函数生成器、推导式及python内置函数
函数生成器
生成器的定义
在 Python 中,使用了 yield 的函数被称为生成器(generator)。
跟普通函数不同的是,生成器是一个返回迭代器的函数,只能用于迭代操作,更简单点理解生成器就是一个迭代器。
在调用生成器运行的过程中,每次遇到 yield 时函数会暂停并保存当前所有的运行信息,返回 yield 的值, 并在下一次执行 next() 方法时从当前位置继续运行。
调用一个生成器函数,返回的是一个迭代器对象。
生成器与迭代器的区别
生成器是程序开发者自己编写的一种特殊迭代器
迭代器为python内置的对象
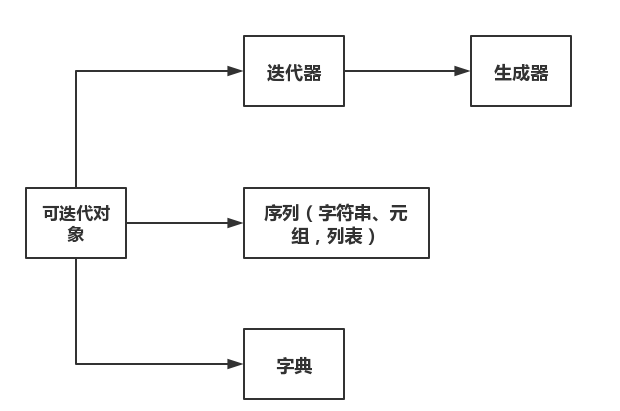
可迭代对象、迭代器及生成器三者关系:
生成器的构建方式
- 生成器函数构建
- 生成器推导式构建
- python内置函数和模块实现
生成器函数
def func():
print(111)
yield 222 #关键字,当函数中出现yield关键字时候,说明我们想要声明一个生成器
g = func() #生成器
print(next(g)) #与__next__()方法一样
# 结果:
<generator object func at 0x0000028A1D5BFF10> #生成器对象内存地址
111
222生成器函数中yield和next是一一对应的,当next超出yield个数时,程序报错Stopiteration
yield和return区别:
return一般在函数中只设置一个,他的作用是终止函数,并且给函数的执行者返回值。
yield在生成器函数中可设置多个,他并不会终止函数,next会获取对应yield生成的元素。
lst = []
def func():
for i in range(10000): #列表方式存储,非常占用内存
lst.append(i)
print(i)
def func():
for i in range(10000):
yield i # yield起阻塞作用,用1取1
g = func()
for j in range(50):
print(next(g))
# 结果为0-49def func():
lst1 = ["牛羊配","老奶奶花生米","卫龙","虾扯蛋","米老头","老干妈"]
lst2 = ["小浣熊","老干爹","亲嘴烧","麻辣烫","黄焖鸡","井盖"]
yield from lst1
yield from lst2 # yield from -- 将可迭代对象元素逐个返回
g = func()
print(next(g))
print(next(g))
print(next(g))
# 结果:
牛羊配
老奶奶花生米
卫龙陷阱:
def func():
yield 1
for i in range(10):
yield i
print(func().__next__())
print(func().__next__()) #重复制造杯子(生成器)
# 结果:
1
1小结:
在函数中将return改写成yield就是一个生成器
yield 会记录执行位置
return 和 yield 都是返回,return 可以写多个,但是只执行一次,yield可以写多个,还可以返回多次
一个__next__() 对应 一个yield
生成器可以使用for循环获取值
yield from -- 将可迭代对象元素逐个返回
在函数的内部 yield 能将for循环和while循环进行临时暂停
推导式
列表推导式
lst = []
for i in range(10):
lst.append(i)
print(lst)
# 结果:
[0,1,2,3,4,5,6,7,8,9]
print([i for i in range(10)])
# 结果:
[0,1,2,3,4,5,6,7,8,9]循环模式
[变量(加工后的变量)for 循环]print([i for i in range(0,10,2)]) #10以内所有偶数筛选模式
[变量(加工后的变量)for 循环 if 条件]print([i for i in range(10) if i%2==1]) #10以内所有奇数print([f"python{i}期" for i in range(1,25) if i%2==0]) #python24期内所有偶数期生成器表达式
循环模式
(变量(加工后的变量)for 循环)g = (i for i in range(10))
print(next(g))
print(next(g))
# 结果:
0
1筛选模式
(变量(加工后的变量)for 循环 if 条件)g = (i for i in range(50) if i%5 == 0)
print(next(g))
print(next(g))
# 结果
0
5其他推导式
# 字典推导式:
print({i:i+1 for i in range(10)})
print({i:i+1 for i in range(10) if i % 2 == 0})
# {键:值 for循环 加工条件}# 集合推导式:
print({i for i in range(10)})
print({i for i in range(10) if i%2 == 0})
# {变量(加工后的变量) for循环 加工条件}python内置函数用法
eval:执行字符串类型的代码,并返回最终结果。
eval('2 + 2') # 4
n=81
eval("n + 4") # 85
eval('print(666)') # 666exec:执行字符串类型的代码。
s = '''
for i in [1,2,3]:
print(i)
'''
exec(s)以上两个内置函数很强大 工作中禁止使用
hash:获取一个对象(可哈希对象:int,str,Bool,tuple)的哈希值。
print(hash(12322))
print(hash('123'))
print(hash('arg'))
print(hash('alex'))
print(hash(True))
print(hash(False))
print(hash((1,2,3)))
'''
-2996001552409009098
-4637515981888139739
1
2528502973977326415
'''help:函数用于查看函数或模块用途的详细说明。
print(help(list))
print(help(str.split))callable:函数用于检查一个对象是否是可调用的。如果返回True,仍然可能调用失败;但如果返回False,调用对象ojbect绝对不会成功。
name = 'alex'
def func():
pass
print(callable(name)) # False
print(callable(func)) # Trueint:函数用于将一个字符串或数字转换为整型。
print(int()) # 0
print(int('12')) # 12
print(int(3.6)) # 3
print(int('0100',base=2)) # 将2进制的 0100 转化成十进制。结果为 4float:函数用于将整数和字符串转换成浮点数。
complex:函数用于创建一个值为 real + imag * j 的复数或者转化一个字符串或数为复数。如果第一个参数为字符串,则不需要指定第二个参数。。
print(float(3)) # 3.0
print(complex(1,2)) # (1+2j)bin:将十进制转换成二进制并返回。
oct:将十进制转化成八进制字符串并返回。
hex:将十进制转化成十六进制字符串并返回。
print(bin(10),type(bin(10))) # 0b1010 <class 'str'>
print(oct(10),type(oct(10))) # 0o12 <class 'str'>
print(hex(10),type(hex(10))) # 0xa <class 'str'>divmod:计算除数与被除数的结果,返回一个包含商和余数的元组(a // b, a % b)。
round:保留浮点数的小数位数,默认保留整数。
pow:求xy次幂。(三个参数为xy的结果对z取余)
print(divmod(7,2)) # (3, 1)
print(round(7/3,2)) # 2.33
print(round(7/3)) # 2
print(round(3.32567,3)) # 3.326
print(pow(2,3)) # 两个参数为2**3次幂
print(pow(2,3,3)) # 三个参数为2**3次幂,对3取余。bytes:用于不同编码之间的转化。
# s = '你好'
bs = s.encode('utf-8')
# print(bs)
s1 = bs.decode('utf-8')
# print(s1)
bs = bytes(s,encoding='utf-8')
# print(bs)
b = '你好'.encode('gbk')
# b1 = b.decode('gbk')
print(b1.encode('utf-8'))ord:输入字符找当前字符编码的位置
chr:输入当前编码的位置数字找出其对应的字符
# ord 输入字符找该字符编码的位置
print(ord('a'))
print(ord('中'))
# chr 输入位置数字找出其对应的字符
print(chr(97))
print(chr(20013))repr:返回一个对象的string形式(原形毕露)。
# %r 原封不动的写出来
name = 'taibai'
print('我叫%r'%name)
# repr 原形毕露
print(repr('{"name":"alex"}'))
print('{"name":"alex"}')all:可迭代对象中,全都是True才是True
any:可迭代对象中,有一个True 就是True
# all 可迭代对象中,全都是True才是True
# any 可迭代对象中,有一个True 就是True
print(all([1,2,True,0]))
print(any([1,'',0]))