1. 1 倒排索引
将数据加入到索引库(你可以理解成另外一个数据库)时,会先提取数据中的词汇(分词),将词汇加入到文档域,文档域中记录了词汇以及词汇在哪条数据记录中出现过的数据下标。用户在搜索数据时,先将用户搜索的数据进行词汇提取,然后把对应词汇拿到索引域中进行匹配查找,查找后会找到对应的下标ID,再根据对应下标ID到文档域中找真实数据.
1.2 应用场景 :
1、 单机软件的搜索(word中的搜索)
2、 站内搜索 (baidu贴吧、论坛、 京东、 taobao)
3、 垂直领域的搜索 (818工作网)
4、 专业搜索引擎公司 (google、baidu)
2.1 什么是Lucene
Lucene是apache软件基金会 Jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎。
- Lucene是一套用于全文检索和搜寻的开源程式库,由Apache软件基金会支持和提供。 Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻, 在Java开发环境里Lucene是一个成熟的免费开放源代码工具。
- Lucene并不是现成的搜索引擎产品,但可以用来制作搜索引擎产品。
2.2 Lucene与搜索引擎的区别
全文检索系统是按照全文检索理论建立起来的用于提供全文检索服务的软件系统,包括建立索引、处理查询返回结果集、增加索引、优化索引结构等功能。例如:百度搜索、eclipse帮助搜索、淘宝网商品搜索等。
搜索引擎是全文检索技术最主要的一个应用,例如百度。搜索引擎起源于传统的信息全文检索理论,即计算机程序通过扫描每一篇文章中的每一个词,建立以词为单位的倒排文件,检索程序根据检索词在每一篇文章中出现的频率和每一个检索词在一篇文章中出现的概率,对包含这些检索词的文章进行排序,最后输出排序的结果。全文检索技术是搜索引擎的核心支撑技术。
Lucene和搜索引擎不同,Lucene是一套用java或其它语言写的全文检索的工具包,为应用程序提供了很多个api接口去调用,可以简单理解为是一套实现全文检索的类库,搜索引擎是一个全文检索系统,它是一个单独运行的软件系统。
3.1 Lucene入门
实现这么一个案例,通过Java代码调用Lucene API实现对索引库的增删改查,索引库数据来源于数据库,所以增加操作需要先从数据库将数据查询出来,再调用Lucene API将数据加入到索引库中。

3.2 Lucene实现全文检索思路
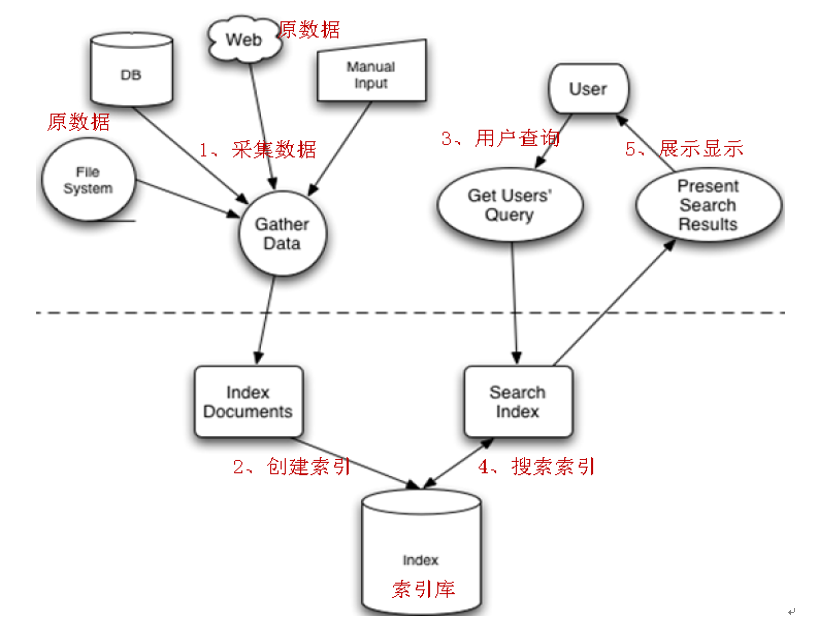
全文检索的流程分为两大部分:索引流程、搜索流程。
- 索引流程:即采集数据à构建文档对象à分析文档(分词)à创建索引。
- 搜索流程:即用户通过搜索界面输入à创建查询à执行搜索,搜索器从索引库搜à渲染搜索结果。
4.1 常用api介绍及分词
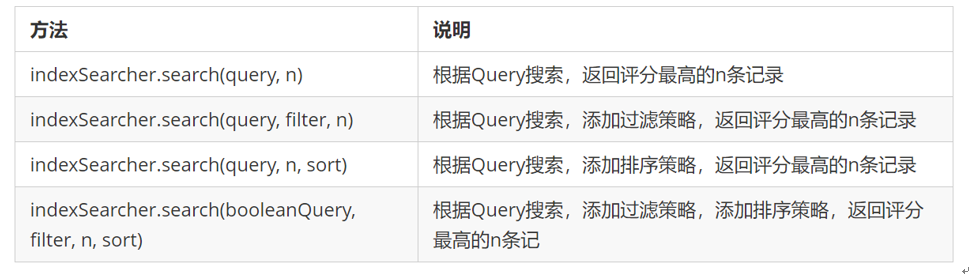
IndexSearcher搜索方法如下:
4.2
- 分词:采集到的数据会存储到document对象的Field域中,分词就是将Document中Field的value值切分成一个一个的词。
- 过滤:包括去除标点符号过滤、去除停用词过滤(的、是、a、an、the等)、大写转小写、词的形还原(复数形式转成单数形参、过去式转成现在式。。。)等。
5.1 Field属性
Field是文档中的域,包括Field名和Field值两部分,一个文档可以包括多个Field,Document只是Field的一个承载体,Field值即为要索引的内容,也是要搜索的内容。
Field中三个非常重要的属性:
l 是否分词(tokenized)
是,将field的内容分成一个一个单词。分词的目的:分词目的为了索引
例如:商品的名称。
否,不分词,将内容作为一个整体存储。
例如:商品ID 身份证号,图片路径
l 是否索引(indexed)
是,将field的值建立索引,索引的目的:索引的目的为了搜索。
例如:商品的名称
否,不建立索引
例如:图片路径、文件路径等
l 是否存储(stored),存不存取决于查询结果展示不展示
是,存储field的值。存储的目的:(为了展示在页面)
例如:商品名称,图片路径
否,不存储field的值。
例如:商品介绍。如果需要展示,根据ID从数据库查询展示在详情页面。
5.2 Field常用类型
下边列出了开发中常用 的Filed类型,注意Field的属性,根据需求选择:
| Field类 |
数据类型 |
Analyzed 是否分词 |
Indexed 是否索引 |
Stored 是否存储 |
说明 |
| StringField(FieldName, FieldValue,Store.YES)) |
字符串 |
N |
Y |
Y或N |
这个Field用来构建一个字符串Field,但是不会进行分词,会将整个串存储在索引中,比如(订单号,身份证号等) 是否存储在文档中用Store.YES或Store.NO决定 |
| LongField(FieldName, FieldValue,Store.YES) FloatField(FieldName, FieldValue,Store.YES) |
Long类型Float类型 等等数字类型 |
Y |
Y |
Y或N |
这个Field用来构建一个Long数字型Field,进行分词和索引,比如(价格) 是否存储在文档中用Store.YES或Store.NO决定 |
| StoredField(FieldName, FieldValue) |
重载方法,支持多种类型 |
N |
N |
Y |
这个Field用来构建不同类型Field(图片路径) 不分词,不索引,但要Field存储在文档中 |
| TextField(FieldName, FieldValue, Store.NO) 或 TextField(FieldName, reader) |
字符串 或 流 |
Y |
Y |
Y或N |
如果是一个Reader, lucene猜测内容比较多,会采用Unstored的策略. |
