-
filesystem cache
-
数据预热
-
冷热分离
-
document 模型设计
-
分页性能优化
1、filesystem cache
往 es 里写的数据,实际上都写到磁盘文件里去了,**查询的时候**,操作系统会将磁盘文件里的数据自动缓存到 `filesystem cache` 里面去
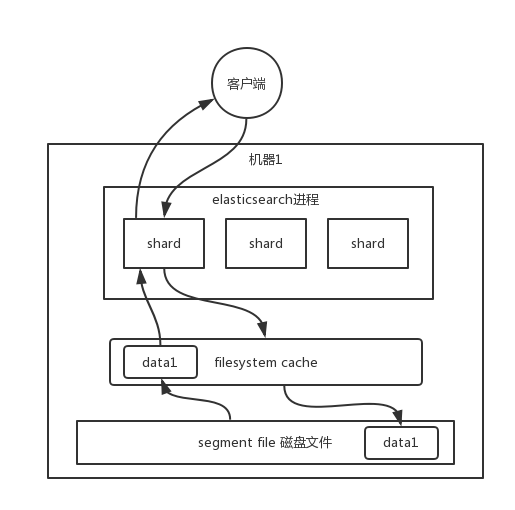
es 的搜索引擎严重依赖于底层的 `filesystem cache`,你如果给 `filesystem cache` 更多的内存,尽量让内存可以容纳所有的 `idx segment file ` 索引数据文件,那么你搜索的时候就基本都是走内存的,性能会非常高。
归根结底,要让 es 性能要好,最佳的情况下,就是你的机器的内存,至少可以容纳你的总数据量的一半。
比如说现在有一行数据。`id,name,age ....` 30 个字段。但是现在搜索,只需要根据 `id,name,age` 三个字段来搜索。仅仅写入 es 中要用来检索的**少数几个字段**就可以了,比如说就写入 es `id,name,age` 三个字段,然后你可以把其他的字段数据存在 mysql/hbase 里,一般是建议用 `es + hbase` 这么一个架构。
hbase 的特点是**适用于海量数据的在线存储**,就是对 hbase 可以写入海量数据,但是不要做复杂的搜索,做很简单的一些根据 id 或者范围进行查询的这么一个操作就可以了。从 es 中根据 name 和 age 去搜索,拿到的结果可能就 20 个 `doc id`,然后根据 `doc id` 到 hbase 里去查询每个 `doc id` 对应的**完整的数据**,给查出来,再返回给前端。
写入 es 的数据最好小于等于,或者是略微大于 es 的 filesystem cache 的内存容量。然后你从 es 检索可能就花费 20ms,然后再根据 es 返回的 id 去 hbase 里查询,查 20 条数据,可能也就耗费个 30ms
2、数据预热
假如说,哪怕是你就按照上述的方案去做了,es 集群中每个机器写入的数据量还是超过了 `filesystem cache` 一倍,比如说你写入一台机器 60G 数据,结果 `filesystem cache` 就 30G,还是有 30G 数据留在了磁盘上。
其实可以做**数据预热**。
可以将平时查看最多的一些商品,比如说 iphone 8,热数据提前后台搞个程序,每隔 1 分钟自己主动访问一次,刷到 `filesystem cache` 里去。
对于那些你觉得比较热的、经常会有人访问的数据,最好**做一个专门的缓存预热子系统**,就是对热数据每隔一段时间,就提前访问一下,让数据进入 `filesystem cache` 里面去。这样下次别人访问的时候,性能一定会好很多。
冷热分离