版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/fenglingfeixian/article/details/81132737
第2章 变量和基本类型
- 什么是对象: 内存中具有类型的区域。
- 初始化不是赋值: 初始化指创建变量并给它赋初始值,而赋值则是擦除对象的当前值并用新值代替。
- extern: 当碰到它搞不清楚时,想一想声明和定义的关系,声明可以有多份,但定义必须有且只能有一份。
- const 和 extern: 定义全局变量时,隐式包含 extern,但如果还加了 const 的话(被限制了本文件使用),就要显示加上 extern 了,否则别的文件无法引用。有一种情况例外:声明在头文件中的常量表达式(比如enum),包含它的每个文件都会自带一份(名称和值都一样),大部分编译器编译时便会将使用的地方替换成常量表达式,所以并不会为const变量开辟存储空间。(如果此时加了extern,反而会出现重复定义的报错)
- struct 和 class: 二者效果相同,唯一的区别在于默认访问级别不同。
趣味题
union Un
{
int8_t a[4];
int32_t b;
};
Un u;
u.b = 1;
if (u.a[0] == 1)
cout << u.a[0] << endl; // 有输出,但是输出“笑脸”
// 思考:明明等于1,为什么输出不等于1?
// 猜测:== 是根据内存对比的,cout 却是根据内存类型(int)输出的。
第3章 标准库类型
- vector: 下标操作不能用来新增元素;for 循环的判断条件用 != 而不是用 < ;界限用 .size() 不需要提前保存。
- const_iterator:
const ivec<int>::iterator iter和const int *p不一样,后者不可改变 *p 的值,但前者是不能 iter++。要想限定所指向的值不能改变,有专门的定义方式ivec<int>::const_iterator iter。 - size_type 和 difference_type: 一个 unsigned 一个 signed ,足够大来存储大小,应用于 string 、vector 当中。
- 任何改变 vector 长度的操作都会使已存在的迭代器失效。
- bitset 和 vector: 二者同为类模板,vector 抽离类型,bitset 抽离长度,在尖括号内给出长度值。
- bitset 初始化: bitset 对象内存从0开始是低位到高位,但是输出时从高位到低位。string 对象和 bitset 对象之间是反向转化的(高低位颠倒)。
第4章 数组和指针
- 概念: 类似于 vector 和迭代器的内置数据类型,尽量避免使用(容易出错难于调试),除非设计强调速度的良好程序。
- 指针: 提供对其所指对象的间接访问,相对于迭代器,结构更通用一些。
- 取地址操作符 &: 只有当变量用作左值时,才能取其地址。P.115
- 指针注意事项: 最好在定义指针时就初始化,如果一定要分开,也要初始化为0。这样编译器才能检测出(未初始化、指向不可控地址,是无法检测出来的)。
- void 指针:* 可以保存任何类型对象的地址。操作有限:1.与另一个指针进行比较;2.向函数传递 void* 指针或从函数返回 void* 指针;3.给另一个 void* 指针赋值。
- 怎么理解? 如果指针指向一对象,可以在指针上加1从而获取指向相邻的下一个对象的指针。
- 指针相减: 只要两个指针指向同一数组或有一个指向数组末端的下一单元,C++还支持对这两个指针做减法操作。得到的数据是标准库类型 ptrdiff_t,与 size_t 类型一样,是在 cstddef 头文件中定义的一种与机器相关的类型(可以和 vector中的 size_type、difference_type 做类比)。
- 下标操作符 []: 使用下标访问数组时,实际上是对指向数组元素的指针做下标操作(没错,指针也可以用下标操作:p[i] 等效于 *(p+i),并且支持负数)。P.122
- for 循环新知识: 只要定义的多个变量具有相同的类型,就可以在 for 循环的初始化语句中同时定义它们。(常规只能写一条)。
- 指针是数组的迭代器: 循环遍历时,可以像迭代器一样,指针 p 等效于begin(),p + size 等效于end()。
- 疑问: 为什么指向 const 对象的指针,在定义时不需要对它进行初始化?P.124
- 解答: 和 const 指针作对比,与任何 const 量一样,const 指针也必须在定义时初始化。
- 指针和 typedef:
typedef string *pstring; const pstring cstr;如果把 typedef 当做文本扩展,就会错误的理解为 cstr是一种指针,指向 string 类型的 const 对象。正确答案是:cstr 是指向 string 类型对象的 const 指针。 - cstring 的关系: cstring是 string.h 头文件的 C++ 版本,而 string.h 则是 C 语言提供的标准库。
- 动态数组:
int *pia = new int[10];1、这样创建的数组没有名字,只能通过地址间接访问堆中对象。2、类类型会调用默认构造函数,内置类型无初始化。可以跟一对圆括号统一初始化,但无法像数组变量一样,用初始化列表给元素提供各不相同的初值。 - const 对象的动态数组: 必须在定义时就初始化,因为常量元素不允许被修改。正因如此,这样的数组实际上用处不大。
- 允许动态分配空数组: 之所以要动态分配数组,往往是由于编译时并不知道数组的长度。
size_t n = get_size(); int *p = new int[n]; for (int *q = p; q != p + n; ++q)有趣的是get_size()返回0的时候,也能正常运行,只是指针不能取引用。 - 动态空间的释放: delete [] 表达式,如果遗漏了空方括号,会导致运行时少释放了内存空间,从而产生内存泄露。
- 新旧代码兼容: C 风格的可以初始化 string 类型,但反之不行。必须采取以下方式,并且加上 const。还要注意中途修改了 str 后,该指针可能失效,所以最好是用之前拷贝一份。
const char *pstr = str.c_str();
第5章 表达式
- 除以和求模: 求模操作符号不同时,结果依赖于机器。但规律一定:如果求模的结果随分子的符号,则除出来的值向零一侧取整;如果求模与分母的符号匹配,则除出来的值像负无穷一侧取整。
- 短路求值: 逻辑与和逻辑或操作符总是先计算其左操作数,当仅靠左操作数的值无法确定结果时,才会求解其右操作数。具有危险边界时适用。P.146
- 位操作符: 对于符号位的处理依赖于机器,所以强烈建议使用 unsigned 整型操作数。
- 位运算与 bitset: 标准库提供的 bitset 操作更直接、更容易阅读和书写、正确使用的可能性更高,并且对象的大小不受 unsigned 数的位数限制。
- 移位操作符:中等优先级。
- 赋值操作符: 赋值操作符的左操作数必须是非 const 的左值。数组名是不可修改的左值,因此不能作为赋值操作的目标。而下标和解引用操作符都返回左值,因此当作用于非 const 数组时,其结果可作为赋值操作的左操作数:
int ia[10]; ia[0] = 0; *ia = 0; - 赋值操作符:低优先级、右结合性(与常规二元运算符不同)
- 复合赋值操作符: 可以是以下十种:
+= -= *= /= %= <<= >>= &= ^= |=。使用复合赋值操作时,左操作数只计算了一次;而使用相似的长表达式时,该操作数则计算了两次,第一次作为右操作数,而第二次则用作左操作数。 - 自增和自减操作符: 前置操作返回对象本身,是左值。而后置操作返回的则是右值。对于 int 型对象和指针,编译器可优化掉这项额外工作,但对于更多的复杂迭代器类型,可能会花费更大的代价。因此,养成使用前置操作这个好习惯,就不必操心性能差异的问题。
- 箭头操作符: 对于指向类类型的指针变量,访问其成员时可用
p->foo;取代(*p).foo;。 - 条件操作符: 是C++中唯一的三元操作符,它允许将简单的 if-else 判断语句嵌入表达式中。
- 逗号操作符: 逗号表达式是一组由逗号分隔的表达式,这些表达式从左向右计算。逗号表达式的记过是其右边表达式的值,如果是左值结果也是左值。
- 优先级和结合性: 优先级决定操作数的结合方式,结合性决定操作数的计算顺序。P.161(但这二者都不能定义求值顺序P.163)
- 动态创建对象 new: 定义变量时,必须指定其数据类型和名字。而动态创建对象时,只需指定其数据类型,而不必为对象命名。取而代之的是,new 表达式返回指向新创建对象的指针。
- 动态创建对象的默认初始化:
int *pi = new int;和int *pi = new int();是不一样的,前者没有定义,后者初始值为0。 - 撤销动态创建的对象 delete: 如果指针指向不是用 new 分配的内存地址,则在该指针上使用 delete 是不合法的。(编译器甚至无法发现错误。例如:
int i; int *pi = &i; delete pi;)在 delete 之后,重设指针的值 - 零值指针的删除: C++保证:删除0值的指针时安全的。(虽然这样做没有任何意义。)
- 动态内存的管理容易出错: 1、删除失败,该块内存无法返还给自由存储区,导致内存泄漏(不易发现,程序运行一段时间后内存不足才知道);2、读写已删除的对象。(删除后立即置0可避免);3、同一块内存空间连续两次delete。(自由存储区可能会被第二次删除破坏)
- 隐式类型转换: 1、在混合类型的表达式中,操作数被转换为相同类型;2、用作条件的表达式被转换为 bool 类型;3、表达式初始化或者赋值某个变量,被转换为该变量的类型。
- **算术转换:**研究大量例题是帮助理解算术转换的最好方法。P.170
- 其他隐式转换: 1、**指针转换:**数组大多情况自动转换为指向第一个元素的指针;任意数据类型的指针都可转换为void*类型;整型数值常量0可转换为任意指针类型。
- 命名的强制类型转换: dynamic_cast、const_cast、static_cast、reinterpret_cast。
趣味题:
if (val == true)
if (val)
// val 为bool类型时,二者等价。
// 如果不是,上面等于1满足,下面非0即满足。
第6章 语句
- 复合语句: 用花括号括起来的块语句。
- if 语句: 条件中可以是表达式,或者是一个初始化声明。必须初始化,然后转化为 bool 型的类型。类类型能否用在条件表达式中取决于类本身。IO通常可以,vector 和 string 一般不可用。
- 悬垂 else 问题: 在 if 语句后加花括号是一个好习惯,可以避免这种二义性。P.185
- switch 表达式: 求解的表达式可以非常复杂,并可以定义和初始化一个变量,但只能在结构内使用。
- case 标号: 必须是整型常量表达式。
- switch 内部的变量定义: 最好用花括号括起来行程块语句,不然下一个 case 能使用该变量,但有可能被该 case 标签跳过初始化。
- while 和 do while: 后者的判断条件中不可以定义变量。
- 使用预处理器进行调试:
#ifndef NDEBUG #endif - 四种在调试时非常有用的常量:
__FILE__文件名、__LINE__当前行号、__TIME__文件被编译的时间、__DATE__文件被编译的日期。 - assert: 用来测试“不可能发生”的条件,只对程序的调试有帮助,但不能用来代替运行时的逻辑检查,也不能代替对程序可能产生的错误的检测(异常处理)。

第7章 函数

- **函数与操作符:**以前看操作符重载的时候,觉得操作符就是函数,实际二者的目的确实是一样的。
- **调用操作符:**C++语言使用调用操作符()(一对圆括号)实现函数的调用。把()当做操作符,参数当做操作数。
- **函数必须指定返回类型:**早期的C++版本可以不定义,会隐式返回 int 类型。
- 引用形参的两个作用: 1、避免复制类类型或者大型数组,造成效率低下。2、可以返回想要的,额外的信息。
- **const 引用:**如果函数唯一的目的是避免复制实参,则应将形参定义为 const 引用,避免让函数的使用遭到限制(const 实参无法传递)。
- **数组形参:**使用数组类型形参的函数,会被自动转化为指针。
int*; int[]; int[10]三者完全相同。编译器只会检查实参是不是指针,类型是否匹配,不会检查数组的长度。P.221 - **通过引用传递数组:**如果形参是数组的引用,编译器不会将数组实参转化为指针,而是传递本身,此时数组大小成为类型的一部分,编译器会检查是否匹配。
int (&arr)[10] - **多维数组的传递:**与一维数组一样,编译器忽略第一维的长度。
int matrix[][10]; int (*matrix)[10]这二者等效。 - 传递给函数的数组的处理: 1、C风格字符串,末尾null字符作为结束标记;2、显示传递数组大小
int j[] = {0, 1}; print(j, sizeof(j)/sizeof(*j));3、使用标准库规范,传递两个指针,一个指向第一个元素,一个指向最后一个元素的下一个位置。print(j, j+2); - **main 处理命令行选项:**第一个为参数个数(包含程序名),第二个有两种等效写法:
char *argv[]; char **argv; - **return 语句:**void 函数不允许返回表达式,但是可以返回同为 void 的函数。隐式的 return 发生在函数的最后一个语句完成时。
- **主函数 main 的返回值:**所有的非 void 函数都要有返回值,main 函数除外。它的返回值通常视为状态指示器,0代表成功,非0的意义因机器而不同。建议使用 cstdlib.h 中的宏定义 EXIT_SUCCESS、EXIT_FAILURE。
- 可以返回引用(比如返回两个字符串中较长的那个),但千万不要返回局部对象的引用,返回局部对象的指针也一样不行。
- **引用返回左值:**可以对返回值进行赋值。标准输出运算符
<<返回的也是引用值。 - 递归:递归函数必须定义一个终止条件,否则会一直调用自身知道程序栈耗尽。这种现象称为“无限递归错误”。满足了终止条件后,依次返回前面每个调用的返回值,这个过程称为此值向上回渗。主函数 main 不能调用自身。
- **函数声明:**一个函数只能定义一次,但是可声明多次。
- **函数原型:**函数原型描述了函数的接口,包括函数返回类型、函数名、形参列表(类型必须,命名可省略)三个元素。
- 小操作定义一个函数的好处: 1、便于阅读理解;2、只需修改一处;3、确保实现方式统一;4、不用重写代码。**缺点是:**额外开销大。(调用千要先保存寄存器,并在返回时恢复;复制实参;程序还必须转向一个新位置执行)
- **内联函数:**在编译时展开,避免调用函数的开销。所以函数的定义一定要放在头文件中。inline 对于编译器只是一个建议,它可以选择忽略。(貌似内敛函数可以定义多次,但要保证完全相同)
- 在头文件中加入或修改内联函数时,使用了该头文件的所有源文件都必须重新编译。
- **类成员函数与内联函数:**编译器隐式地将在类内定义的成员函数当做内联函数。
- 常量成员函数使用 const 的成员函数。const 对象以及指向它的指针或引用,只能调用常量成员函数。不能调用非 const 成员函数。const 和非 const 可以互为重载
- **隐式与显式:**类外定义的一个空参数列表函数,只能说它没有显示参数,因为还有一个隐式参数 this。
- **默认构造函数:**默认构造函数说明当定义对象却没有为它提供(显式的)初始化式时应该怎么办。
- 构造函数通常放在类的 public 部分,使用类的代码可以定义和初始化类的对象。如果定义为 private 的,就不能定义类的对象,就没有什么用了。
- **构造函数的初始化列表:**构造函数的初始化式是一系列成员名,父类的构造函数也可写在这里,可深入了解原因。
- **合成的默认构造函数:**如果没有为一个类显式定义任何构造函数,编译器将自动为这个类生成默认构造函数,依据变量初始化的规则初始化类中所有成员(类类型成员就会调用自身的默认构造函数)。
- **使用建议:**合成的默认构造函数一般适用于仅包含类类型成员的类。而对于含有内置类型或复合类型成员的类,则通常应该定义他们自己的默认构造函数初始化这些成员。
- **函数重载:**只有返回类型不同,无法实现重载;参数只有 const 区别也无法实现重载,const 引用或者指针才可以;有的时候不重载,使程序更易于理解。
- 重载与作用域:局部声明一个同名函数,该函数将屏蔽而不是重载。一般来说,也不会局部地声明函数,而是应该放在头文件中。
- **名字查找:**名字查找发生在类型检查之前。屏蔽的原理是调用函数时,编译器首先检索这个名字的声明,一旦在局部找到,将不再继续检查这个名字是否在外层作用域中存在。
- 重载确定的三个步骤: 1、候选函数(名字);2、选择可行函数(参数个数、类型);3、寻找最佳匹配(类型精准大于转换)。
- **调用重载函数的二义性:**可通过显式的强制类型转换强制函数匹配,但在实际应用中要尽量避免,出现这种情况通常意味着设计的形参集合不合理。
- **参数匹配和枚举类型:**虽然无法将整型值传递给枚举类型的形参,但可以将枚举值传递给整型形参。
- **重载和 const 形参:**仅当形参是引用或指针时,形参是否为 const 才有影响。
- 指向函数的指针: 1、可用 typedef 简化函数指针的定义;2、在引用函数名但有没有调用该函数时,函数名将被自动解释为指向函数的指针,取地址操作符可省略(调用时解引用操作符也可省略);3、指向不同函数类型(函数返回类型、参数列表决定)的指针之间不存在转换。
- **返回指向函数的指针:**第一遍阅读没完全理解。P.253
- **指向重载函数的指针:**在定义初始化时,指针的类型必须与重载函数的一个版本精确匹配。(不像使用函数时类型兼容就行)

##第8章 标准IO库
- **普通流(控制台)、文件流、string 流:**相互有一定的继承关系。P.259
- IO 对象不可复制或赋值: 1、不能存储在 vector(或其他)容器中;2、流类型作为形参或返回类型,必须是指向该对象的指针或引用(对 IO 对象的读写会改变它的状态,因此引用必须是非 const 的)。
- **条件状态:**如果输入类型错误、或者遇到文件尾,都会改变对象的状态。badbit 故障无法恢复,failbit 可恢复,eof 同时设置了 failbit。操作函数参考P.261。
- **流状态的查询和控制:纠正点:**碰到错误类型的输入后,只调用 clear() 是不够的,因为错误的输入还存在于缓冲区,cin 每次都会读取它,最后造成无限循环。可以在 clear() 后面调用 ignore(),提取输入字符并丢弃他们,因为默认值为1,EOF,所以还可以改进成
cin.ignore(numeric_limits<streamsize>::max(), '\n');。参考自https://www.cnblogs.com/kaituorensheng/p/3463415.html
###8.3 输出缓冲区的管理
- 刷新输入缓冲区的5种情况: 1、程序正常结束;2、缓冲区已经满了;3、用操纵符(例如行结束符endl);4、用 unitbuf 操纵符设置,每次输出操作执行完后即刷新;5、将输出流与输入流关联起来。
- **如果程序崩溃了,则不会刷新缓冲区:**所以在利用打印输出跟踪调试时,要确保缓冲区已刷新,所有应该输出的都输出了,否则会浪费大量时间调试已执行过的代码(书中写的是“未执行过的代码”,个人有疑问?)。
- 将输入和输出绑在一起:
cin.tie(&cout); ostream *old_tie = cin.tie(); cin.tie(0); cin.tie(&cerr); cin.tie(0); cin.tie(old_tie);一个 ostream 对象每次只能与一个 isteam 对象绑在一起,tie 函数传递实参0则打破该流上已存在的捆绑。
###8.4 文件的输入输出
- **文件流对象的使用:**可以先定义对象,再用.open(“in”) 来绑定文件,也可以在定义的时候直接初始化,但需要注意,犹豫历史原因,IO 标准库使用 C 风格字符串,也就是说,如果传入的是 string 对象,需要调用 c_str 函数获取 C 风格字符串。
- **检查文件打开是否成功:**打开文件后,通常要检验打开是否成功,这是一个好习惯。与之前测试 cin 是否达到文件尾或遇到某些其他错误的条件类似,检测对象是否为 IO 做好准备。
- **清除文件流的状态:**如果程序员需要重用文件流读写多个文件,必须在读另一个文件之前调用 clear 清除该流的状态。
- 文件模式: ifstream 默认以 in 模式打开,ofstream 默认以 out 模式打开(out 模式会同时触发 trunc 模式)。模式之间用按位与操作符来实现复选。
- 对于用 ofstream 打开的文件,要保存文件中已存在的数据,唯一的方法是显式地指定 app 模式打开。fstream 默认打开则不用,因为以 in 和 out 同时打开,但单独使用 out 模式,还是会被清空的。
- **模式是文件的属性而不是流的属性:**只要调用 open 函数,就要设置文件模式,可以是显式的也可以是隐式的(使用默认值)。
- **打开模式的有效组合:**有些模式组合是没有意义的。常用的参见P.270
###8.5 字符串流
- **stringsteam 对象的使用:**使用 getline 函数从输入读取整行内容,然后为了获得每行中的单词,将一个 istringstream 对象与所读取的行绑定起来,这样只需使用普通的 string 输入操作符即可独处每行中的单词(像从 cin 输入流读取一样)。P.271
- **常见用法:**需要在多种数据类型之间实现自动格式化时。可以将 int 类型的数据写到字符串流(<<),也可以将字符串流读回到 int 类型(>>)(空白符会被忽略)。与标准流做类比会更容易理解。
#第二部分 容器和算法
- **泛型指的是两个方面:**这些算法可作用于不同的容器类型,而这些容器又可以容纳多种不同类型的元素。
- **容器提供的操作和算法是一致定义的:**只需理解一个操作如何工作,就能将该操作应用于其他的容器。
- 容器提供了不同的性能折中方案,可以改变容器类型对优化系统性能来说颇有价值。
- **容器类型的操作集合形成了一下的层次结构:**1、一些操作适用于所有容器类型;2、另外一些操作则只适用于顺序或关联容器类型;3、还有一些操作只适用于顺序或关联容器类型的一个子集。
第9章 顺序容器
- 三种顺序容器类型: vector、list、deque。他们的差别在于访问元素的方式,以及添加或删除元素相关操作的运行代价。
- **三种容器式适配器:**stack、queue、priority。适配器是根据原始的容器类型所提供的操作,通过定义新的操作接口,来适应基础的容器类型。
- 容器元素的初始化: 1、将一个容器初始化为另一个容器的副本;2、初始化为一段元素的副本(通过一对迭代器);3、分配和初始化指定数目的元素(只适用于顺序容器)。
- 小技巧:
char *words[] = {"apple", "banana", "pear"; size_t words_size = sizeof(words)/sizeof(char *); list<string> words2(words, words + words_size);指针也是迭代器。 - **容器内元素的类型约束:**IO 库类型不支持复制或赋值,引用不支持一般意义的赋值运算,所以这些类型不能存放于容器中。容器本身可以作为容器类型存放于容器中。
- **容器操作的特殊要求:**除要满足基本的复制和赋值以外,部分容器对元素类型还有特殊要求,否则只能定义该类型的空容器,但却不能使用它。没有默认构造函数,但有带参构造函数也行,只不过不能使用
vector<Foo> vec(6);这种方式初始化。 - **容器的容器:**定义时注意用空格隔开,否则当做
<<和>>运算符。 - 容器定义的类型别名:
size_typeiteratorconst_iteratorreverse_iteratorconst_reverse_iteratordifference_typevalue_typereferenceconst_reference把 iterator 看做指针value_type*,reference 看做引用value_type&,更容易理解。 - **使迭代器失效的容器操作:**任何 insert 或 push 操作都可能导致迭代器失效。当编写循环将元素插入到 vector 或 deque 容器中时,程序必须确保迭代器在每次循环后都得到更新。使用无效迭代器将会导致严重的运行时错误。
- 关键概念:容器元素都是副本
- **避免存储 end 操作返回的迭代器:**不要存储 end 操作返回的迭代器。添加或删除 deque 或 vector 容器内的元素都会导致存储的迭代器失效。
- 关系操作符:类型相同,元素类型也相同的两个容器才能进行比较。比较流程总结:看是不是对方的子序列,是则比较容器长度,不是则比较第一个不相等的元素。
- **比较原理:**所有容器都通过比较其元素对来实现关系运算。也就是说存放没有定义关系运算的类类型的容器,不能比较。
- 容器大小的操作:
c.size();c.max_size()c.empty()c.resize(n)c.resize(n,t)resize 操作可能会使迭代器失效。 - 访问元素:
c.back()c.front()c[n]c.at(n)所有的操作都要程序保证容器不为空。at 操作和下标运算一样,但是在越界时会抛出 out_of_range 异常(下标则是运行时错误)。 - 删除元素: insert 操作插入单个值,返回指向该值的迭代器,删除单个或多个值则返回指向下一元素的迭代器。pop_front 和 pop_back 函数的返回值并不是删除的元素值(就像 push_pack 也一样),而是 void。要获取删除的元素值,必须在删除前调用 front 或 back 函数。
- **删除容器内的一个元素:**在删除元素之前,必须确保迭代器不是 end 迭代器,删除末端下一位置的行为未定义。
- **assign 与 swap:**swap交换容器后,并没有移动元素,所以迭代器不会失效。assign 操作不支持重设指定数目但不带初始化值的,用迭代器作参数的话还可以忽略容器类型。
- **vector 容器的自增长:**插入元素当存储空间不足时,vector 必须重新分配存储空间,(如果有初始化值,先调用构造函数创建临时对象),然后存放在旧存储空间中的元素被复制(拷贝构造函数)到新存储空间里,接着插入新元素(拷贝构造函数(临时对象)),最后撤销旧的存储空间。
- **多思多学:**reserve操作,会调用拷贝构造函数。
- 插入操作如何影响容器的选择:
- **容器的选用:**通常来说,除非找到选择使用其他容器的更好理由,否则 vector 容器都是最佳选择。
- 选择容器的提示:
- 如果**无法确定某种应用应该采用哪种容器,**则编写代码时使用迭代器,而不是下标。这样在必要时可以很方便地将程序从使用 vector 容器修改为使用 list 容器。
- 再谈 string 类型: string 库定义了大量使用重复模式的函数。由于该类型支持的函数非常多,可先跳过,以后编写需要使用某种操作时,才回来阅读细节。9.6 节跳过。
- 容器适配器: 1、适配器的初始化;2、覆盖基础容器类型(还不理解);3、适配器的关系运算。
- 栈适配器:
s.empty()s.size()s.pop()s.top()s.push(item)尽管栈是以 deque 容器为基础实现的,但是程序员不能直接访问 deque 所提供的操作,只能使用栈适配器提供的操作。


###趣味题:
class A
{
public:
A(int a) {cout << "A(" << a << ")" << endl;
};
vector<A> vec(3, 9); //为何此处只会调用一次构造函数
//而改为默认构造函数,就会调用三次
**原因:**有初始化式的时候,在创建 vector 之前就会创建一个临时对象,而后就只调用3次拷贝构造函数。可能是从性能出发考虑。
###小技巧:
构造函数带有两个参数的类类型,初始化时可用花括号体。vector<A> vec(3, {6,7}); 花括号数组初始化容器不知道是不是也是这个原理。vector<int> ivec({1,2,3}); vector<int> ivec2 = {4,5,6};
##第10章 关联容器
###10.1 引言:pair 类型
- pair 类型的使用相当繁琐,因此,如果需要定义多个相同的 pair 类型对象,可考虑利用 typedef 简化其声明。
- 创建 pair 对象的三种方式: 1、定义时提供初始化;2、访问 pair 对象的数据成员;3、使用 make_pair 函数生成 pair 对象。建议使用第三种,能更明确地表明生成 pair 对象这一行为。
- 应用场景还需实践深刻理解:

###10.3 map 类型
- map 的构造函数:
- 键的类型有一定约束:
- map 定义的类型:
- 使用下标访问 map 对象:
下标行为的编程意义,如果容器中不存在该元素,则添加新元素,使程序惊人地简练。
- map::insert 的使用:
- **以 insert 代替下标运算:**主要看是否需要修改原来的值,insert 在添加时,如果原先就有值,就返回对应迭代器和添加失败的 bool 值,纯粹地理解为“插入”操作。而下标运算则一定会修改对应值。
- 例外: 下标运算会有一定的副作用,是否使用取决于程序员的意愿,像统计单词出现的次数,则下标运算更好用,但在查找使用中则不一定。
- 查找并读取 map 中的元素:
- 从 map 对象中删除元素:






##第11章 泛型算法
- 头文件定义: 泛型算法
#include <algorithm>、泛化的算术算法#include <numeric> - accumulate(累加算法)
- **关键概念:**算法永不执行容器提供的操作。
- **find_first_of(查找另一范围中任意元素匹配的元素)**巧妙的算法:
- 写容器元素的算法:
fill(vec.begin(), vec.end(), 0);这类带范围的写入是安全的;fill_n(vec.begin(), 10, 0);如果vec是空的,写入并不存在的元素,结果是未定义的,可能导致运行时错误。 - **引入 back_inserter:**迭代器适配器(类似于容器适配器)可以帮助解决上面问题。
fill_n(back_inserter(vec), 10, 0);必须#include <iterator>。 - 写入到目标迭代器的算法:
copy(ilst.begin(), ilst.end(), back_inserter(ivec));从输入范围中读取元素,复制给目标 ivec。这个例子中效率比较差,用一个已存在容器的迭代器直接初始化另一容器更好。 - 算法的_copy 版本:
replace(ilst.begin(), ilst.end(), 0, 42);范围内0替换为42,。如果不想改变原来的序列,replace_copy(ilst.begin(), ilst.end(), back_inserter(ivec), 0, 42); - sort(排序)
- **unique(去重)**并没有删除元素,只是放到了后面,返回指向最后一个不重复元素的下一位置。


###11.3 再谈迭代器
- 另外三种迭代器:
- 插入迭代器:
front_inserter、back_inserter、inserter。 - 流迭代器:
- 反向迭代器:
- **五种迭代器:**如果一个迭代器支持某种地带去类别要求的运算,则该迭代器属于这个迭代器类别。


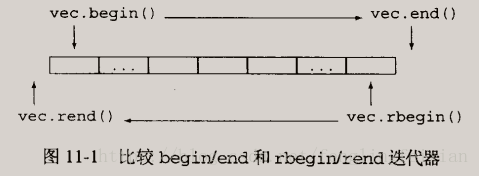


###11.4 泛型算法的结构
- 了解算法的结构要比死记它们要好。
- 算法的形参模式:

###11.5 容器特有的算法
- 对于 list 对象,优先使用 list 容器特有的成员版本,而不是泛型算法,原因是:

##第12章 类
###12.1 类的定义和声明
- 访问标号实施抽象和封装:
- 类的使用和设计:
- **使用类型别名来简化类:**放在 public 访问标识符中,代表允许用户使用这个名字。
- 在类的外部定义 inline 的一个好处是可以使得类比较容易阅读
- 前向声明(不完全类型):
- 为类的成员使用类声明:






###12.2 隐含的 this 指针
- **从 const 成员函数返回 *this:**成员函数中的 this 指针本身就是 const 指针,不能修改它的地址。
- 基于 const 的重载:
- 可变数据成员: mutable 修饰的为可变数据成员,即使在 const 成员函数中,也可以修改它的值。
- 建议:用于公共代码的私有实用函数:
- **函数返回类型不一定在类作用域中:**其他的形参表、函数体、成员都在类作用域中(可免去使用
this和::),唯独函数返回类型不是。



###12.3 类作用域
- **使用类的成员:**一般的数据成员和函数,使用对象和成员访问操作符(
.或者->)来访问,定义类型的成员直接通过类使用作用域操作符::来访问。 - 类作用域中的名字查找: 1、函数中查找;2、类成员中查找;3、类定义的全局作用域查找(类外定义的函数还会查找函数定义位置的全局作用域)。不管哪种方式,都遵循先声明后使用,也就是在使用前的位置查找
###12.4 构造函数
- **const 用于构造函数是非法的:**构造函数的工作是初始化对象,定义为 const 明显是不必要的。
- **构造函数初始化列表:**创建对象时,先执行初始化,再执行构造函数的函数体。
- 指针则不受限制,和引用(一定要初始化)的区别也在这里体现了出来。
- **成员初始化的次序:**按照定义的顺序执行。尽可能避免用成员来初始化其他成员。
- **类类型的数据成员的初始化式:**使用起来就跟类类型直接定义并初始化一样。
- **默认实参与构造函数:**融合了传参和不传参的两个版本。
- **合成的默认构造函数:**使用与变量初始化相同的规则来初始化成员。
- **类通常应定义一个默认构造函数:**如果没有默认构造函数意味着:
- 特别注意:
Sales_item myobj();定义的是一个返回类类型的函数,并不是调用默认构造函数来定义一个类类型的对象。正确的方式有Sales_item myobj;或者Sales_item myobj = Sales_item(); - **隐式类类型转换:**以前认为初始化有两种:
A a(1);和A a = 1;。后面的形式实则是一种隐式的转换,先用 1 初始化一个临时A类型对象,然后将其赋值给对象 a(赋值操作并不会调用构造函数或者拷贝构造函数,真正调用是右值发生转换(隐式)的时候有待深究,参见13.1)。 - **抑制由构造函数定义的隐式转换:**当构造函数被声明为 explicit 时,编译器将不使用它作为转换操作符。**延伸:**拷贝构造函数前加 explicit 后
A b = a;也同样失效。 - **类成员的显示初始化:**对于没有定义构造函数并且其全体数据成员均为 public 的类,可以采用与初始化数组元素相同的方式初始化其成员
A a = {2, "hello"};。但会有三个明显的缺点:

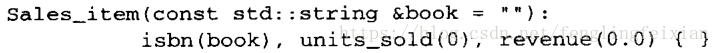



###12.5 友元
- 友元关系:
friend class B;友元可以是普通的非成员函数,或前面定义的其他类的成员函数,或整个类。 - **友元声明与作用域:**这一章一开始不是很明白,经过自己试验得出结论:对于需要被友元声明的成员函数(也就是用到其他类的私有数据成员),它必须放在类外定义,并且还需要在前面加一个“前向声明”(而不在声明友元函数的类前面加)。
class B; // 前向声明
class A
{
public:
void print(B &b); // 得益于前向声明。
};
class B
{
public:
friend void A::print(B &b); // 前向声明也不行,得益于类 A 已完成全部声明。
B() :i(1) {}
private:
int i;
};
void A::print(B &b)
{
cout << "A::print()" << endl;
cout << b.i << endl; // 必须放在类外定义才能实现。
}
- 使用友元的优缺点:

###12.6 static 类成员
- static 类成员是与类关联,而不是与类的对象关联: static 成员函数没有 this 形参,它可以直接访问所属类的 static 成员,但不能直接使用非 static 成员
- 使用类的 static 成员的优点:
- **static 成员函数:**类的外部定义无须重复制定 static 保留字。static 函数没有 this 指针,并且不能声明为 const 或者 virtual 。
- static 数据成员: static 数据成员必须在类定义体的外部定义(正好一次),要保证这一点的最好办法,就是放在包含类的非内联成员函数定义的文件(.cpp)中。
- 特殊的整型 const static 成员: static 和普通数据成员都不能在定义体中初始化,static 数据成员通常在定义时初始化(非 static 在创建对象时初始化),这一点很好理解。但有一个例外:const static 数据成员可以在定义体内初始化,但初始化之后,仍然要求在类的定义体之外进行定义(?测试类外不定义好像也可以),只不过不必在指定初始值。
const int A::period; - 疑问:static const 成员在类内已初始化,到底是否还需要在类外定义?
- **static 成员不是类对象的组成部分:**正因如此,它可以是自身类型的对象,而不像普通成员一样被限定声明只能是自身类对象的指针或引用。并且也可用作默认实参。牢记一点:static 数据成员独立于所属对象而使用。


##第13章 复制控制
- **复制控制:**复制构造函数、赋值操作符、析构函数总称为赋值控制。编译器自动实现这些操作,但类也可以定义自己的版本。
###13.1 复制构造函数
- 赋值操作符有时候不会触发赋值构造函数?
- **定义自己的复制构造函数:**一定要声明为 const 的引用,否则在复制时会有很多问题,包括
vector<A> vec(3,9); // 怀疑是用const形式的临时变量去作初始化的。 - **vector 初始化总结:**如果只给个数的参数,没有初始化,就全部调用默认构造函数初始化;如果给了个数和初始化值,则先调用对应的构造函数生成临时变量,然后调用对应个数的复制构造函数(并且是用 const 对象去传参的)(编译器自动合成的复制构造函数,也是带 const 的)。
- **禁止复制:**声明为 private,将不允许用户代码复制该类类型的对象,如果想要连友元和成员中的复制也禁止,就声明一个 private 复制构造函数但不对其定义。
- 大多数类应定义复制构造函数和默认构造函数:


13.2 赋值操作符
- 列表内容
13.3 析构函数
- 何时调用析构函数:动态分配的对象只有在指向该对象的指针被删除时才撤销(对象的引用也不行)。删除数组时为逆序撤销。
- **三法则:**定义其中任意一个,都要定义其他两个。
- 三法则原因:P.432
- **合成析构函数:**这句话不是很理解。



###13.4 消息处理机制
- **疑问:**赋值操作符的后半段代码(复制两个数据成员和添加到Folder中)为什么不用复制构造函数去完成?(正好操作一样啊)
13.5 管理指针成员
- 定义智能指针类:
- **定义值型类:**像 string 类型一样,完全是原来对象的一个副本。编写赋值操作符时特别要注意:
- 小结:



第14章 重载操作符与转换
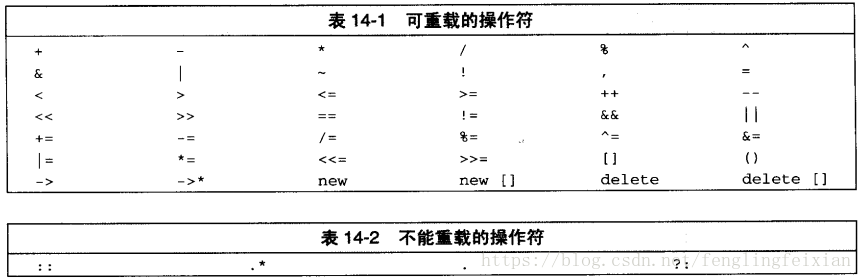
- 重载的操作符名:
- 重载操作符必须具有一个类类型操作数:
- 优先级和结合性是固定的:
- 不再具备短路求值特性:
- **类成员与非成员:**一般将算术和关系操作符定义为非成员函数,而将赋值操作符定义为成员函数。
- **操作符重载与友元关系:**操作符定义为非成员函数时,通常必须将它们设置为所操作类的友元。
- **使用重载操作符:**既可以像调用函数一样使用
cout << operator+(item1, item2) << endl;、item.operator+=(item2);,也可以像内置类型一样使用cout << item1 + item2 << endl;、item1 += item2;。 - 不要重载具有内置含义的操作符:
- 审慎使用操作符重载:
- **相等和关系操作符:**要用作关联容器键类型的类应定义
<操作符。顺序容器则要定义==和<。如果定义了==通常也要定义!=,定义了<通常要定义全部的四个关系操作符>, >=, <, <=。 - **选择成员或非成员实现:**一些经验上的指导原则:






14.2 输入和输出操作符
- **输出操作符<<的重载:**让用户自己控制输出细节:
- **IO操作符必须为非成员函数:**原因:如果定义在类中,使用的方法与内置类型恰好相反;IO是标准库的组成部分,我们也不能改写。所以只能是定义为非成员函数。通常还将IO操作符设为友元,因为要对非公有数据成员进行读写。
- **输入操作符>>的重载:**对比与输出操作需要额外注意的地方:
- **处理输入错误:**如果发生了错误,就将形参恢复为空对象,避免成为一个无效状态。这样做的目的是,即使用户忽略了输入可能错误,也不会产生令人误解的结果,因为它的数据是内在一致的。
- **指出错误:**有时输入的字符串并不是真正的ISBN。这种情况下,尽管从技术上说实际的IO是成功的,但输入操作符仍可能需要设置条件状态以指出失败。通常输入操作符仅需设置 failbit。


14.3 算术操作符和关系操作符
- **加法操作符:**算术操作符通常产生一个新值,返回一个临时变量。内部实现可以利用复合赋值操作。
- **相等操作符:**理解设计原则:
- 下标操作符:




14.6 成员访问操作符
这一节有点复杂,没完全看懂,暂时先过一遍。
14.7 自增操作符和自减操作符
- **后置操作带一个 int 参数:**后置实现中会调用前置操作,同时检查范围这一工作也交给前置操作。
14.8 调用操作符和函数对象
- **函数对象可以比函数更灵活:**函数对象通常用于通用算法的实参,因为算法本身的限制,在调用传入的普通函数时,参数数目是固定的,无法做的更通用。但是传入一个类类型的临时对象,会调用它的构造函数(参数数目无限制,初始化数据成员),然后调用重载的调用操作符,使用起来适用性更强。
- 标准库定义的函数对象:
- 函数对象的函数适配器:




14.9 转换与类类型
这一节没看明白,暂时先过一遍。


- 转换操作符:(特殊的类成员函数)
- **好像读懂了一点:**构造函数可以理解为内置类型转换为类类型,而这种机制则可以理解为类类型转换为内置类型(如果要自己实现这个设计,需要定义48个操作符,将会很复杂)。
- **实参匹配:**精准匹配高于需要标准类型转换匹配,如果类型转换中存在两条相似路径,则编译器会报错,匹配存在二义性(ambiguous)。
- 标准转换优于类类型转换。





第四部分 面向对象编程与泛型编程
第15章 面向对象编程
15.1 面向对象编程:概述

15.2 定义基类和派生类
- 派生类对象包含基类对象作为子对象:
- **用作基类的类必须是已定义的:**因为派生类需要确切知道有基类有哪些成员。
- **派生类的声明:**如果需要声明(但并不实现)一个派生类,比如前向声明,不需要包含派生列表,否则编译错误。
- 如果没有定义虚函数,只是进行了函数覆盖:
- **覆盖虚函数机制:**通常是派生类的成员函数中采取这样的措施,目的是调用基类的函数,免除重复代码的书写。
- **虚函数与默认实参:**虚函数的基类版本和派生类版本如果使用了不同的默认实参,通常会出问题。试验发现:相当于两个不同的函数,也就没有动态绑定一说了。
- Has a 和 Is a:
- struct 和 class:
- 友元关系与继承:
- 继承与静态成员:









15.3 转换与继承
- **派生类到基类的转换:**指针和引用没有什么问题,对象直接进行转换时要注意,可能也是调用的复制构造函数中的引用转换。
- **基类到派生类的转换:**这样的自动转换是不存在的,甚至基类引用或指针实际绑定的是派生类对象,在转换时也是受限的。除非确定转换是安全的,可以使用
static_cast或dynamic_cast。
###15.4 构造函数和复制控制
- 构造函数和复制控制成员(复制、赋值、析构)不能被继承。
- **派生类构造函数:**执行顺序:先执行基类构造函数,然后执行派生类初始化列表,最后执行函数体。
- **向基类构造函数传递实参:**派生类的初始化列表不能直接初始化基类的成员,但可以调用基类的构造函数达到效果。不指定执行次序,按书写次序执行。
- 代码重构:
- 只能初始化直接基类:
- **复制控制和继承:**派生类中合成的操作会使用基类的操作,对基类部分做复制、赋值或析构。
- **定义派生类复制构造函数:**定义时别忘了调用基类复制构造函数,否则默认调用合成复制构造函数。赋值操作符同理。
- **派生类赋值操作符:**不能像构造函数和复制构造函数那样使用初始化列表,只能在函数体内调用基类的赋值操作符。特别注意要假定左右操作数不同。
- 派生类析构函数:与复制构造和赋值操作符不同:派生类析构函数不负责撤销基类对象的成员,由编译器显示调用基类部分的析构函数,撤销顺序和构造顺序相反。总结:就是说不管你定没定义析构函数,派生类都会去调用基类析构函数。
- **虚析构函数:**基类为了将析构函数设为虚函数而具有空析构函数,是三法则的一个重要例外,此时并不表示也需要赋值操作符或复制构造函数。
- **构造函数和赋值操作符不是虚函数:**在构造函数运行的时候,对象的动态类型还不完整;赋值操作符因为参数类型不一样,会令人混淆。
- 总结:
A b(a);和A b = a;和A b = A(a);都一样,只是调用复制构造函数。(自创理解方式:定义时,不会调用赋值操作符)


###15.5 继承情况下的类作用域
- **使用作用域操作符访问被屏蔽成员:**设计派生类时,只要可能,最好避免与基类成员的名字冲突。
- **using:**用于成员时,可以恢复基类中的访问权限(比如通过 private 继承而来的 public 数据成员),使得派生类的用户可以访问。用于成员函数时,可以使用被屏蔽的基类其他重载函数版本(因为基类的重载函数,派生类要么重定义所有,要么一个也不重定义,using 解决了这个问题)。
- **作用域与成员函数:**即使函数原型不同,基类成员函数也会被屏蔽,不会出现重载。一旦在派生类中找到名字,编译器就不再继续查找了。
- **虚函数与作用域:**如果派生类定义的虚函数的参数类型与基类不同,则发生的是屏蔽,并不是动态绑定。此时,基类的引用或指针无法调用到派生类的函数(即使是绑定到派生类对象),而派生类的对象也无法调用基类的函数(因为被屏蔽了)。这里正好解释了为什么赋值操作符不会定义成虚函数,即使定义了也是各用各的,互不相干。
- **疑问:**基类虚函数提供默认实参,而派生类虚函数不提供时,仍然可以完成动态绑定。派生类对象通过无参去调用反而不行。


15.6 纯虚函数
- 抽象类:

15.7 容器与继承

15.8 句柄类与继承
- **指针型句柄:**和智能指针一样的管理方式。
- **比较难理解,反复阅读,并仿照网上资料编写例子,得出以下总结:**句柄的用户可以获得动态行为但无需操心指针的管理(句柄类中都封装好了),就像使用类的对象一样方便。
- **复制未知类型:**在构造函数中不知道传进来的是基类对象还是派生类对象,所以需要定义一个 clone 虚函数,各类型分别返回自身类型的指针。
return new A(*this); - **debug 调试函数:**派生类的调用基类 debug 函数,再加上输出自身数据成员。没有数据成员的派生类可以不用定义,直接使用基类的。
- 允许用户打开或关闭调试: 1、通过定义 debug 函数的形参(修改默认实参);2、通过定义类数据成员,该成员允许个体对象打开或关闭调试信息的显示。

###15.9 再谈文本查询示例
这一节跳过!!!(考研面向对象编程设计能力)
##第16章 模板与泛型编程
- **两种多态性:**面向对象编程所依赖的是运行时多态性,泛型编程所依赖的是编译时多态性或参数式多态性。
16.1 模板定义
- **模板形参表:**不能为空,运行时提供实参来初始化形参。分为类型形参和非类型形参,类型形参的
class和typename没有任何区别。 - **使用函数模板:**编译器使用实参代替相应的模板形参产生并编译该版本的函数,承担了为我们使用的每种类型而编写函数的单调工作。
- inline 函数模板: 与非模板函数一样可以声明为 inline,但 inline 说明符必须放在模板形参表之后,返回类型之前。
template <typename T> inline T min(const T&, const T&); - 定义类模板:
- **模板声明:**每个模板类型形参前面必须带上关键字,不能省略。
- **在模板定义内部制定类型:**这一小节不是很明白。
- **总结:**定义在函数前面的模板通过函数调用时传入的实参确定类型,定义在类前面的模板通过类名加上尖括号内容确定类型。
- **非类型模板形参:**模板形参不必都是类型,可以用一个未确定值。
template<class T, size_t N> void array_int(T (¶m)[N]) {}


16.2 实例化
- **多个类型形参的实参必须完全匹配:**如果设计者想要允许实参的常规转换,则函数必须用两个类型形参来定义。或者实参为数组或者函数,形参是非引用,他们也可以转换为指针。
- **函数模板的显式实参:**某些情况下可能无法推断模板实参 的类型,特别是返回类型与形参表中所用的类型都不同时,最容易出现这一问题。显示指定:按位置顺序匹配,后面的省略。

16.3 模板编译模型
- 这一节有点难理解,需要反复阅读加动手操作,影响到头文件设计的问题。
- 按照例题解析写出来的代码运行不了,h文件包含了cpp文件有时可以有时不行,比较诡异。
###16.4 类模板成员
- **模板作用域中模板类型的引用:**在类中使用自己的类名可以不用带模板形参,但用其它模板的时候就必须要带上。
private: QueueItem<Type> *head; - **类模板成员函数的实例化:**比调用普通函数模板更灵活,由调用对象(包含了实参)确定成员函数模板的形参,因此传递的实参允许进行常规转换。
- **何时实例化类和成员:**类模板的指针定义不会对类进行实例化,只有用到这样的指针时才会对类进行实例化。
- **非类型形参的模板实参:**非类型的模板实参必须是编译时常量表达式是。
- 类模板中的友元声明: 1、普通非模板类或函数的友元声明(和平常一样);2、类模板或函数模板的友元声明(授予对友元所有实例的访问权,相当于多个一对多的关系);3、只授予对类模板或函数模板的特定实例的访问权的友元声明(需要前项声明)。
- **Queue 和 QueueItem 的友元声明:**自己写的例子无法链接成功,主要还是各文件相互包含的问题。模板编译模型不清楚,如果放在一起肯定是可以的。
- **成员模板:**速读。
- **完整的 Queue 类:**速读。
- **类模板的 static 成员:**速读。
16.5 一个泛型句柄类
- 跳读:
16.6 模板特化
- 跳读:
16.7 重载与函数模板
- 速读:

第五部分 高级主题
第17章 用于大型程序的工具
17.1 异常处理
- 当检测问题的部分不关心如何解决问题时:
- 异常是通过抛出(throw)对象而引发(raise)的。
- 执行 throw 的时候,不会执行跟在 throw 后面的语句。
- **栈展开:**寻找符合的 catch 子句的过程。
- 避免派生类对象被切割:
- **重新抛出:**重新抛出是后面不跟类型或表达式的一个 throw。
- 捕获所有异常的处理代码:
catch (...){}。 - **通过继承定义自己的异常类:**没有细看代码要有哪些具体的实现。使用上没有太大的区别。







17.1.9 auto_ptr类
- **auto_ptr 类:**只能用于管理从 new 操作(动态分配,堆内存)返回的一个对象,静态分配(栈内存)的对象不行。
- **reset 操作:**要么初始化绑定,如果初始化时未绑定,后期可用 reset 操作绑定。
ap.reset(0);代表解除绑定。





17.1.10 异常说明
- **定义异常说明:**在参数列表后
void recoup(int) throw (runtime_error);,空说明列表指出不抛出任何异常void no_problem() throw();。 - **异常说明与成员函数:**注意,在 const 成员函数声明中,异常说明跟在 const 限定符之后。
- **异常说明与析构函数:**编译器可以知道合成析构函数将遵守不抛出异常的承诺。string 析构函数保证不抛出异常,我们知道但是编译器不知道,所以包含 string 类成员的时候,我们必须定义自己的析构函数来恢复析构函数不抛出异常的承诺(继承 logic_error 的情况)。
- **异常说明与虚函数:**派生类中对应虚函数的异常说明可以不同,但是要同样严格或者更加受限,保证用户使用基类指针时不会碰到说明以外的异常。
17.2 命名空间
17.2.1 命名空间的定义
- **定义:**以关键字 namespace 开始,后接命名空间的名字,不能以分号结束。可以在全局作用域或其他作用域内部定义,但不能在函数或类内部定义。
- **命名空间可以是不连续的:**使得接口和实现可以分离。
- **定义命名空间成员:**定义时可以使用和声明相同的格式,也可以像类成员函数的外部定义格式。
- **全局命名空间:**娟娟命名空间是隐式声明的,存在于每个程序中。但实验结果却不能直接使用,必须要包含头文件,这是为何?
- **嵌套命名空间:**使用方式:
MySpaceBase::MySpaceA::print(); - **未命名的命名空间:**不能跨文件使用;无需加前缀名字,直接使用;因此放在最外层时不能与全局变量同名;可取代文件中的静态声明(因为C++后续可能不支持静态声明)。
17.2.4 命名空间成员的使用
- using 声明: 就像声明一样。容易出现重复定义或重复声明。
- 命名空间别名:
namespace primer = cplusplus_primer;。一个命名空间可以有许多别名,所有别名以及原来的命名空间名字都可以互换使用。 - using 指示:
using namespace std;容易出现使用的二义性。 - 避免 using 指示: 由 using 声明引起的二义性错误在声明点而不是使用点检测,因此更容易发现和修正。
17.2.5 类、命名空间和作用域
- 类作用域中使用名字: 首先在成员本身中查找,然后再类中查找,包括任意基类,最后检查外围作用域。
- 函数调用时会包含声明形参类及其基类的命名空间:
- 重载与 using 声明: 如果命名空间内部的函数是重载的,那么,该函数名字的 using 声明声明了所有具有该名字的函数。

17.3 多重继承与虚继承
- 多重继承:
- 转换与多个基类:
- 私有继承: 如果中间夹有私有访问,尽管存在从派生类指针到基类指针的转换,但这些转换不可访问(构造函数不可访问)。
- **确定使用哪个虚析构函数:**假定所有析构函数适当定义为虚函数,那么无论通过哪种指针删除对象,虚析构函数的处理都是一致的:找到实际对象,构造函数次序的逆序调用析构函数。
- 多重继承派生类的复制控制:
- 名字查找:
- 多个基类可能导致二义性: 派生类通过指定使用哪个类解决二义性。
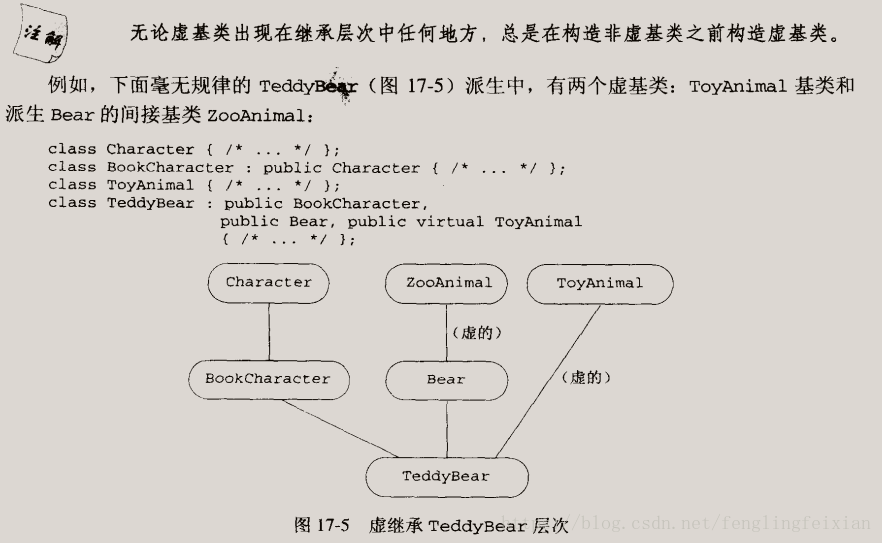
- 虚继承:
- 怎样构造虚继承的对象:
- 构造函数与析构函数次序: 主要说明不同子树之间。
- 总结: 正常来说:间接基类的初始化工作是由基类来完成,当出现虚基类的时候,才转移至派生类执行。
- 特殊的初始化语义: 在虚派生中,由最底层派生类的构造函数初始化虚基类(虚基类的基类则不行)。
- 疑问: 当派生类中包含两个基类的子对象时,指向派生类的基类指针操作的是哪一个子对象?(答:如果没有虚继承,则访问自己负责初始化的那部分;有虚继承的时候也一样,而且虚继承那部分必须放在前面,否则会报错,)
- 疑问: 这里的情况比较复杂,可以有很多继承方式,值得深入研究。
- 资源分配即初始化(RAII): 抛出异常时撤销函数内部定义的局部变量,这种撤销对象提供的这种重要的编程技术。
- 有趣疑问: 对于非虚继承的菱形继承关系,用栈内存分配的对象包含两个间接基类子对象,在使用时(
.)会有二义性。但有趣的是,使用堆内存分配对象会失败。






第18章 特殊工具与技术
18.1 优化内存分配
- 内存分配与对象构造分离开: 理由如下:在预先分配的内存中构造对象很浪费,可能会创建从不使用的对象;当实际使用预先分配的对象的时候被使用的对象必须重新赋以新值;更微妙的是,如果预先分配的内存必须被构造,某些类就不能使用它。
18.1.1 C++中的内存分配
- C++中的内存分配:


18.1.2 allocator 类
- 总结: 调用的是复制构造函数和析构函数。
18.1.3 operator new 函数和 operator delete 函数

总结
- 编译器优化:
A a = 1;理论上是先隐式(如果声明为 explicit 则无法编译)调用int类型的构造函数,初始化临时变量,然后再调用赋值操作符。但编译器有优化,直接只调用int类型的构造函数。A a = b;也是一样。