对于分布式数据库来说,QUERY的运行效率取决于最慢的那个节点。

当数据出现倾斜时,某些节点的运算量可能比其他节点大。除了带来运行慢的问题,还有其他的问题,例如导致OOM,或者DISK FULL等问题。
如何监控倾斜
1、监控数据库级别倾斜
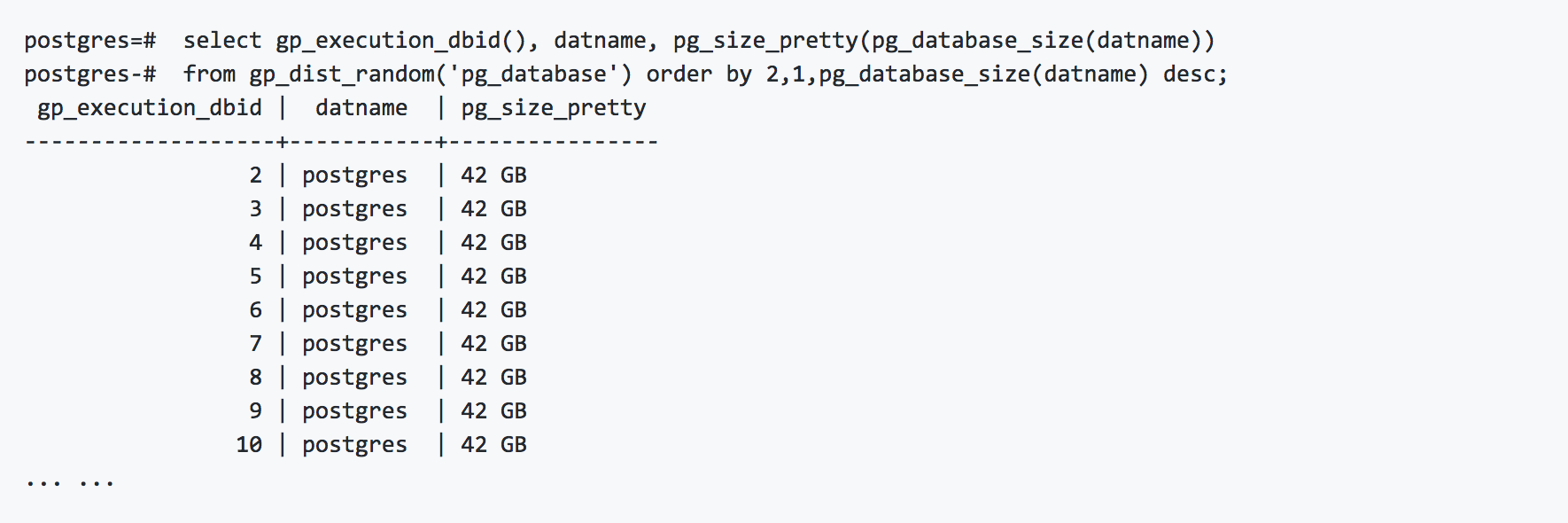
2、监控表级倾斜

出现数据倾斜的原因和解决办法
1.分布键选择不正确,导致数据存储分布不均。
例如选择的字段某些值特别多,由于数据是按分布键VALUE的HASH进行分布的,导致这些值所在的SEGMENT的数据可能比而其他SEGMENT多很多。
分布键的选择详见:
《Greenplum 最佳实践 - 数据分布黄金法则 - 分布列与分区的选择》
2.查询导致的数据重分布,数据重分布后,数据不均。
例如group by的字段不是分布键,那么运算时就需要重分布数据。
解决办法1:
由于查询带来的数据倾斜的可能性非常大,所以Greenplum在内核层面做了优化,做法是: 先在segment本地聚合产生少量记录,将聚合结果再次重分布,重分布后再次在segment聚合,最后将结果发到master节点, 有必要的话在master节点调用聚合函数的final func(已经是很少的记录数和运算量)。
例子:
tblaocol表是c1的分布键,但是我们group by使用了c398字段,因此看看它是怎么做的呢?请看执行计划的解释。
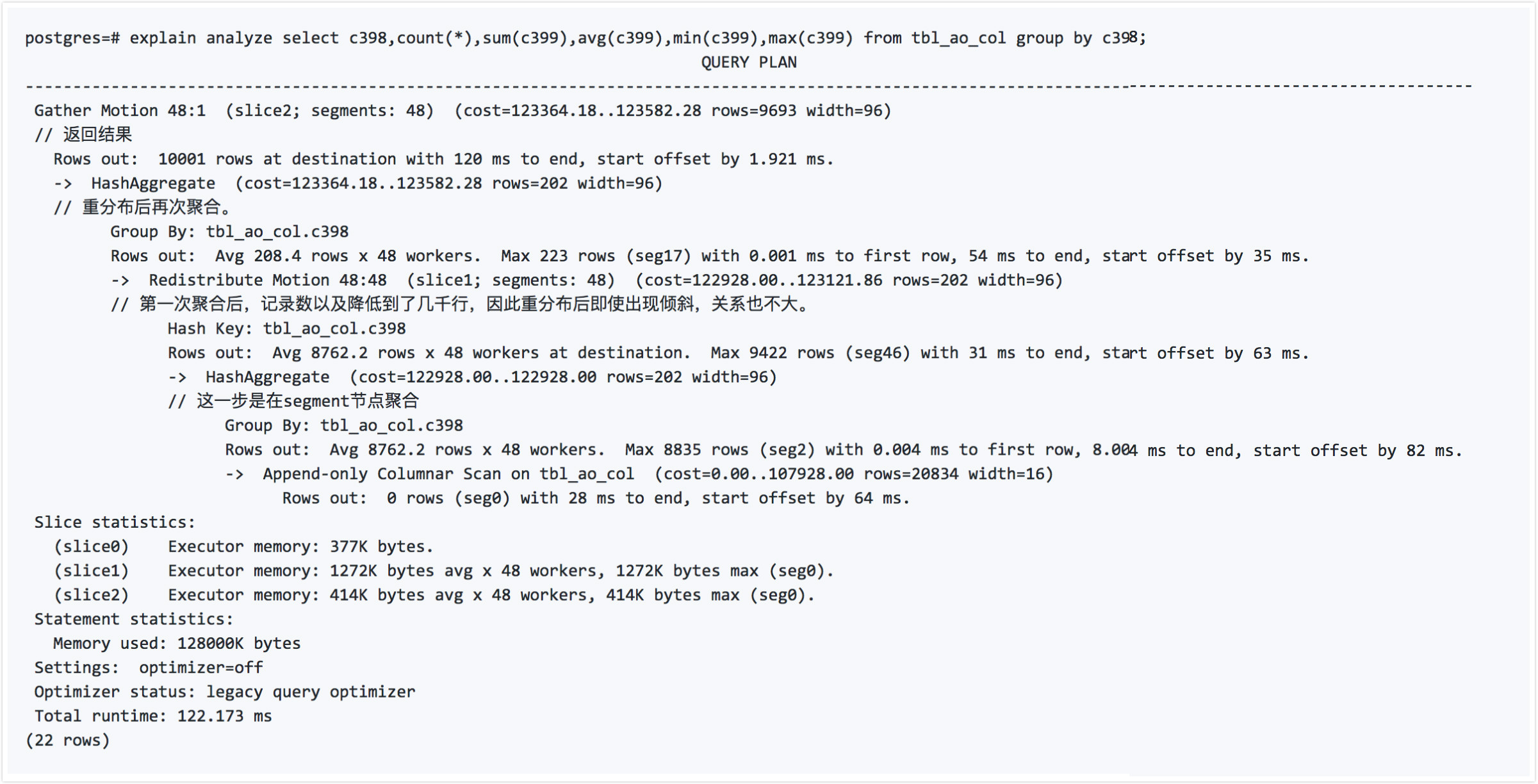
对于非分布键的分组聚合请求,Greenplum采用了多阶段聚合如下:
- 第一阶段,在SEGMENT本地聚合。(需要扫描所有数据,这里不同存储,前面的列和后面的列的差别就体现出来了,行存储的deform开销, 在对后面的列进行统计时性能影响很明显。)
- 第二阶段,根据分组字段,将结果数据重分布。(重分布需要用到的字段,此时结果很小。)
- 第三阶段,再次在SEGMENT本地聚合。(需要对重分布后的数据进行聚合。)
- 第四阶段,返回结果给master,有必要的话master节点调用聚合函数的final func(已经是很少的记录数和运算量)。
3.内核只能解决一部分查询引入的数据重分布倾斜问题,还有一部分问题内核没法解决。例如窗口查询。
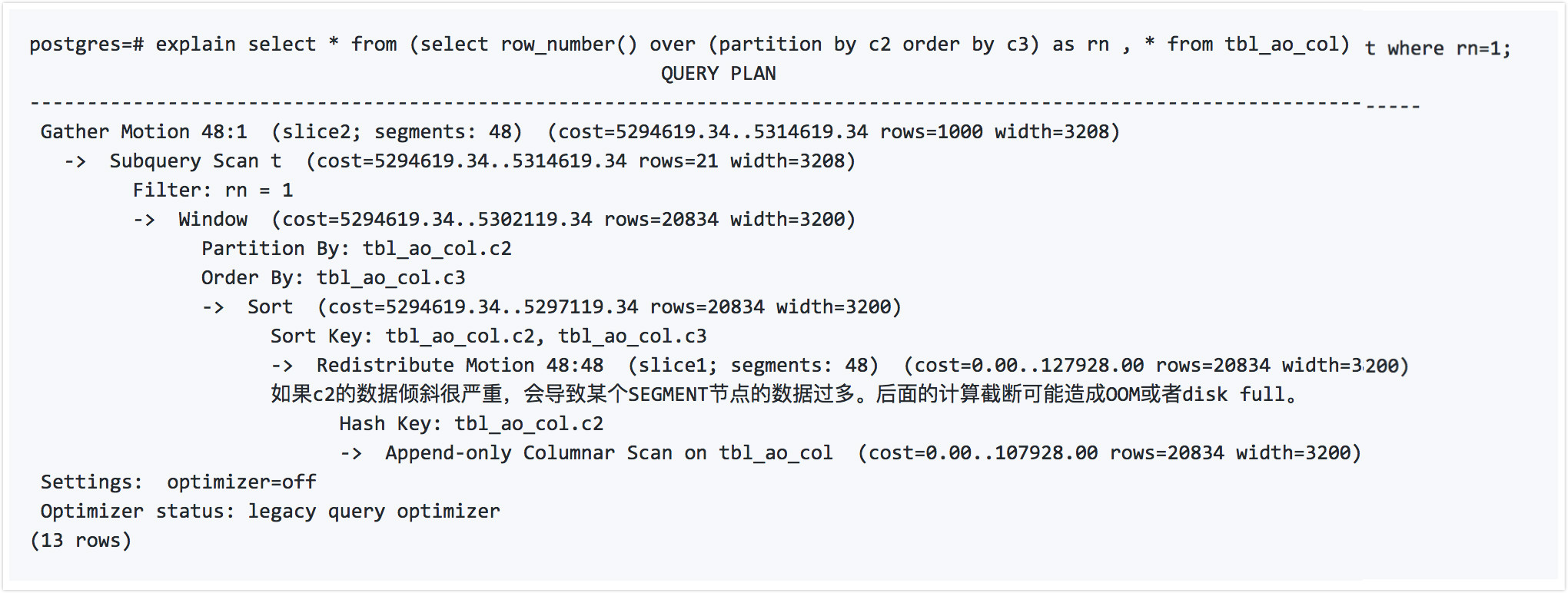
使用窗口函数时,Greenplum需要先按窗口中的分组对数据进行重分布,这一次重分布就可能导致严重的倾斜。实际上内核层优化才是最好的解决办法,例如以上窗口函数,由于我们只需要取c2分组中c3最小的一条记录。因此也可以在每个节点先取得一条,再重分布,再算。
不通过修改内核,还有什么方法呢?
3.1 Mapreduce任务就很好解决,Greenplum的mapreduce接口调用方法如下:
http://greenplum.org/docs/refguide/yamlspec.html
3.2 通过写PL函数也能解决。例如

小结
数据倾斜的原因可能是数据存储的倾斜,QUERY执行过程中数据重分布的倾斜。
数据倾斜可能引入以下后果:
- 计算短板
- oom
- disk full
数据倾斜的解决办法:
- 如果是存储的倾斜,通过调整更加均匀的分布键来解决。(也可以选择使用随机分布,或者使用多列作为分布键)。
- 如果是QUERY造成的倾斜,Greenplum内核对group by已经做了优化,即使分组字段不是分布键,通过多阶段聚合,可以消除影响。
- 如果是窗口函数QUERY造成的倾斜,目前内核没有对这部分优化,首先会对窗口函数的分组字段所有数据进行重分布,如果这个分组字段数据有严重倾斜,那么会造成重分布后的某些节点数据量过大。解决办法有mapreduce或pl函数。
参考
《Greenplum 内存与负载管理最佳实践》
《Greenplum 最佳实践 - 数据分布黄金法则 - 分布列与分区的选择》