一、何为并发
刚开始接触计算机编程语言时,我们编写一个程序,在main入口函数中调用其它的函数,计算机按我们设定的调用逻辑来执行指令获得结果。如果我们想在程序中完成多个任务,可以将每个任务实现为一个函数然后根据业务逻辑逐个调用。但如果我们想让多个任务几乎同时执行(时间间隔很小,我们感觉是同时执行的一样),比如一边放歌一边显示歌词,恐怕实现起来就会有明显的顿挫感(比如先播放一句歌声,然后显示一行歌词),影响交互体验。
随着我们对计算性能的要求越来越高,多核心处理器很快普及流行。如果我们想让自己开发的程序更高效的运行,自然要充分发挥多核心处理器的优势。在多核心处理器上同时运行多个任务,比在单核心处理器上顺序执行多个任务高效的多。像单片机这种单核心处理器,在任务较多或者多个任务需要几乎同时执行时,也需要应用多任务并发编程提高对包括处理器在内的各硬件资源的利用效率。
1.1 并发与并行
说了这么多,那什么是并发呢?简单来说,并发指的是两个或多个独立的活动在同一时段内发生。并发在生活中随处可见:比如在跑步的时候同时听音乐,在看电脑显示器的同时敲击键盘等。
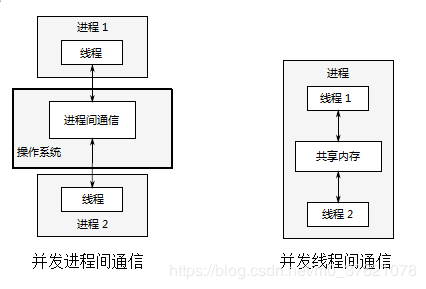
与并发相近的另一个概念是并行。它们两者存在很大的差别,图示如下:
并发:同一时间段内可以交替处理多个操作,强调同一时段内交替发生。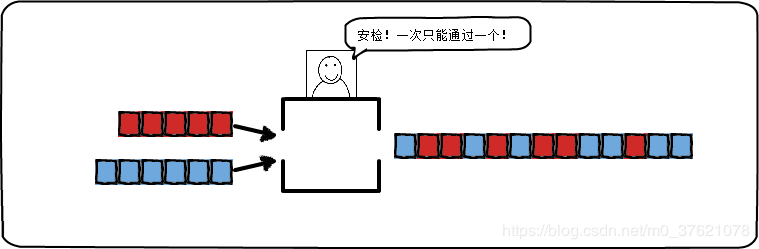
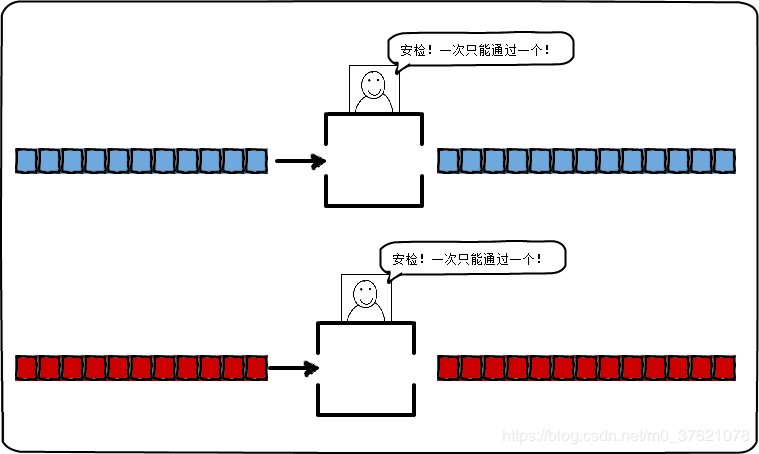
- 并行:同一时刻内同时处理多个操作,强调同一时刻点同时发生。
1.2 硬件并发与任务切换
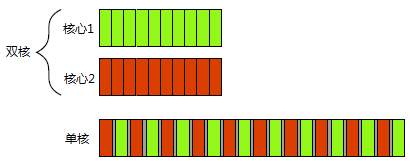
既然并发是在同一时间段内交替发生即可,不要求同时发生,像单片机上的单核处理器也是可以支持并发多任务处理的,所以有单片机上跑的RTOS(Real-time operating system)诞生。单核心处理器上的多任务并发是靠任务切换实现的,跟多核处理器上的并行多任务处理还是有较大区别的,但对处理器的使用和多任务调度工作主要由操作系统完成了,所以我们在两者之间编写应用程序区别倒是不大。下面再贴个直观的图示:
双核处理器并行执行(硬件并发)对比单核处理器并发执行(任务上下文切换)
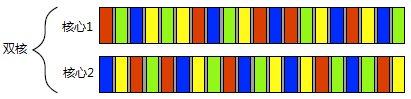
双核处理器均并发执行(一般任务数远大于处理器核心数,多核并发更常见)

1.3 多线程并发与多进程并发
前面一直在聊多任务并发,但计算机术语中用得更多的是线程与进程,三者的主要区别如下:
任务:从我们认知角度抽象出来的一个概念,放到计算机上主要指由软件完成的一个活动。一个任务既可以是一个进程,也可以是一个线程。简而言之,它指的是一系列共同达到某一目的的操作。例如,读取数据并将数据放入内存中。这个任务可以作为一个进程来实现,也可以作为一个线程(或作为一个中断任务)来实现。
进程:资源分配的基本单位,也可能作为调度运行的单位。可以把一个进程看成是一个独立的程序,在内存中有其完备的数据空间和代码空间。一个进程所拥有的数据和变量只属于它自己。例如,用户运行自己的程序,系统就创建一个进程,并为它分配资源,包括各种表格、内存空间、磁盘空间、I/O设备等。然后,把该进程放人进程的就绪队列。进程调度程序选中它,为它分配CPU以及其它有关资源,该进程才真正运行。所以,进程是系统中的并发执行的单位。
线程:执行处理器调度的基本单位。一个进程由一个或多个线程构成,各线程共享相同的代码和全局数据,但各有其自己的堆栈。由于堆栈是每个线程一个,所以局部变量对每一线程来说是私有的。由于所有线程共享同样的代码和全局数据,它们比进程更紧密,比单独的进程间更趋向于相互作用,线程间的相互作用更容易些,因为它们本身就有某些供通信用的共享内存:进程的全局数据。
由上面的定义可以看出,一个进程和一个线程最显著的区别是:线程有自己的全局数据。线程存在于进程中,因此一个进程的全局变量由所有的线程共享。由于线程共享同样的系统区域,操作系统分配给一个进程的资源对该进程的所有线程都是可用的,正如全局数据可供所有线程使用一样。
在Mac、Windows NT等采用微内核结构的操作系统中,进程的功能发生了变化:它只是资源分配的单位,而不再是调度运行的单位。在微内核系统中,真正调度运行的基本单位是线程。因此,实现并发功能的单位是线程。在Linux系统中,线程的实现和进程并不特别区分,线程只不过是一种特殊的进程。多进程并发编程与多线程并发编程的区别主要在有没有共享数据,多进程间的通信较复杂且代价较大,主要的进程间通信渠道有管道、信号、文件、套接字等。由于C++没有提供进程间通信的原生支持,后续主要介绍多线程并发编程,和多线程间的同步与通信。

二、如何使用并发
2.1 为什么使用并发
在应用程序中使用并发的原因主要有两个:关注点分离和性能。事实上,我甚至可以说它们差不多是使用并发的唯一原因;当你观察的足够仔细时,一切其他因素都可以归结到这两者之一(或者可能是二者兼有)。
关注点分离:通过将相关的代码放在一起并将无关的代码分开,可以使你的程序更容易理解和测试,从而减少出错的可能性。你可以使用并发来分隔不同的功能区域,即使在这些不同功能区域的操作需要在同一时刻发生的情况下;若不显式地使用并发,你要么被迫编写任务切换框架,要么在操作中主动地调用不相关的一段代码。
更高效的性能:为了充分发挥多核心处理器的优势,使用并发将单个任务分成几部分且各自并行运行,从而降低总运行时间。根据任务分割方式的不同,又可以将其分为两大类:一类是对同样的数据应用不同的处理算法(任务并行);另一类是用同样的处理算法共同处理数据的几部分(数据并行)。
知道何时不使用并发与知道何时使用它一样重要。基本上,不使用并发的唯一原因就是在收益比不上成本的时候。使用并发的代码在很多情况下难以理解,因此编写和维护的多线程代码就有直接的脑力成本,同时额外的复杂性也可能导致更多的错误。除非潜在的性能增益足够大或关注点分离地足够清晰,能抵消确保其正确所需的额外的开发时间以及与维护多线程代码相关的额外成本,否则不要使用并发。
2.2 在C++中使用并发和多线程
在早期的C++标准中,比如1998 C++标准版不承认线程的存在,并且各种语言要素的操作效果都以顺序抽象机的形式编写。不仅如此,内存模型也没有被正式定义,所以对于1998 C++标准,你没办法在缺少编译器相关扩展的情况下编写多线程应用程序。如果在之前想使用多线程并发编程,可以借助编译器厂商提供的平台相关的扩展多线程支持API(比如POSIX C和Microsoft Windows API),但这种多线程支持对平台依赖度较高,导致可移植性较差。
为了解决平台相关多线程API使用上的问题,逐渐开发出了Boost、ACE等平台无关的多线程支持类库。直到C++11标准的发布,借鉴了很多Boost类库的经验,将多线程支持纳入C++标准库。C++11标准不仅提供了一个全新的线程感知内存模型,也包含了用于管理线程、保护共享数据、线程间同步操作以及低级原子操作的各个类。
对于C++整体以及包含低级工具的C++类——特别是在新版C++线程库里的那些,参与高性能计算的开发者常常关注的一点就是效率。如果你正寻求极致的性能,那么理解与直接使用底层的低级工具相比,使用高级工具所带来的实现成本,是很重要的。这个成本就是抽象惩罚(abstraction penalty)。标准C++线程库在设计时,就非常注重高效的性能,提供了足够的低级工具(比如原子操作库),以付出尽可能低的抽象惩罚。C++标准库也提供了更高级别的抽象和工具,它们使得编写多线程代码更简单和不易出错。有时候运用这些工具确实会带来性能成本,因为必须执行额外的代码。但是这种性能成本并不一定意味着更高的抽象惩罚;总体来看,这种性能成本并不比通过手工编写等效的函数而招致的成本更高,同时编译器可能会很好地内联大部分额外的代码。
三、C++线程创建
一个多线程C++程序是什么样子的?它看上去和其他所有C++程序一样,通常是变量、类以及函数的组合。唯一真正的区别在于某些函数可以并发运行,所以你需要确保共享数据的并发访问是安全的。当然,为了并发地运行函数,必须使用特定的函数以及对象来管理各个线程。
3.1 C++11新标准多线程支持库
< thread > :包含std::thread类以及std::this_thread命名空间。管理线程的函数和类的声明;
< atomic > :包含std::atomic和std::atomic_flag类,以及一套C风格的原子类型和与C兼容的原子操作的函数;
< mutex > :包含了与互斥量相关的类以及其他类型和函数;
< future > :包含两个Provider类(std::promise和std::package_task)和两个Future类(std::future和std::shared_future)以及相关的类型和函数;
< condition_variable > :包含与条件变量相关的类,包括std::condition_variable和std::condition_variable_any。
3.2 线程创建的简单示例
线程创建和管理的函数或类主要由< thread >库文件来提供,该库文件的主要操作如下:
由上表可知,通过std::thread t(f, args…)创建线程,可以给线程函数传递参数。通过join()函数关联并阻塞线程,等待该线程执行完毕后继续;通过detach()函数解除关联使线程可以与主线程并发执行,但若主线程执行完毕退出后,detach()接触关联的线程即便没有执行完毕,也将自动退出,有时可能这并非我们预期的结果,所以需要特别注意。下面给出一段线程管理的示例代码:
//thread1.cpp 创建线程,并观察线程的并发执行与阻塞等待 #include <iostream> #include <thread> #include <chrono> using namespace std; void thread_function(int n) { std::thread::id this_id = std::this_thread::get_id(); //获取线程ID for(int i = 0; i < 5; i++){ cout << "Child function thread " << this_id<< " running : " << i+1 << endl; std::this_thread::sleep_for(std::chrono::seconds(n)); //进程睡眠n秒 } } class Thread_functor { public: // functor行为类似函数,C++中的仿函数是通过在类中重载()运算符实现,使你可以像使用函数一样来创建类的对象 void operator()(int n) { std::thread::id this_id = std::this_thread::get_id(); for(int i = 0; i < 5; i++){ cout << "Child functor thread " << this_id << " running: " << i+1 << endl; std::this_thread::sleep_for(std::chrono::seconds(n)); //进程睡眠n秒 } } }; int main() { thread mythread1(thread_function, 1); // 传递初始函数作为线程的参数 if(mythread1.joinable()) //判断是否可以成功使用join()或者detach(),返回true则可以,返回false则不可以 mythread1.join(); // 使用join()函数阻塞主线程直至子线程执行完毕 Thread_functor thread_functor; //函数对象实例化一个对象 thread mythread2(thread_functor, 3); // 传递初始函数作为线程的参数 if(mythread2.joinable()) mythread2.detach(); // 使用detach()函数让子线程和主线程并行运行,主线程也不再等待子线程 auto thread_lambda = [](int n){ //lambda表达式格式:[capture list] (params list) mutable exception-> return type { function body } std::thread::id this_id = std::this_thread::get_id(); for(int i = 0; i < 5; i++) { cout << "Child lambda thread " << this_id << " running: " << i+1 << endl; std::this_thread::sleep_for(std::chrono::seconds(n)); //进程睡眠n秒 } }; thread mythread3(thread_lambda, 4); // 传递初始函数作为线程的参数 if(mythread3.joinable()) mythread3.join(); // 使用join()函数阻塞主线程直至子线程执行完毕 std::thread::id this_id = std::this_thread::get_id(); for(int i = 0; i < 5; i++){ cout << "Main thread " << this_id << " running: " << i+1 << endl; std::this_thread::sleep_for(std::chrono::seconds(1)); } getchar(); return 0; }
使用GCC编译为可执行程序的命令如下:
g++ -Wall -g -std=c++11 -pthread thread1.cpp -o thread1 //-Wall显示所有警告,-g输出调试信息,-std=c++11使用c++11标准编译,-pthread编译使用POSIX thread库文件
线程创建的参数是函数对象,函数对象不止是函数指针或成员函数指针,同时还包括函数对象(仿函数)与lambda表达式。上面的代码分别用三种函数对象创建了三个线程,其中第一个线程mythread1阻塞等待其执行完后继续往下执行,第二个线程mythread2不阻塞等待在后台与后面的第三个线程mythread3并发执行,第三个线程继续阻塞等待其完成后再继续往下执行主线程任务。
为了便于观察并发过程,对三个线程均用了睡眠延时this_thread::sleep_for(duration)函数,且延时时间作为参数传递给该函数。这里的参数是支持C++泛型模板的,STL标准容器类型(比如Array/Vector/Deque/List/Set/Map/String等)都可以作为参数传递,但这里的参数默认是以拷贝的方式传递参数的,当期望传入一个引用时,要使用std::ref进行转换。
针对任何线程(包括主线程),< thread > 还声明了一个命名空间std::this_thread,用以提高线程专属的全局函数。函数声明和效果见下表:
上面的代码就是利用了std::this_thread提供的函数获得当前线程的ID,让当前线程睡眠一段时间(一般需要< chrono >头文件提供duration或timepoint)的功能,代码执行结果如下图所示:
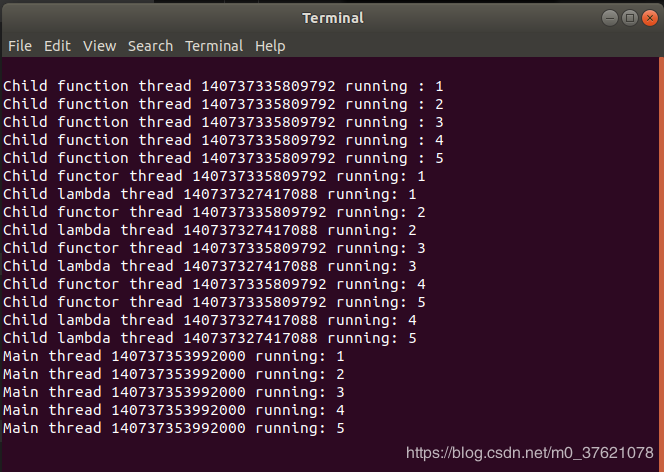
上面的示例假如多重复运行几次,有很大可能会出现某行与其他行交叠错乱的情况(如下图所示),为何会出现这种情况呢?这就涉及到多线程资源竞争的问题了,即一个线程对某一资源(这里指显示终端)的访问还未完成,另一线程抢夺并访问了该资源,导致该资源数据混乱情况的出现。