以前用的商用talend开发,发布,TAC调度水到渠成,山回路转,来到了使用了开源的kettle新环境,瞬间有种从空调房搬到了电风扇集体宿舍的感觉,kettle这个不行,这个矬,那个慢,我就是自己写Java也不愿用kettle,能不能买个talend,一星期后,真香!废话结束,进入正题
Round 1: kettle导入数据慢
90万数据导入mysql,竟然耗时2个半小时还没跑完,我还对着mysql发了顿牢骚(mysql怎么这么矬,虽然发现mysql背锅了,其实发现mysql大有来头,后面要研究下,难怪有专门的mysql专家,后续再说吧),其实是jdbc的问题,在输入和输出的数据库连接选项中配置以下四个参数,可以从原来的几个小时,瞬间变成2分钟完成,如图1-1。
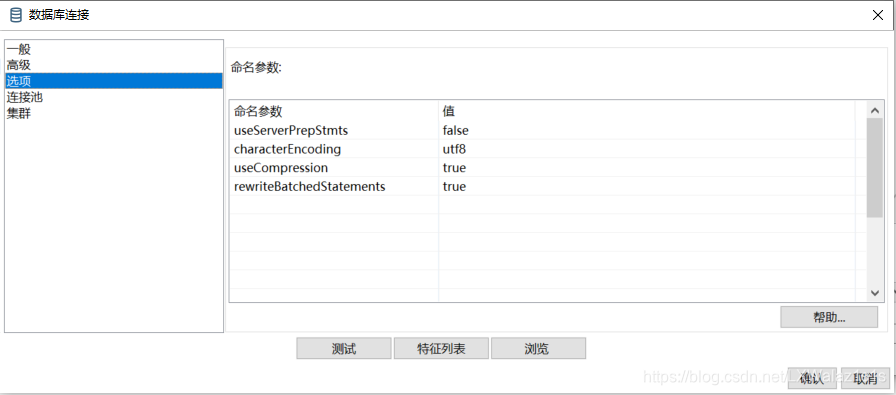
rewriteBatchedStatements true
useServerPrepStmts false
characterEncoding utf8
useCompression true
Round 2: 设置动态变量和获取动态变量
静态变量没啥好说的,直接写在命名参数上即可,设置动态变量一般是在一个作业的第一个转换内,因为设置的变量只能在之后的转换或者步骤中使用,即在转换A中设置了变量a,那a只能在A之后的步骤中起作用,在A本身是不起作用的哟(特别注意),选一个输出控件,这里以表输出为例,如图2-1,输入可以是从数据取出来的数据赋值给变量,注意结果只能为一行多列,多列可以设置多个变量,结果多行了会报错,原因很简单,自己想想就知道了,多行的可以用
"复制记录到结果"来装(循环再讲);
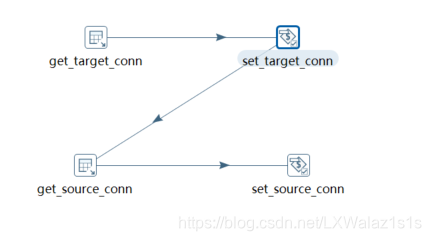
- 在该Job的控件里面使用,如图2-3,直接用${变量名}的形式引用;
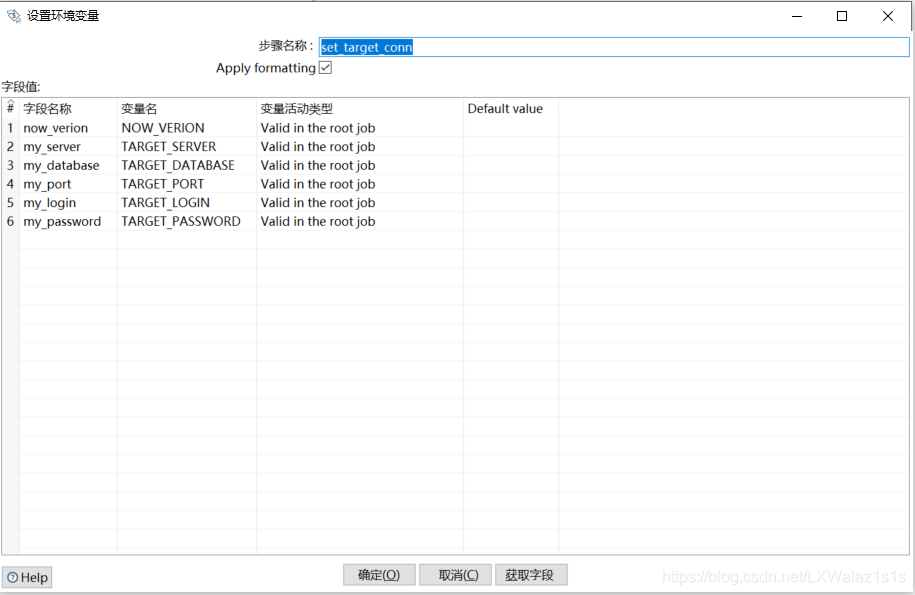
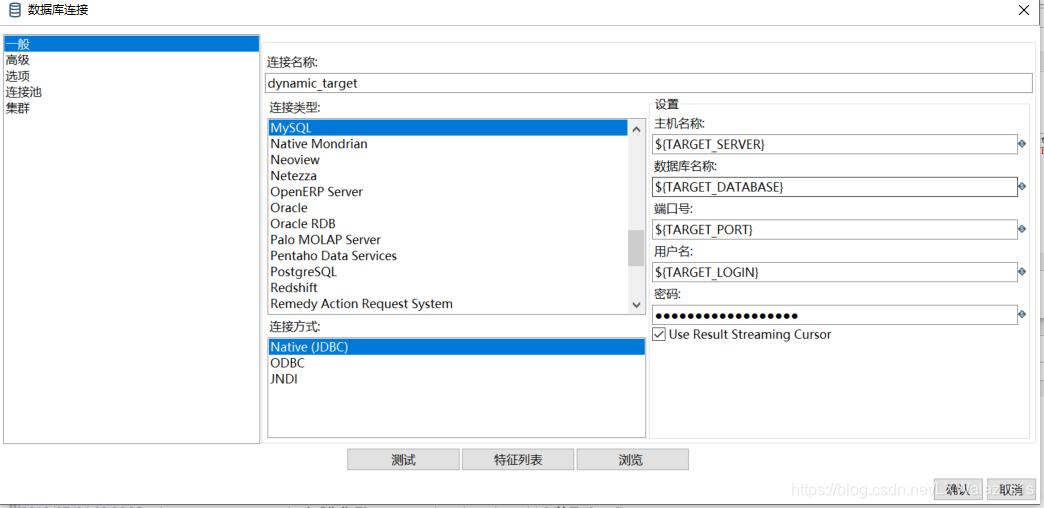
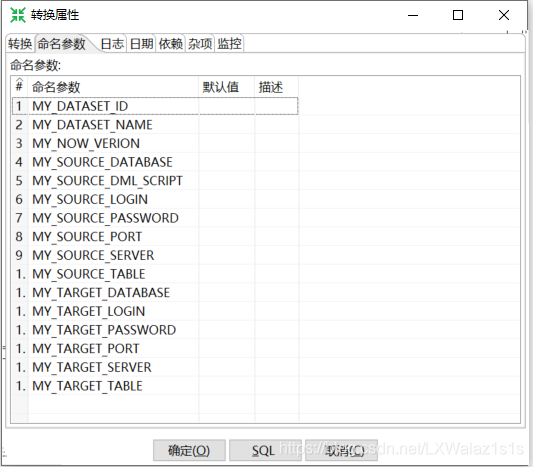
- 在下一个转换上使用,先打开转换,在转换里面的“转换设置”的“命名参数”,先把命名参数写出来,如图2-4,然后再作业层调用转换的时候,点到“命名参数”把变量值赋给命名参数,点击获取参数,把刚刚定义在转换里面的参数拿过来,然后再赋值变量,如图2-5,可以理解为命名参数为形参,变量值为实参
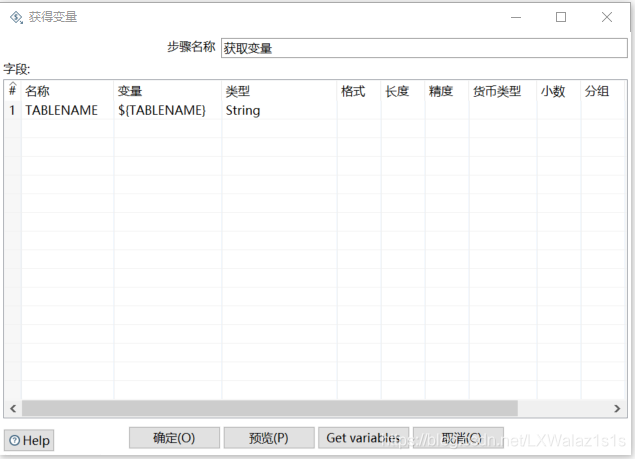
- 在转换内部直接获取变量,如图2-6,利用获取变量控件,直接把变量值作为形参赋值给新定义的变量;
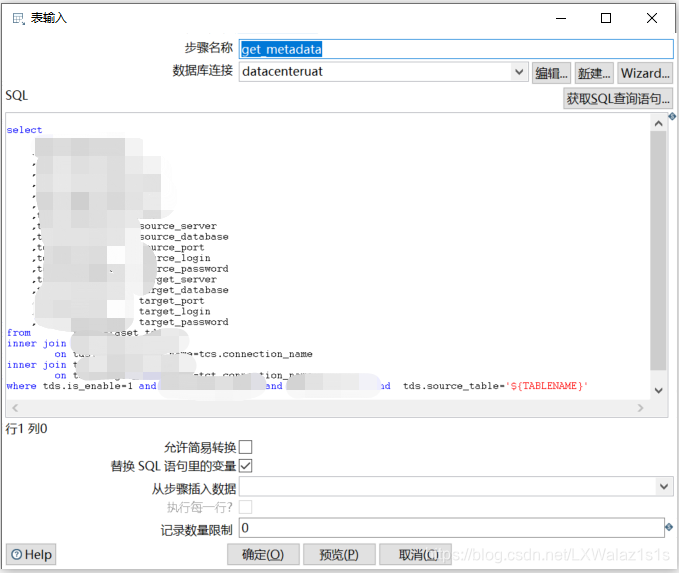
变量在表输入的话,如果是字符串,需要用’’,并且要勾选替换SQL语句里面的变量

Round 3: 实现循环以及JavaScript操控变量
循环有两种,一种是实现for(int i=0;i<10;i++),一种是实现foreach(int x:array)的,一种是转换内部的循环
- 实现类似for(int i=0;i<10;i++)
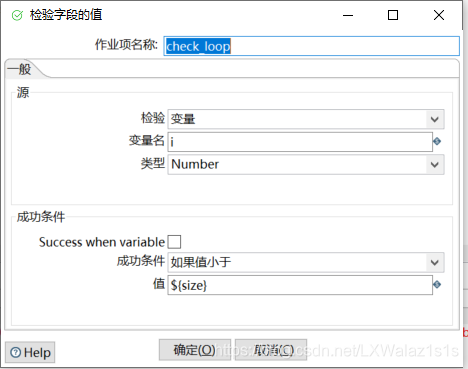
先是设置变量i=1,size=10,当然也可以惨开Round 2里面的动态设置变量,然后选用“检验字段的值”控件,如图3-1,检验选用变量,变量名写i,然后是成功条件和值写${size}。注意,变量涉及到’值’都是${变量名},如果让填写变量’名’,就可以直接写名字!
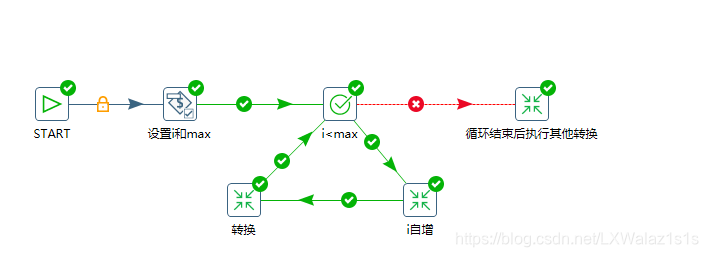
- 实现类似foreach(int x:array)遍历的循环
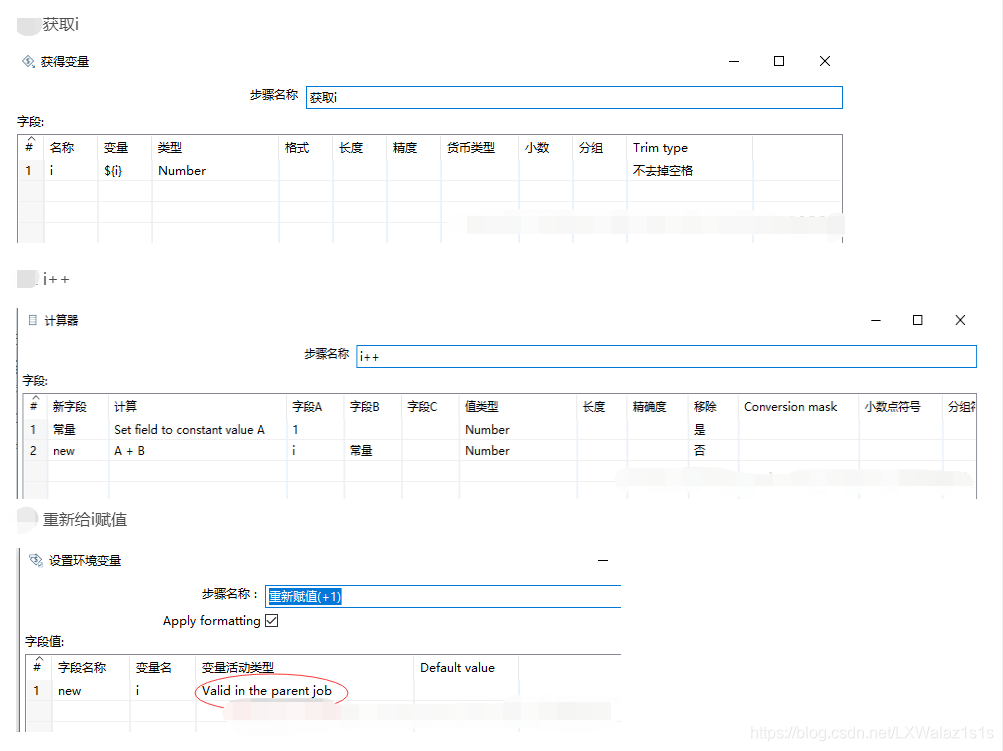
首先,生成这个数组,以表输入为例,输出结果为“复制记录到结果字符串”,如图3-4;然后用judge_and_set_variable(作业JavaScript控件,代码如下)来初始化变量;然后判别循环变量i,具体可参看图3-1;
//judge_and_set_variable
var prevRow=previous_result.getRows(); //获取上一步骤的结果,其实就是获取array
if(prevRow == null && (prevRow.size()=0))
{
false;
}
else
{
parent_job.setVariable("tables",prevRow);
parent_job.setVariable("size",prevRow.size()); //获取上一步结果数组长度赋值给变量size
parent_job.setVariable("i",0);//初始化变量i=0
parent_job.setVariable("TABLENAME",prevRow.get(0).getString("source_table",""));//获取数组array[0]的source_table赋值给变量"TABLENAME
true; //返回true不可少,少了节点之间的连接跑不下去
}
判别后面接循环体需要的操作,然后设置循环变量自增,也用"JavaScript"实现,具体代码如下;
var prevRow=previous_result.getRows(); //获取array
var size =new Number(parent_job.getVariable("size")); //获取变量size
var i =new Number(parent_job.getVariable("i"))+1; //获取变量i=i+1
if(i<size)
{
parent_job.setVariable("TABLENAME",prevRow.get(i).getString("source_table",""));//遍历array[i]
}
parent_job.setVariable("i",i);//重置变量i
true;//返回true不可少,少了节点之间的连接跑不下去
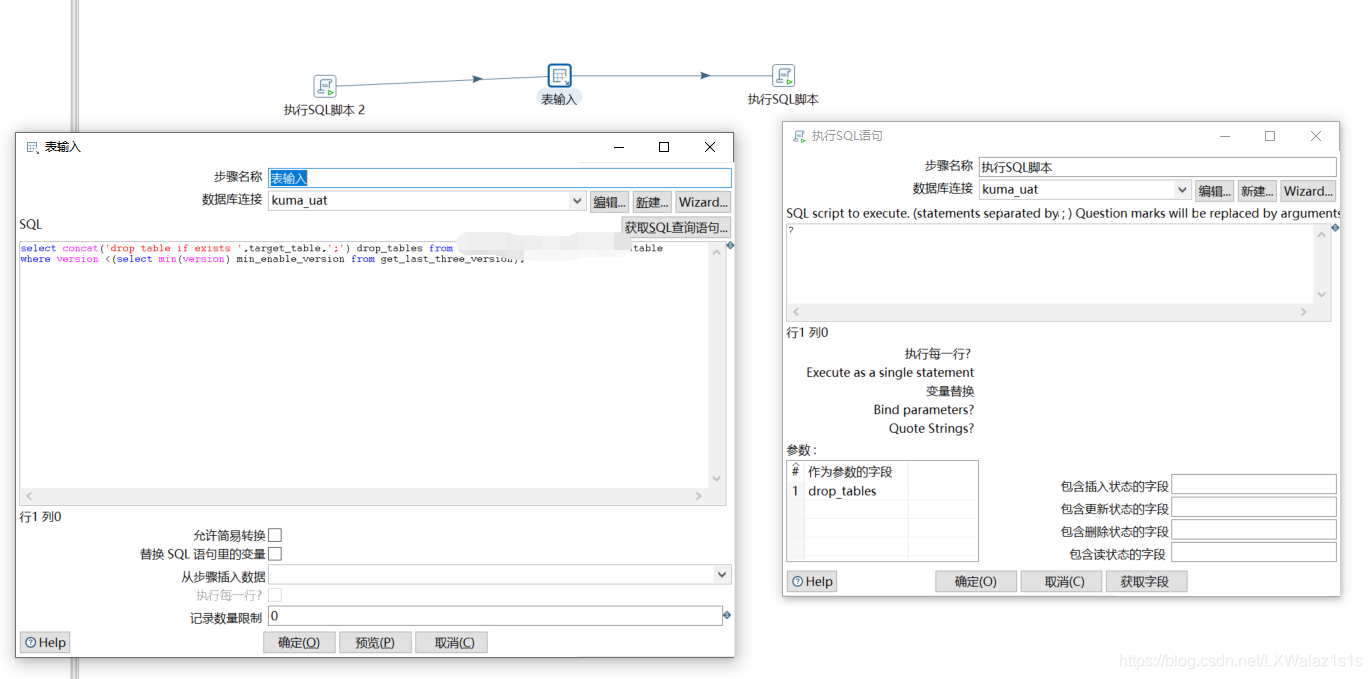
Round 4: 利用Java代码随心所欲的操控转换
Java代码是夹杂在输入,输出之间的,如把sql脚本文件的内容读取出来,赋值给一个变量,再把变量给到表输入,这样可以实现只存文件路径的做法;总体框架如图4-1;
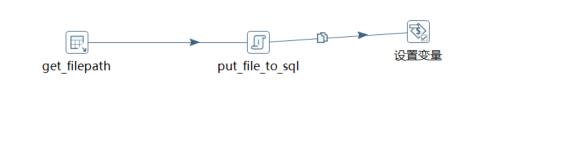
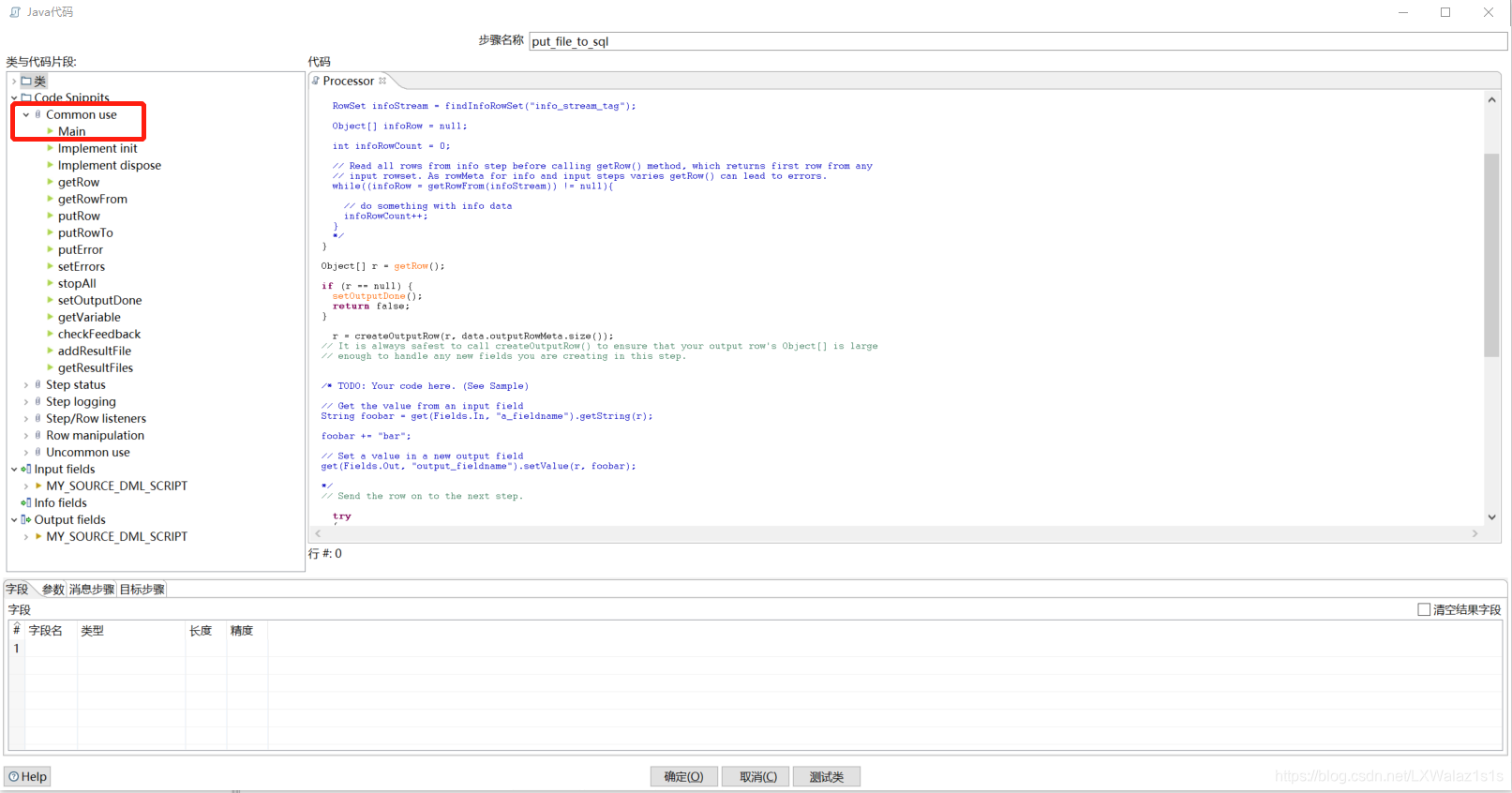
注意:图4-1中,Input fields来源于输入的字段,Output fields是要输出给到输出端接收的,input和output的字段列数一样的时候,下方的字段不需要写任何东西,留空即可,如果Java代码操作后,有新的变量要输出,就要在下方写好字段名和类型,传给输出端。
import java.io.*;
String lineTxt = null,alltxt="";
public boolean processRow(StepMetaInterface smi, StepDataInterface sdi) throws KettleException {
if (first) {
first = false;
/* TODO: Your code here. (Using info fields)
FieldHelper infoField = get(Fields.Info, "info_field_name");
RowSet infoStream = findInfoRowSet("info_stream_tag");
Object[] infoRow = null;
int infoRowCount = 0;
// Read all rows from info step before calling getRow() method, which returns first row from any
// input rowset. As rowMeta for info and input steps varies getRow() can lead to errors.
while((infoRow = getRowFrom(infoStream)) != null){
// do something with info data
infoRowCount++;
}
*/
}
Object[] r = getRow();
if (r == null) {
setOutputDone();
return false;
}
r = createOutputRow(r, data.outputRowMeta.size());
// It is always safest to call createOutputRow() to ensure that your output row's Object[] is large
// enough to handle any new fields you are creating in this step.
/* TODO: Your code here. (See Sample)
// Get the value from an input field
String foobar = get(Fields.In, "a_fieldname").getString(r);
foobar += "bar";
// Set a value in a new output field
get(Fields.Out, "output_fieldname").setValue(r, foobar);
*/
// Send the row on to the next step.
try
{
String myfilepath = get(Fields.In, "MY_SOURCE_DML_SCRIPT").getString(r); //MY_SOURCE_DML_SCRIPT存的是文件路径
File file = new File(myfilepath);
if(file.isFile() && file.exists())
{
InputStreamReader isr = new InputStreamReader(new FileInputStream(file), "utf-8");
BufferedReader br = new BufferedReader(isr);
while ((lineTxt = br.readLine()) != null)
{
alltxt+=lineTxt+'\n'; //读取文件内容到alltxt
}
//br.close();
}
else
{
System.out.println("文件不存在!");
}
}
catch (Exception e)
{
System.out.println("文件读取错误!");
}
get(Fields.Out, "MY_SOURCE_DML_SCRIPT").setValue(r, alltxt); //把alltxt赋值回到MY_SOURCE_DML_SCRIPT
//如果有多个变量,可以写多行
//get(Fields.Out, "MY_SOURCE_DML_SCRIPT2").setValue(r, alltxt2); //把alltxt赋值回到MY_SOURCE_DML_SCRIPT
putRow(data.outputRowMeta, r);
return true;
}
以上是几个常用又比较繁琐的kettle操作小结,下一篇总结下关于Jinkens服务+GitLab实现自动化版本上线发布的操作,会以调用kettle作业或转换CICD为例。