,与C语言不同. if (30< int(row[1])<40 and float(row[4])>10000.0): writer.writerow(row) #将合适的数据写入新的csv文件中 print("end")
结果:

Ps:
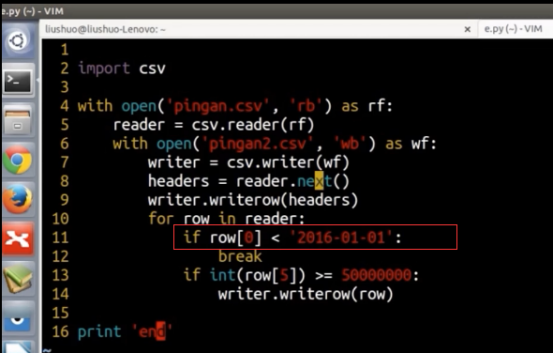
注意字符串日期的比较的大小比较也可以使用如下红框的方式,、