一、collection模块
collections是python内建的一个集合模块。collections模块还提供了几个额外的数据类型:counter、deque、defaultdict、namedtuple、orderredDict
namedtuple可以很方便的定义一种数据类型,他具备tuple的不可变性,也可以根据属性来引用,非常方便。
from collections import namedtuple
point = namedtuple('坐标’,['x','y'.'z']) #第二个参数既可以传可迭代对象也可以传字符
point = namedtuple('坐标‘,x,y,z) # 串,但字符串跟字符串之间以空格隔开
p = point(1,2,5) #注意元素个数必须跟namedtuple第二个参数里面的值数量一致
print(p)
print(p.x)
print(p.y)
print(p.z)
结果:
deque:双端队列
list的缺点:list在插入元素(insert)的时候是非常慢的,因为你插入一个元素,那么此元素后面的所有元素索引都得改变,当数据量很大的时候,那么速度就很慢了。
双端队列可以弥补list的这个缺点。双端队列除了实现list的append和pop外,还支持appendleft()和popleft(),这样就可以非常高效的往头部添加或删除元素。
from collections import deque dq = deque([1,2,3]) dq.append(4) dq.append(5) dq.appendleft(6) print(dq) # deque([6, 1, 2, 3, 4, 5]) print(dq.pop()) # 5 print(dq.popleft()) # 6
双端队列原理图:
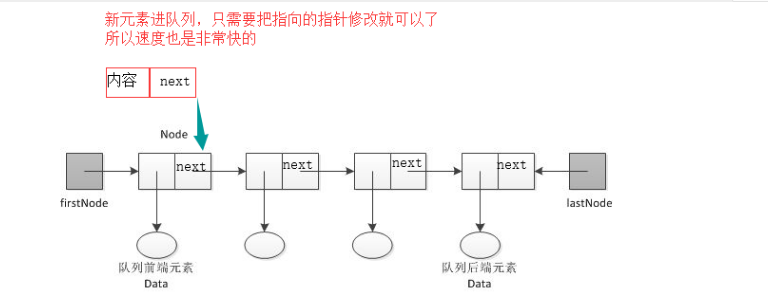
defaultdict:为字典设置默认值
from collections import defaultdict dic = defaultdict(list) # 为字典设置默认值为空列表(defaultdict里面的参数必须是可调用的) dic = defaultdict(1) # 报错,因为数字 1 不可调用 print(dic['a']) # [] dic['b'].append(2) print(dic['b']) # [2]
二、时间模块
时间相关操作,时间有三种表现方式:
时间戳 1970年1月1日之后的秒,即:time.time()
格式化的字符串 2014-11-11 11:11 即:time.strftime('%Y-%m-%d')
结构化时间 元组包含了:年、日、星期等 time.struct_time 即:time.localtime()
import time
print(time.time()) #返回当前系统时间戳(1970年1月1日0时0分0秒开始)
print(time.ctime()) #返回当前系统时间
print(time.strftime("%Y-%m-%d %H:%M:%S",time.gmtime()))#将struct_time格式转化成指定的字符串格式
print(time.strptime("2016-05-17","%Y-%m-%d")) # 将字符串格式转换成struct_time格式
import datatime
current_time = datetime.datetime.now()
print(datatime.data.today()) #输出格式为2019-07-18
print(currut_time) #输出为2019-07-18 21:25:52.646318
print(current_time.timetuple()) #返回struct_time格式
print(current_time.replace(2008,8,8))#2008-08-08 21:25:52.646318
str_to_date = datetime.datetime.strptime("28/7/08 11:20","%d/%m/%y %H:%M") #将字符串转换成日期格式
new_date = datetime.datetime.now() + datetime.timedelta(days=10) #比现在加10天
new_date = datetime.datetime.now() + datetime.timedelta(days=-10) #比现在减10天
new_date = datetime.datetime.now() + datetime.timedelta(hours=-10) #比现在减10小时
new_date = datetime.datetime.now() + datetime.timedelta(seconds=120) #比现在+120s
print(new_date)
三、random模块
随机数:
import random
print(random.random()) #用于生成一个0到1的随机符点数: 0 <= n < 1.0
print(random.randint(1,2)) #用于生成一个指定范围内的整数
print(random.randrange(1,10)) #从指定范围内,按指定基数递增的集合中获取一个随机数
print(random.uniform(1,10)) #用于生成一个指定范围内的随机符点数
print(random.choice('nick')) #从序列中获取一个随机元素
li = ['nick','jenny','car',]
random.shuffle(li) #用于将一个列表中的元素打乱
print(li)
li_new = random.sample(li,2) #从指定序列中随机获取指定长度的片断(从li中随机获取2个元素,作为一个片断返回)
print(li_new)
生成随机验证码:
def get_code(n):
code = ''
for i in range(n):
# 先生成随机的大写字母 小写字母 数字
upper_str = chr(random.randint(65,90))
lower_str = chr(random.randint(97,122))
random_int = str(random.randint(0,9))
# 从上面三个中随机选择一个作为随机验证码的某一位
code += random.choice([upper_str,lower_str,random_int])
return code
res = get_code(4)
print(res)
四、os模块
os模块用于提供系统级别的操作
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.curdir 返回当前目录: ('.')
os.pardir 获取当前目录的父目录字符串名:('..')
os.makedirs('dir1/dir2') 可生成多层递归目录
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() 删除一个文件
os.rename("oldname","new") 重命名文件/目录
os.stat('path/filename') 获取文件/目录信息
os.sep 操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
os.linesep 当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"
os.pathsep 用于分割文件路径的字符串
os.name 字符串指示当前使用平台。win->'nt'; Linux->'posix'
os.system("bash command") 运行shell命令,直接显示
os.environ 获取系统环境变量
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
import os
BASE_DIR = os.path.dirname(__file__)
MOVIE_DIR = os.path.join(BASE_DIR,'老师们的作品')
movie_list = os.listdir(MOVIE_DIR)
while True:
for i,j in enumerate(movie_list,1):
print(i,j)
choice = input('你想看谁的啊(今日热搜:tank老师)>>>:').strip()
if choice.isdigit(): # 判断用户输入的是否是纯数字
choice = int(choice) # 传成int类型
if choice in range(1,len(movie_list)+1): # 判断是否在列表元素个数范围内
# 获取用户想要看的文件名
target_file = movie_list[choice-1]
# 拼接文件绝对路径
target_path = os.path.join(MOVIE_DIR,target_file)
with open(target_path,'r',encoding='utf-8') as f:
print(f.read())
五、sys模块
sys.argv 命令行参数List,第一个元素是程序本身路径 sys.exit(n) 退出程序,正常退出时exit(0) sys.version 获取Python解释程序的版本信息 sys.maxint 最大的Int值 sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 sys.platform 返回操作系统平台名称 sys.stdin 输入相关 sys.stdout 输出相关 sys.stderror 错误相关
手写进度条
# 手写进度条
import sys,time
for ii in range(101):
sys.stdout.write('\r') #每一次清空原行。
sys.stdout.write("%s%% |%s|"%(int(int(ii)/100*100),int(int(ii)/100*100) * '#')) #一共次数除当前次数算进度
sys.stdout.flush() #强制刷新到屏幕
time.sleep(0.05)
六、序列化模块
json,用于字符串和python数据类型间进行转换
pickle,用于python特有的类型和python的数据类型间进行转换
Json模块提供了四个功能:dumps、dump、loads、load
pickle模块提供了四个功能:dumps、dump、load、loads
dump()函数接受一个文件句柄和一个数据对象作为参数,把数据对象以特定的格式保存,到给定的文件中。当我们使用load()函数从文件中取出已保存的对象时,pickle知道如何恢复这些对象到他们本来的格式。
dumps()函数执行和dump() 函数相同的序列化。取代接受流对象并将序列化后的数据保存到磁盘文件,这个函数简单的返回序列化的数据。
loads()函数执行和load() 函数一样的反序列化。取代接受一个流对象并去文件读取序列化后的数据,它接受包含序列化后的数据的str对象, 直接返回的对象。
d = {"name":"jason"}
print(d) #{'name': 'jason'}
res = json.dumps(d) # json格式的字符串 必须是双引号 >>>: '{"name": "jason"}'
print(res,type(res)) #{"name": "jason"} <class 'str'>
res1 = json.loads(res)
print(res1,type(res1) #{'name': 'jason'} <class 'dict'>