第一部分:与系统相关的sys模块
使用这个模块前先导入该模块(import sys),该模块有以下几个常用的点:
- 命令行参数(在命令执行程序时,向程序添加参数信息)
我们先创建这么一个叫脚本,功能是打印程序运行时sys.argv包含的信息:
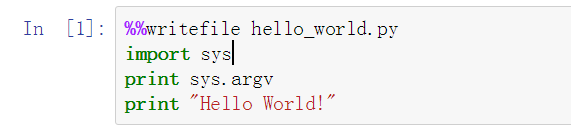
接着我们执行这个脚本:(第一个就是sys.argv的值,它是一个由命令行参数组成的列表,这里我们的命令行参数只有名字,故此它的值就是这个)

我们试着在执行脚本的过程中加入一些参数:(可以看出这个sys.argv是一个将命令行参数按照空格进行分开得到字符串列表,其中的123并没有解析成数字)

接着我们验证一下是不是符合这个规则:



如果想输出这个“zhang san ”,我们可以这样写避开它的空格字符检测:

但是如果这个sys.argv[1]不存在就会抛出异常:
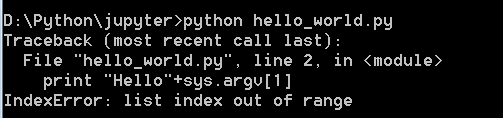
如果我们不想让异常抛出,可对脚本进行修改,使其符合条件输出条件,不符合则输出默认值:



- 异常消息
在抛出异常时,我们可以使用sys.exc_info()得到异常的具体信息:
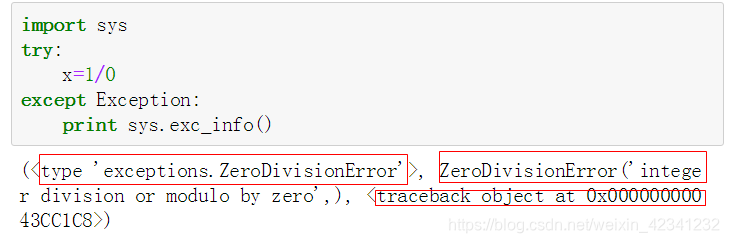
可以看出这个函数返回一个三元组(type、value、traceback),分别代表异常类型、异常值、回溯信息(即程序出错的具体位置) - 系统路径
使用变量sys.path查看Python搜索模块时的路径和查找顺序:
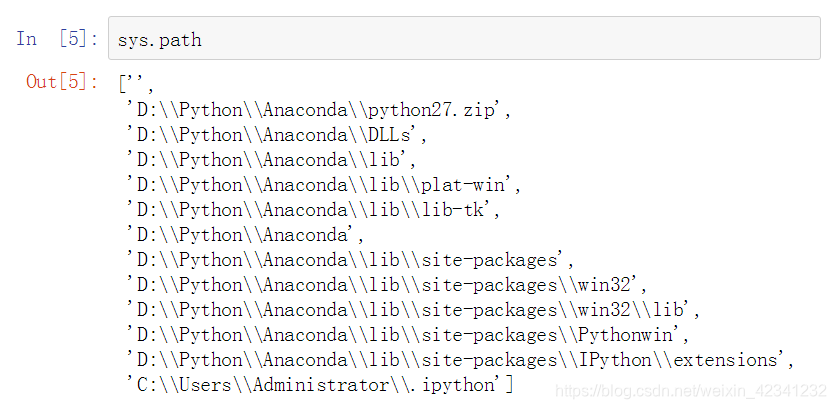
这个查找顺序是由我们导入的模块决定的,它会依次寻找相应的模块文件直到找不到为止,如果上述路径都找不到的话就会抛出异常,在上述图中’ '符号表示的是当前工作目录,是优先级最高的路径。 - 操作系统信息(使用sys.platform)

- python版本信息(使用sys.version)

第二部分:与操作系统进行交互的OS模块
该模块是与操作系统进行交互的标准模块,使用前导入os模块(import os)
- 文件相关操作
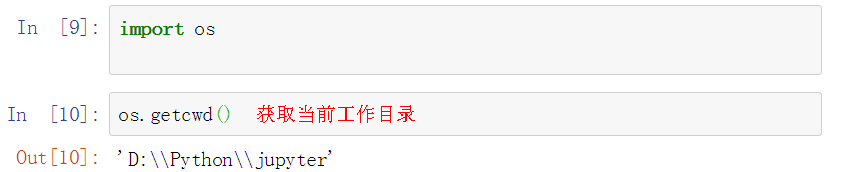

用os.listdir(’.’)获取当前工作目录下的所有文件夹以及子文件夹:

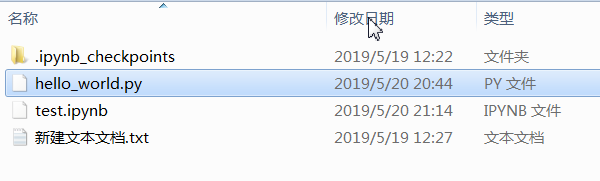
是故我们可以利用这个函数查看一个文件是否在文件夹中:


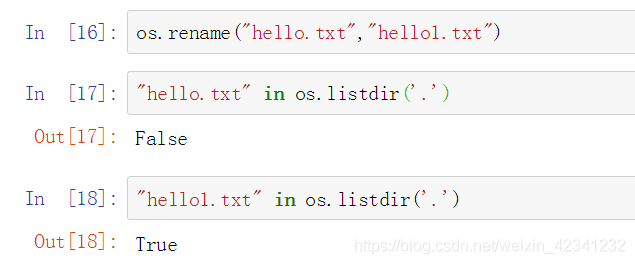
利用os.rename()函数来重命名一个文件名字:
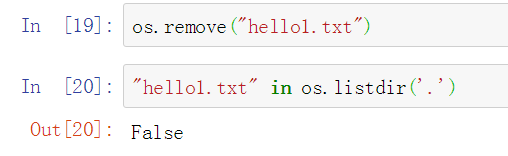
利用remove()函数来删除一个文件:
下面列举关于这个模块下与文件先关操作的函数: - os.getcwd()(获取当前工作目录)
- os.chdir(path)(改变当前工作目录)
- os.listdir(path)(列出指定目录下的文件和文件夹列表)
- os.remove(path)(删除文件)
- os.unlink(path)(删除文件)
- os.removedirs(path)(删除文件,并删除中间的路径中的空文件夹)
- os.rename(old,new)(重命名文件,该文件要存在,否则抛出异常)
- os.renames(old,new)(重命名文件,如果文件不存在则创建)
- os.mkdir(name)(产生新文件夹,如果文件夹不存在则抛出异常)
- os.makedirs(name)(产生新文件夹,如果文件夹不存在则创建)
以上函数使用前要记得导入os模块 - 系统相关变量
环境变量:(通过os.environ获取当前环境变量)

另外介绍一下Python为解决不同路径规范问题带来的麻烦问题,在
os模块下额外提供的os.path模块:
使用前导入(import os.path)

它其中包含很多和路径相关的功能,列举如下: - os.path.isfile(path)(判断路径是否为文件)
- os.path.isdir(path)(判断路径是否为文件夹)
- os.path.exists(path)(检测路径是否存在)
- os.path.isabs(path)(检测路径是否为绝对路径)
- os.path.split(path)(按照系统分隔符,将路径拆分为(head,tail)两部分)
- os.path.join(a,*p)(使用系统分隔符,将各个部分合并为一个路径)
上面这些函数就是为了解决不同系统之间差异带来的问题
第三部分:string模块
该模块是与字符串相关的标准模块,使用前导入模块(import string)

-
常用的字符串集合
-
英文标点字符串集合

-
英文字母表集合

-
小写字母表集合

-
大写字母表集合

-
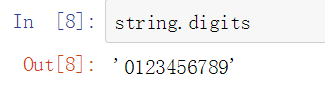
数字集合
-
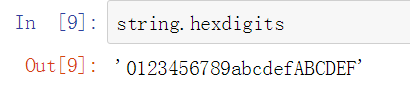
16进制数字集合
-
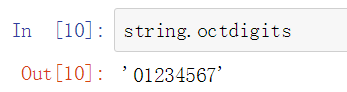
8进制数字集合
-
空白字符集合(分别是制表符、换行符、垂直制表符、换页符、回车符)

-
字符串函数(大部分已经给字符串本身的方法代替,剩下以下两个)
-
将单个字母的首字符大写

-
替换函数(string.maketrans(from,to),本质是将ASCII码中的参数from中的字符一次替换为参数to中对应的字符,故此它们两个的长度必须一致)

第四部分:正则表达式-re模块
正则表达式是一种强大的字符串匹配模式,通常使用单个字符串来描述,匹配一系列匹配某个语法规则的字符串。
常用的正则表达式如下表
| 表达式 | 匹配内容 |
|---|---|
| . | 匹配除了换行符之外的字符 |
| […] | 匹配在该集合中的任意字符,支持范围如a~z,0~9等 |
| (…) | 作为一个整体进行匹配 |
| \w | 匹配任意大小写字母或数字,相当于[a~z,A~Z,0~9] |
| \d | 匹配任意数字,相当于[0~9] |
| \s | 匹配任意空白符,相当于[\t\n\f\v\r] |
| | | 逻辑或,匹配前一个或后一个表达式,如ab|cd可以匹配ab或者cd |
| ^ | 逻辑非,表示后面字符的补,如^[ab]表示除了ab之外的任意字符 |
| \W | \w的补,匹配所有非字母或数字 |
| * | 匹配前面的字符0次到更多次,如a*b可以匹配b、ab、aab、aaab、aaaab |
| + | 匹配前面的字符1次或更多次,如a*b可以匹配ab、aab、aaab、aaaab |
| ? | 匹配前面的字符0次或1次,如a?b可以匹配b或ab |
| {m} | 匹配前面的字符m次,如a{5}匹配aaaaa |
| {m,} | 匹配前面的字符至少m次,如\d{5}匹配至少5位数字 |
| {m,n} | 匹配前面的字符至少m次,之多n次(包括m和n次) |
- re模块的使用
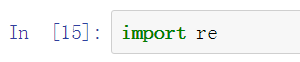
导入re模块:
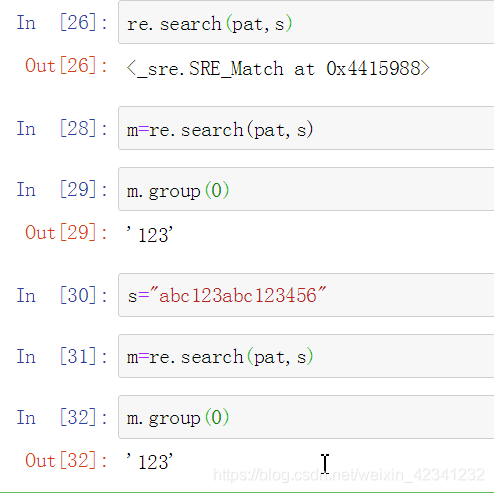
使用re.match()函数对字符串的开头进行匹配:


使用re.search()函数去匹配字符串中满足条件的第一次字串,返回它:
使用re.split()函数对字符串进行分割:


使用re.sub()函数对字符串中正则表达式匹配的部分进行替换:


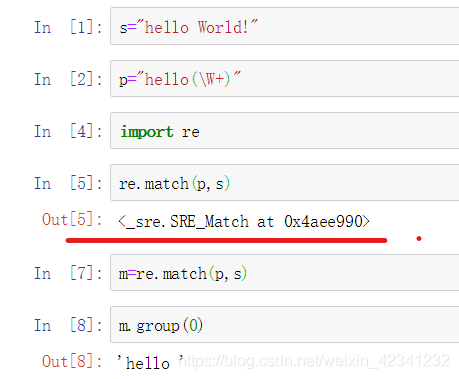
- 方法group()的使用
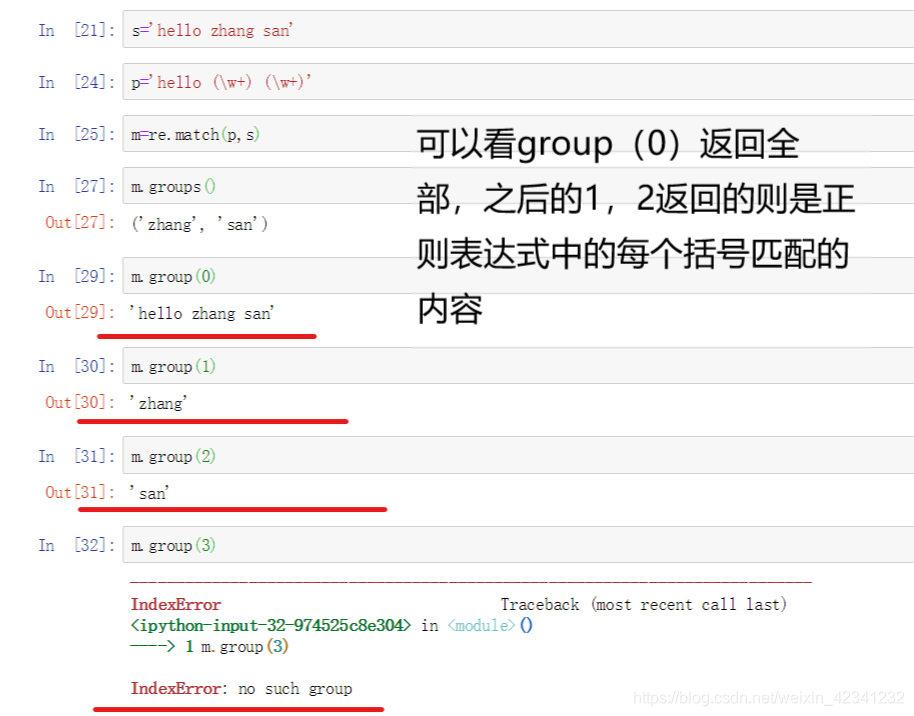
当正则表达式给匹配后,python不会直接返回匹配后的字符串,而是返回一个Math对象,此时我们就需要用group来得到
事实上,由于正则表达式中有括号,返回的math对象还可以调用方法group(1):
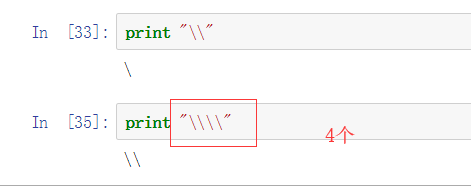
- 不转义的字符串
在python中,字符串本身对反斜杠也有转义作用
因为反斜杠同时也是Windows的默认路径的分隔符,所以路径也需要转义:

所以假如使用反斜杠来分割字符串的话就要这样写:

可以看出这样比较麻烦,所以python提供了不转义字符串来解决这个问题(方法很简单,只需要在不转义的字符串前面加一个r就行了):

第五部分:与时间相关的datetime模块
这个模块是用来处理时间和日期相关的,使用前导入这个模块:

- date对象(使用该对象生成一个年-月-日的信息对象):
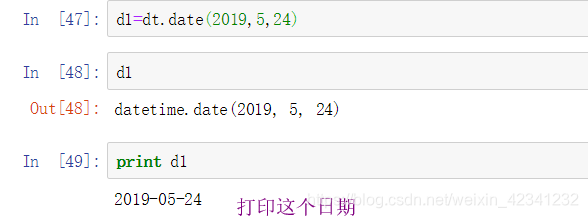
另外可以使用date的另一个strftime()方法将日期转化为特定的格式:

还可以使用today()方法得到系统时间:

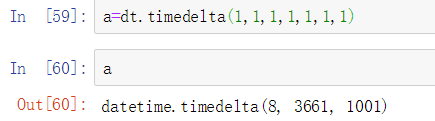
- timedelta对象

由此我们知道两个日期相减可以得到一个timedelta对象,所以我们可以使用timedelta(day,sec,ms,us,min,hr,wr)来构造一个时间间隔(不指定里面的参数的话,默认都是0)
- time对象
利用这个可以产生一个time对象
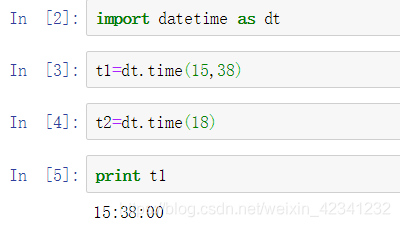
其中time(hour,min,sec,us),例如上面t1表示15点38分,不指定的参数默认是0,输出格式也同样可以用strftime()方法指定:

- datetime对象
可以用这个对象创建一个带有日期和时间的对象,用法为和参数为:
datetime(year,month,day,hr,min,sec,us)

同样的,也可以用这个对象获取当前的系统时间:
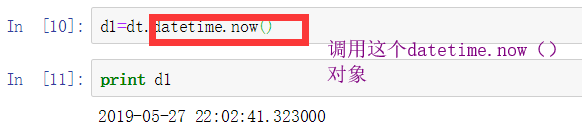
因为这个对象可以获取具体的时间,故而可以可date对象一样进行减法操作,同时还可以和timedelta对象进行加法操作:

第六部分:pprint模块
引入这个模块是为了打印出结构更加整齐和易于阅读,使用前导入该模块:
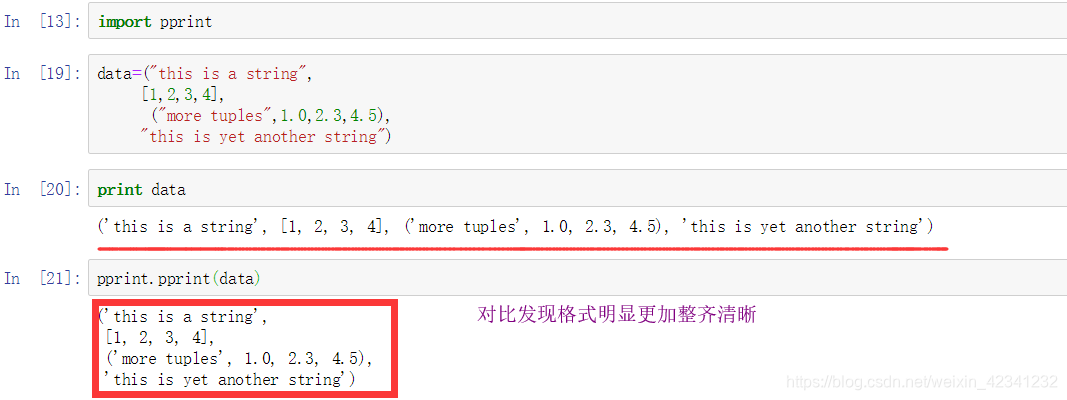
第七部分:序列化python对象中的pickle、Cpickle对象
pickle对象可以把python对象转化为一个字符串序列,同时也可以从这个序列中还原一个具有相同特征的python对象,而Cpickle因为是用C语言实现,所以速度要比pickle快:
使用前导入相应模块,优先导入Cpickle,没有再导入pickle:
- pickle的编码和解码(使用pickle.dumps()对象可以将一个对象转换成字符串)
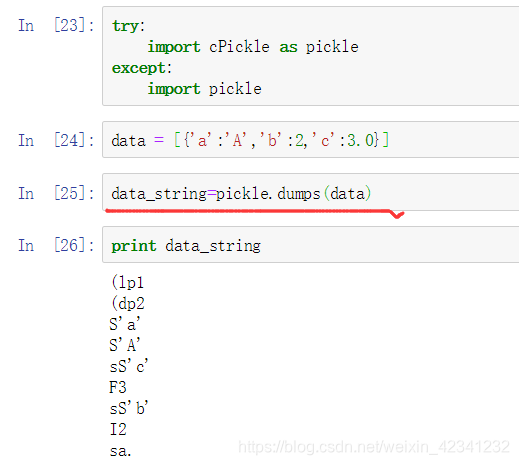
想在可以利用pickle.loads()方法将它恢复成原来的对象:

- pickle的编码方式(默认采用ASCII码)
我们可以修改参数来改变编码方式:
0:ASCII编码格式
1:旧的二进制编码格式
2:新的二进制编码格式
HIGHEST_PROTOCOL:查看当前最高级的编码
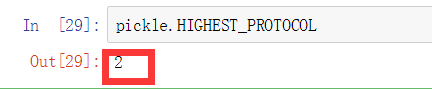

如果不知道最高级又不想查看,可以通过设置负数为参数:

利用pickle.loads()函数无需考虑编码方式,python自动转换:

- pickle文件的读写(简单的做法是保存到文件中)
用法如下:


使用pickle.load()从文件对象恢复这个对象:

需要注意的是这个pickle不太适合用于大的python对象,对于比较大的对象,pickle的读写速度较慢。
第八部分:读写JSON数据的json模块
json(javaScript Object Notation)是一种轻量级的数据交换格式,它既易于人们进行阅读和编写,也易于机器解析和生成
- json的格式
1:object-json对象,用花括号表示,形式为(其中数据是无序的):
{pair_1,…pair_n}
2:pair-json键值对,形式为:
string:value
3:array-json数组,用中括号表示,形式为(其中数据是有序的):
[value_1,…value_n]
4:value-josn值,可以是(object对象、string字符串、array数组、number数字、true/false/null特殊值)
5具体例子如下:

反过来,使用json.dumps()函数也可以将一个python对象转化为json字符串:

值得注意的是,python中的字典会转化为一个json对象,列表则是json数组,元组也是转化为数组,具体例子如下:

- json文件的读写
调用json.dump(obj,f)函数可以将对象以json格式保存到文件对象f中:
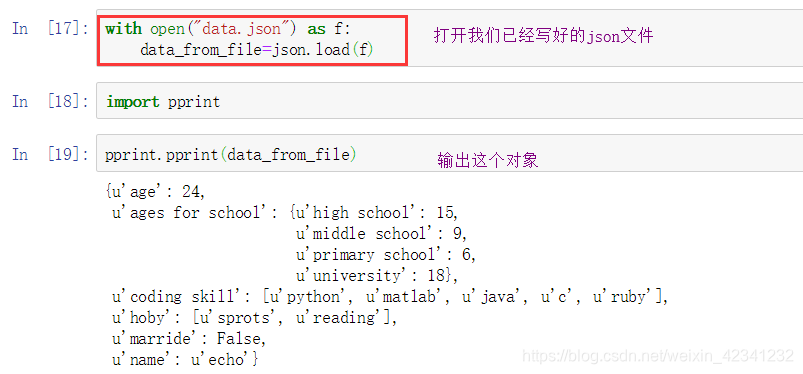
第九部分:文件模式匹配(glob模块)
使用前导入相应模块,这个模块提供了方便的文件匹配方法:

当前的工作目录如下:
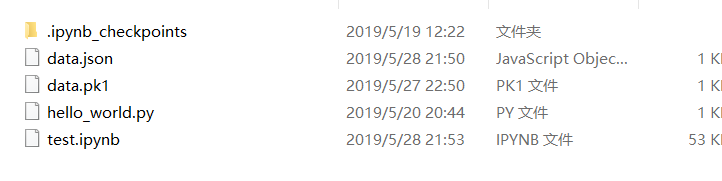
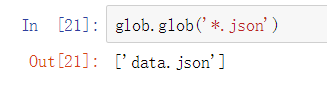
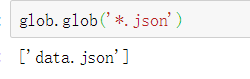
利用glob.glob()函数可以进行文件匹配,例如匹配这里json结尾的:
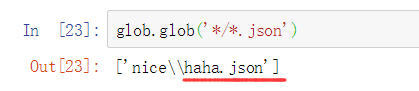
如果在下一级目录的话就应该这样匹配:
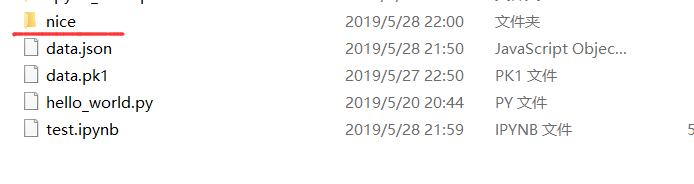
还是用第一种方法匹配:
发现没有改变,修改后匹配:
这样就匹配到我们新建的一个json文件了,这第一个*是匹配文件夹的,第二个是匹配文件的。其中:
*:匹配单个字符或多个,除了路径分隔符
?:匹配任意单个字符
[seq]:匹配指定范围内的单个字符,如:[0-9]匹配单个数字
[!seq]:这个就是非指定范围
第十部分:高级文件操作(shutil模块)
前面提到的os模块只能进行简单的文件删除和重命名等操作,对于更高级的文件操作还是要用到这个模块,使用前先导入这个模块:
- 文件的复制
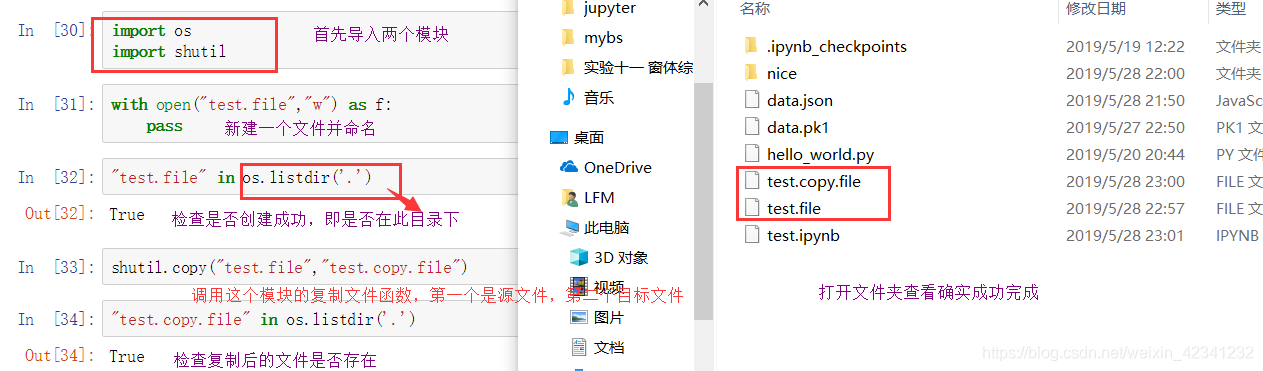
如果目标地址的文件夹不存在则会抛出异常:

- 文件夹的复制

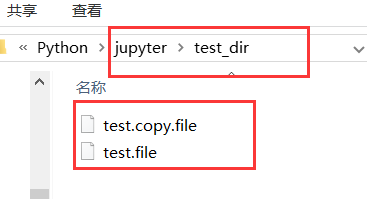
与os.rename不同的是这个os.renames遇到文件夹不存在的时候会自动创建。可以看出两个文件已经移动到这个新建的文件夹下面了,现在我们执行以下文件夹复制操作(文件夹不存在时自动创建):

- 非空文件夹的删除
利用os.removedirs()函数可以删除空文件夹:
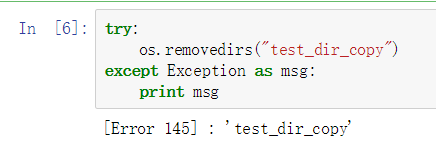
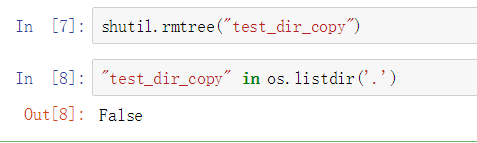
如果删除非空文件夹可以使用这个函数:shutil.rmtree():
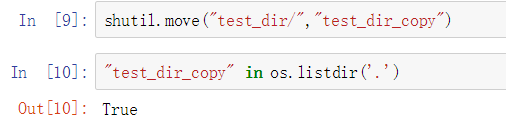
- 文件夹的移动
利用这个函数shutil.move()可以整体移动一个文件夹,它与os.renames()的作用是一样的,移动一个文件夹就是相当于对这个文件夹重命名
第十一部分:更多的容器类型(collection模块)
在前面我们已经知道了一般类型的容器类,例如字典、列表、集合等,这里引入这个模块可以提供更多的容器类,使用前导入该模块:
- 计数器
计数器有多种构造形式,如下所示:

例如我们可以实现一个统计一段文本中各个单词出现的次数:
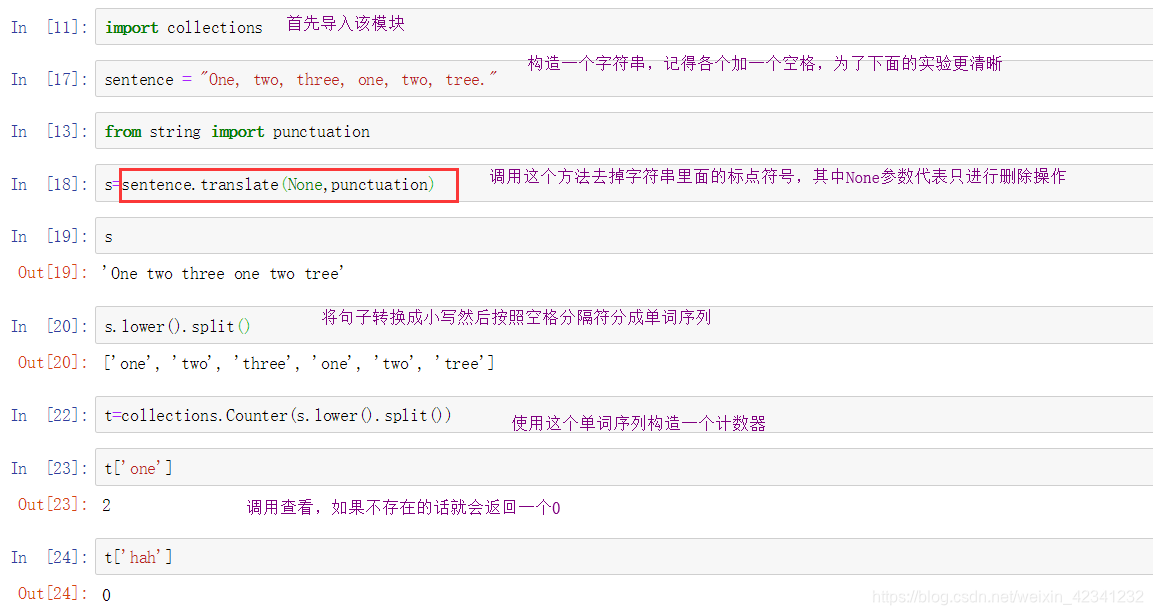
计数器和字典非常类似,因此也支持很多像是字典的操作:
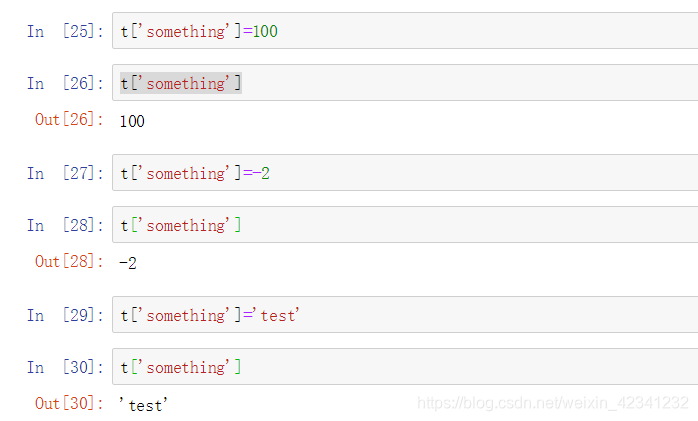
例如插入操作
还有删除操作:
和字典不同的操作如下:
1:

2:

3:(下面示例为减法、同时还有加法、取并、取交,但是除了减法以外的非正结果将会给忽略)


同时,对于一个计数器,常用的方法如下所示:

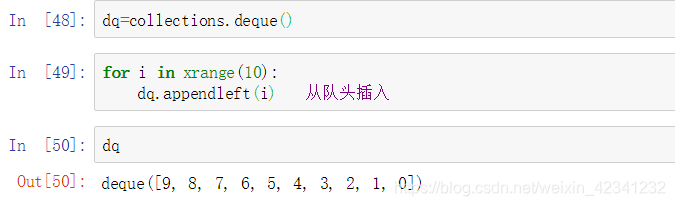
- 双端队列
双端队列支持将元素从对尾和头插入:

- 有序字典
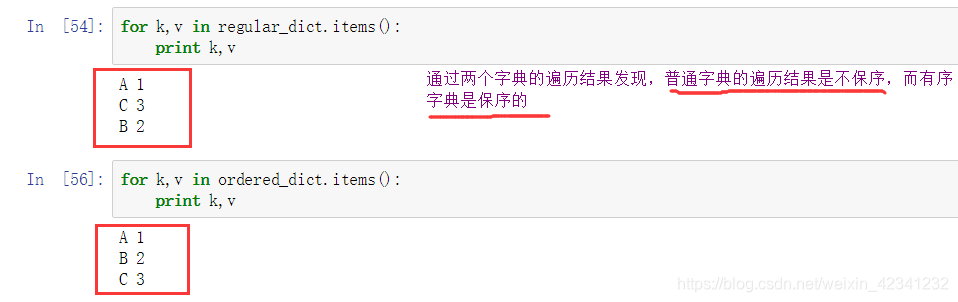
有序字典是指键按照顺序排列的字典,下面我们分别构建一个有序字典和普通字典:
普通字典:

有序字典:

我们现在对两个不同的字典遍历:
- 带默认值的字典
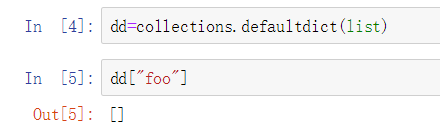
我们知道,对于普通的字典,当索引不存在的键时会抛出异常,这里我们使用带默认值的字典可以通过设置默认值来解决这个问题:
例如一个列表就返回一个空值:
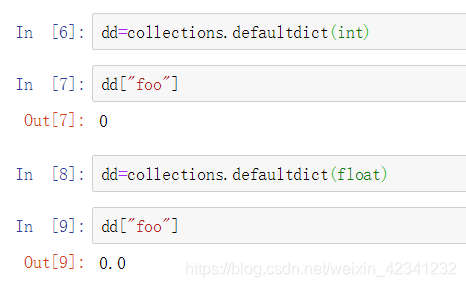
int和float就返回0和0.0:
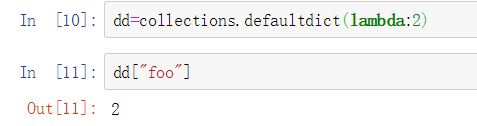
还可以使用Lambda表达式构造自定义函数:
这个是lambda表达式的百度百科
第十二部份:math模块
导入该模块可以提供数学计算:

下面介绍几种常用的数学函数:
1:计算平方根

2:圆周率

3:三角函数
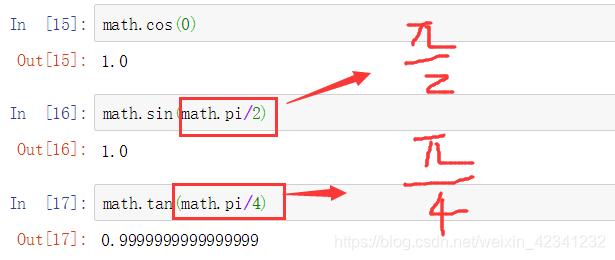
4:反三角函数
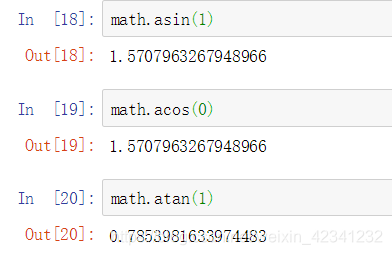
5:对数和指数
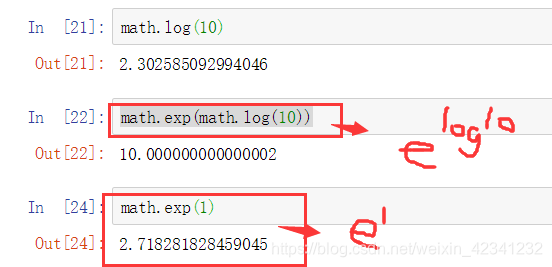
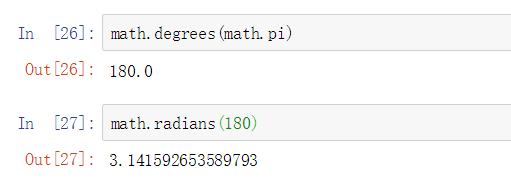
6:角度和度数之间的转化
第十三部份:random模块
这个模块是与随机数相关的,使用前导入该模块:

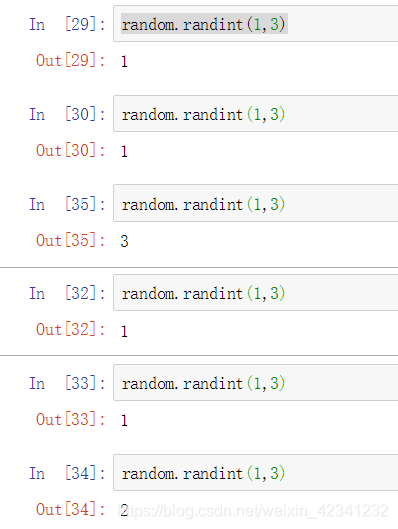
1:使用random.randint()可以产生一个随机整数(包括起始和结束位置的数字)
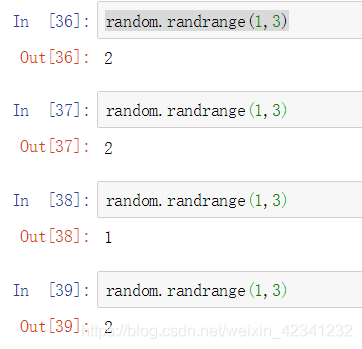
2:使用random.randrange([start,]stop[,step])也可以产生一个随机数,但是不包括stop,省略start和step时start默认是0,其中step不指定时默认是1:
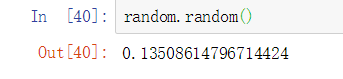
3:使用random.random()可以产生一个0-1之间的随机数:
4:使用random.choice()可以从一个序列中随机一个元素:
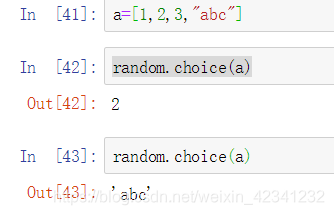
5:使用random.shuffle()可以将序列中的元素顺序打乱达到随机效果:

6:使用random.sample()可以不放回的随机采样元素,例如从0-9之间随机采样三个元素:

这章就写到这里了,python的标准库我感觉很大,这些估计只是表皮,还有最近忙着软考这个学习进度都放慢了很多,还有差不多又要实习了,然后java的学习还得跟进啊(手动悲伤~~)