实验原理
在我们开始建模之前,先讨论一下什么是 IPO(或首次公开募股),以及关于这个市场,研究的结果能告诉我们些什么。之后,我们将讨论一些可以应用的策略。
首次公开募股是一家私人公司成为上市公司的过程。公开发行为公司募集资金,并让公众通过购买其股票,获得投资该公司的机会。
虽然具体实施有些不同,但在典型的发行过程中,一家公司会列出一家或多家承销其发行的投资银行。这意味着那些银行向公司保证,在发行当天他们将购买所有以 IPO 价格提供的股份。当然,承销的银行不打算自己保留全部的股份。在发行公司的帮助下,他们去做所谓的路演,吸引机构客户的兴趣。这些客户可以预订股份,表示他们有意在 IPO 当天购买股票。这是一个非约束性合同,因为发行的价格直到 IPO 的当天才最终确定。然后,承销商将根据客户们所表达的感兴趣程度,设定发行的价格。
从我们的角度来看,非常有趣的地方在于:研究表明 IPO 一直被系统性地低估。有许多理论解释为什么会发生这种情况,以及为什么低估的范围会随着时间而变化,不过可以肯定的是,研究已经显示出每年有 “ 数十亿美元留在桌子上 ” 。
在IPO中,“ 留在桌子上的钱 ” 是指股票的发行价和第一天收盘价之间的差价。
在我们继续之前,还应该谈一谈发行价和开盘价之间的区别。虽然偶然的情况下你可以通过经纪人的交易,以发行价获得 IPO ,但作为一个普通的公众,你基本上不得不以开盘价( 通常更高 )来购买 IPO 。我们将在这个假设下构建模型。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from patsy import dmatrix
from sklearn.ensemble import RandomForestClassifier
from sklearn import linear_model
ipos=pd.read_csv('ipo_data_0.csv', encoding='latin-1')
ipos.head()
这里我们可以看到很多ipo的数据:发行日期,发行者,发行价格等等
实验步骤
首先对数据的格式进行正确化,去掉美元和百分号符号。
ipos=ipos.applymap(lambda x: x if not '$' in str(x) else x.replace('$', ''))
ipos=ipos.applymap(lambda x: x if not '%' in str(x) else x.replace('%', ''))
ipos.head()查看生成的输出
ipos.info()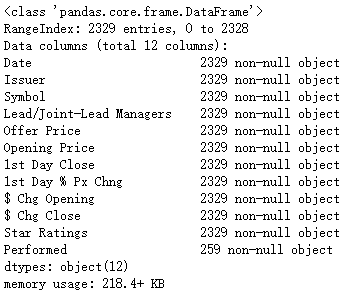
数据中有一些N/C的值,首先将其替换,之后可以更改数据类型
ipos.replace('N/C',0, inplace=True)
ipos['Date'] = pd.to_datetime(ipos['Date'])
ipos['Offer Price'] = ipos['Offer Price'].astype('float')
ipos['Opening Price'] = ipos['Opening Price'].astype('float')
ipos['1st Day Close'] = ipos['1st Day Close'].astype('float')
ipos['1st Day % Px Chng'] = ipos['1st Day % Px Chng'].astype('float')
ipos['$ Chg Close'] = ipos['$ Chg Close'].astype('float')
ipos['$ Chg Opening'] = ipos['$ Chg Opening'].astype('float')
ipos['Star Ratings'] = ipos['Star Ratings'].astype('int')<class 'pandas.core.frame.DataFrame'> RangeIndex: 2329 entries, 0 to 2328 Data columns (total 12 columns): Date 2329 non-null datetime64[ns] Issuer 2329 non-null object Symbol 2329 non-null object Lead/Joint-Lead Managers 2329 non-null object Offer Price 2329 non-null float64 Opening Price 2329 non-null float64 1st Day Close 2329 non-null float64 1st Day % Px Chng 2329 non-null float64 $ Chg Opening 2329 non-null float64 $ Chg Close 2329 non-null float64 Star Ratings 2329 non-null int64 Performed 259 non-null object dtypes: datetime64[ns](1), float64(6), int64(1), object(4) memory usage: 218.4+ KB
从第一天的平均收益比开始计算
ipos.groupby(ipos['Date'].dt.year)['1st Day % Px Chng'].mean().plot(kind= 'bar', figsize=(15,10), color='b', title='1st Day Mean IPO Percentage Change')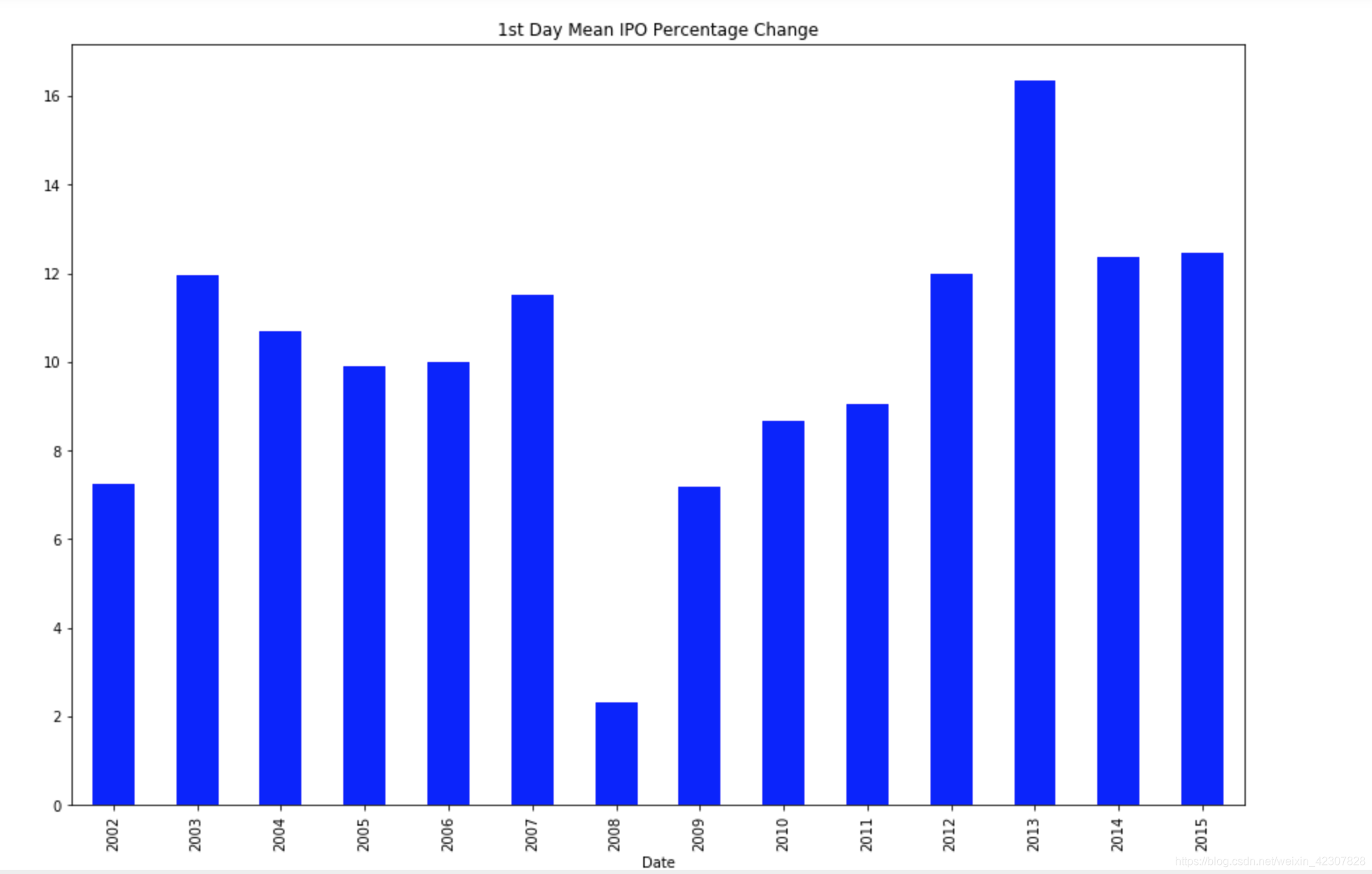
通过中位值来进行对比
ipos.groupby(ipos['Date'].dt.year)['1st Day % Px Chng'].median().plot(kind='bar', figsize=(15,10), color='r', title='1st Day Median IPO Percentage Change') 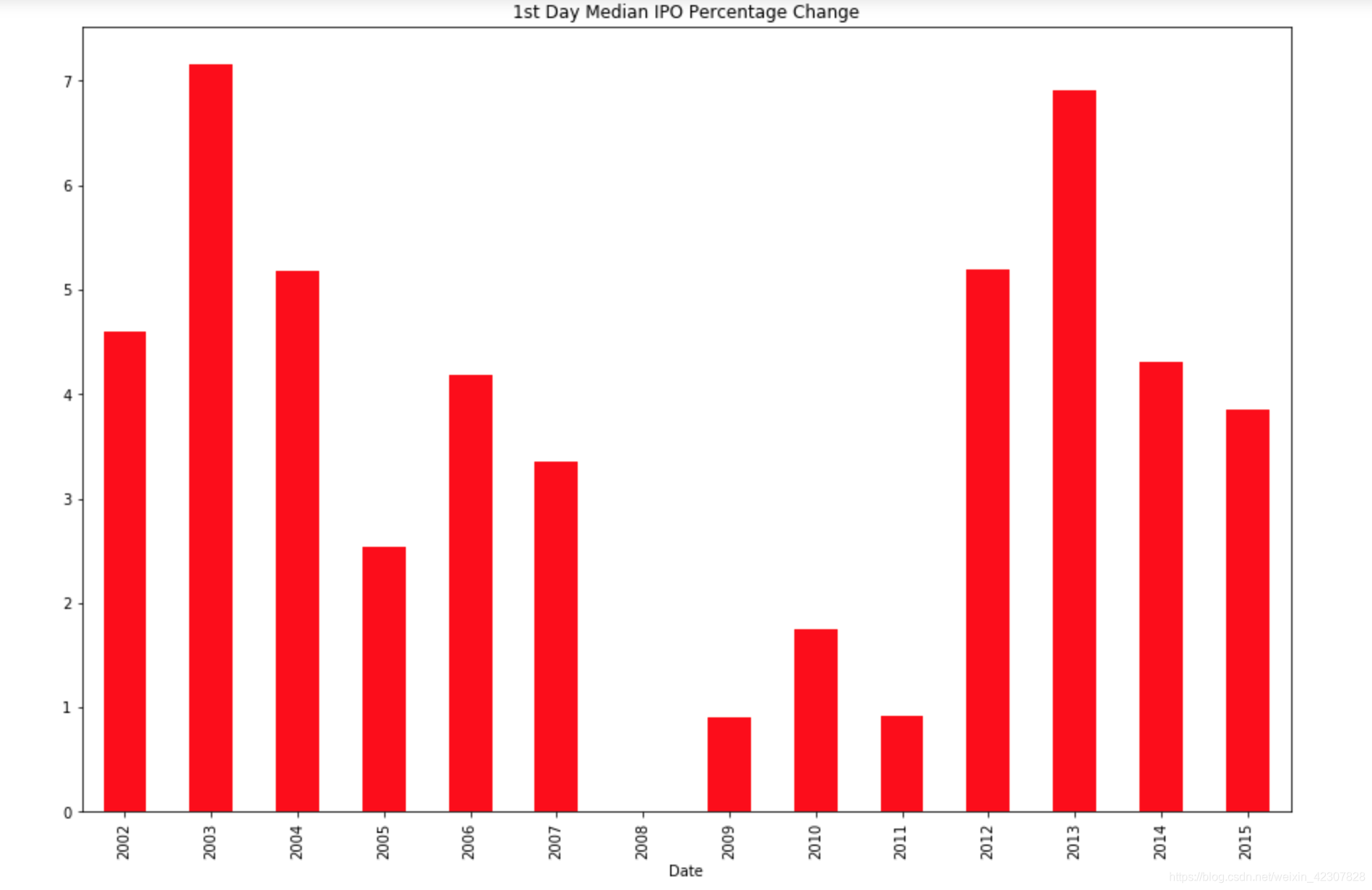
平均值和中位值差距很大,我们可以很清楚的发现,一些较大的值影响了回报分布的坡斜。
通过分析图片
ipos['1st Day % Px Chng'].hist(figsize=(15, 7), bins=100, color='grey')
从上图,我们可以看到大多数回报集中在零附近,但有个长尾一直拖到右侧,那里有一些真正的全垒打(这里形容非常成功的发行)发行价。
我们已经看过第一天的百分比变化,就是从发行价到当天收盘价的差距,但正如我前面所指出的,很少有机会能够以发行价买入。既然如此,现在让我们来看看开盘价到收盘价的收益率。它有助于我们理解这个问题:所有的收益都是给了那些拿到发行价的人,还是说在第一天人们仍然有机会冲入并获得超高的回报?
查看错误数据
ipos[ipos['% Chg Open to Close']<-98]
ipos.loc[440, '$ Chg Opening'] = .09
ipos['% Chg Open to Close'].describe()
ipos[ipos['% Chg Open to Close']<-45]
ipos.loc[1264, '$ Chg Opening'] = .01
ipos.loc[1264, 'Opening Price'] = 11.26
ipos['$ Chg Open to Close'] = ipos['$ Chg Close'] - ipos['$ Chg Opening']
ipos['% Chg Open to Close'] = (ipos['$ Chg Open to Close']/ipos['Opening Price']) * 100
ipos['% Chg Open to Close'].describe()count 2329.000000 mean 0.863498 std 9.099885 min -40.383333 25% -2.814570 50% 0.000000 75% 3.686636 max 113.333333 Name: % Chg Open to Close, dtype: float64
通过排序查看
ipos.sort_values('% Chg Open to Close').head()