A,2015-01-08,5
A,2015-01-11,15
B,2015-01-12,5
A,2015-01-12,8
B,2015-01-13,25
A,2015-01-13,5
C,2015-01-09,10
C,2015-01-11,20
A,2015-02-10,4
A,2015-02-11,6
C,2015-01-12,30
C,2015-02-13,10
B,2015-02-10,10
B,2015-02-11,5
A,2015-03-20,14
A,2015-03-21,6
B,2015-03-11,20
B,2015-03-12,25
C,2015-03-10,10
C,2015-03-11,20
结果如图

首先创建表和导入数据
create table
t_access_times(username string,month string,counts int)
row format delimited fields terminated by ',';
load data local inpath '/root/access_times.txt' into table t_access_times;
然后,我们可以先得到如下数据
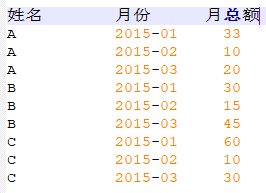
代码如下:
select
username,tmp.mo, sum(counts) sums
from
(
select username,
concat(split(month,'-')[0] ,'-', split(month,'-')[1]) mo,
counts
from t_access_times
) tmp
group by username,tmp.mo;
然后使用join连接两张表(两张表都是上面的表),根据a表用户名和月份分类,这样会有如下结果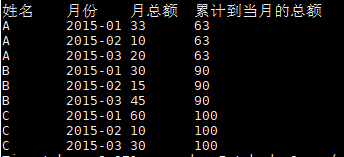
这显然是不对的,b表是用来求累计的,而这儿直接把用户所有的销售额都加上,所以,这里加一个判断,判断b表的月份要小于等于a表的月份,这样,b表求和就只会是求之前的了,最后加上排序,以防数据错乱。
select
a.username as `姓名`,
a.mo as `月份`,
--分组后,这里的数据不能调用,因为一组中有多条数据,但是这里多条数据是重复的,所以,用max,或着min都一样
max(a.sums) as `月总额`,
sum(b.sums) as `累计到当月的总额`
from
(
select
username,
tmp.mo,
sum(counts) sums
from
(
select
username,
concat(split(month,'-')[0] ,'-', split(month,'-')[1]) mo,
counts
from
t_access_times
) tmp
group by
username,
tmp.mo
)a
join
(
select
username,
tmp.mo,
sum(counts) sums
from
(
select
username,
concat(split(month,'-')[0] ,'-', split(month,'-')[1]) mo,
counts
from
t_access_times
) tmp
group by
username,
tmp.mo
)b
on a.username=b.username
where b.mo<=a.mo
group by a.username,a.mo
order by a.username,a.mo;
结果如下图: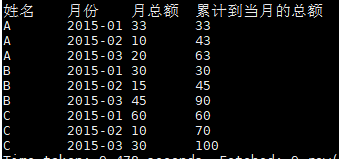
转载于:https://www.cnblogs.com/drl-blogs/p/11086870.html