一、使用cookie信息获取数据
复制已登录的cookie,使用这个cookie构建headers,请求url时携带headers(优点:简单粗暴 缺点:具有时效性,超出时间需重新获取cookie)
二、硬登录(模拟登录获取数据)
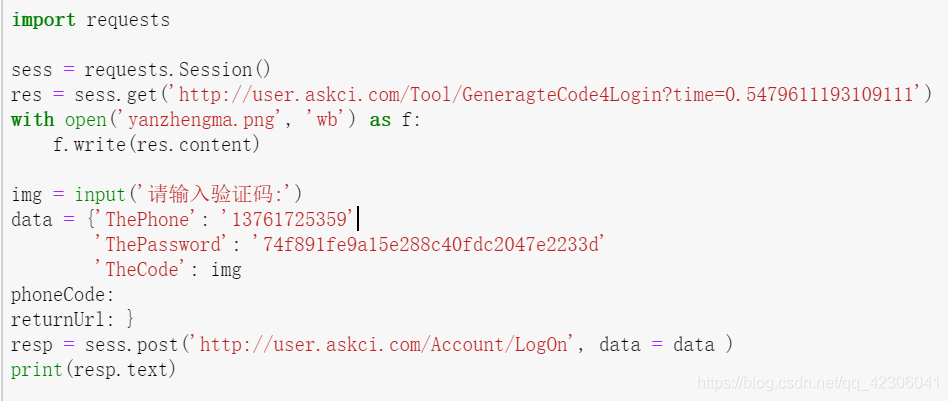
1、使用requests (优点:速度快 缺点:麻烦,要分析各个参数,对于加密或随机的参数较难实现)一般来说,分以下几步:
1)使用Session进行会话保持 sess = requests.Session(), 每次发送请求时都是用sess
2)获取验证码的图片,并下载到本地
3)识别验证码,给出结果
4)构造参数,携带参数用post请求访问登录的url
5) 访问要访问的url
注:有时可能会有一些隐藏的input框里面有参数
eg:

爬取github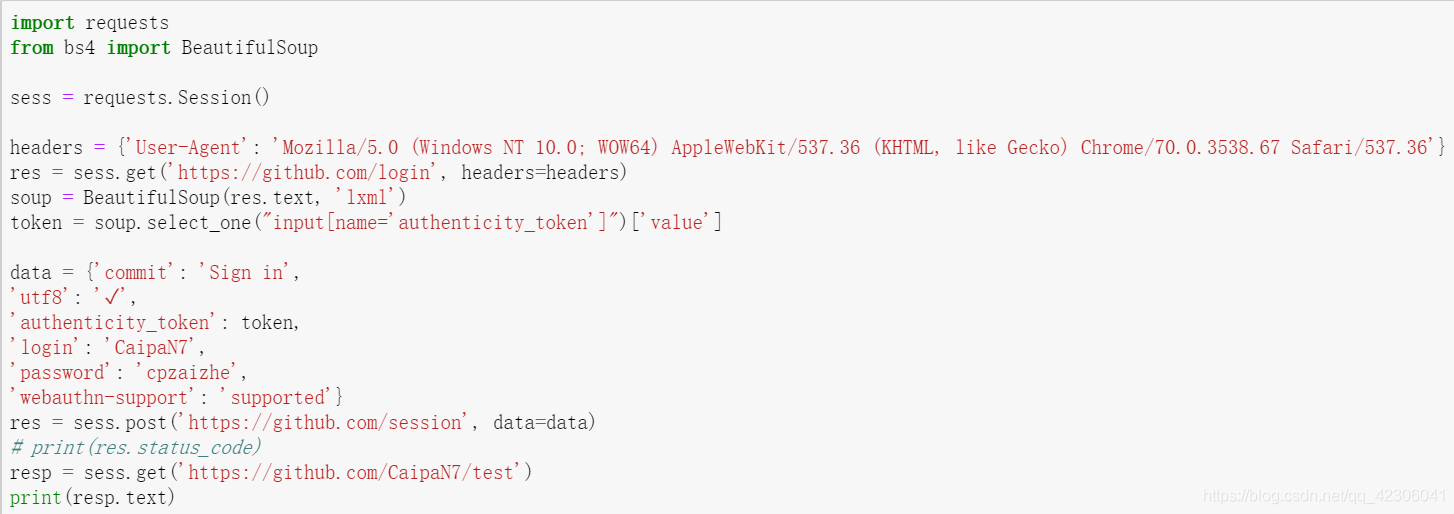
2、使用selenium模拟登录 (优点:简单方便 ,完全模拟用户登录网页的操作 缺点:速度慢,对于大规模爬取效率低)
eg: python 模拟登录github

**Python 爬虫解决登录的问题**
猜你喜欢
转载自blog.csdn.net/qq_42306041/article/details/91906492
今日推荐
周排行