背景
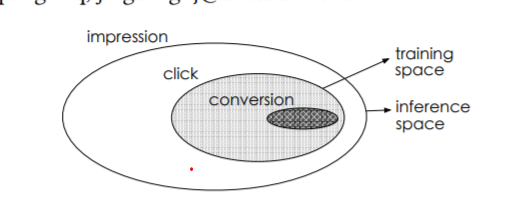
用户在网络购物时,遵循impression -> click -> conversion的用户行为序列模式,提高conversion rate是推荐系统和广告系统关注的重点。但传统的CVR分析模型存在三个明显的弊端:

-
SSR:sample selection bias。样本选择偏差,指商品在曝光后,用户点击并购买的行为被标记成正样本,用户点击但未购买的行为被标记为负样本,这样训练后的模型不适用于真实场景,因为该模型匹配的是click而真实场景给出的条件通常是impression。
-
-
延迟反馈:用户点击后到conversion有一定的延迟,在真实场景中表现为用户看到一个商品后并没有马上下单购买,而是加入了购物车;这时候,我们是否应该为其设置一个窗口,或者维护一个hash队列来延长采集数据的时间(借鉴上一篇Facebook计算CTR的方法)。
传统的解决方案
-
使用LR逻辑回归模型,该模型的难点在于在海量的用户和数据面前需要先验知识来构造继承结构。
-
过采样(oversampling),过采样方法可以有效解决某类样本稀疏的问题,但是过采样对采样率敏感。
-
AMAN采用了一种随机采样的方法来挑选未点击的曝光作为负样本,这种做法可以一定程度上降低SSB带来的问题,但也会导致估计不足。
-
无偏估计:会造成数据的不稳定性。
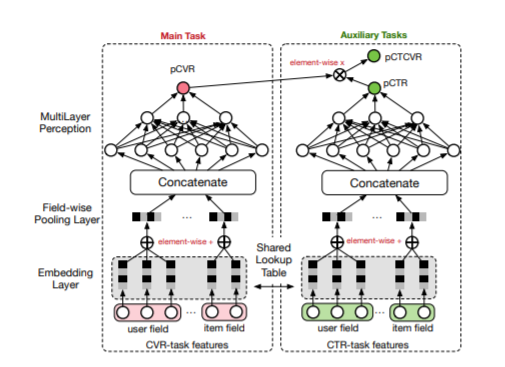
ESMM的解决方案
引入两个辅助任务:CTR, CTCVR代替传统直接对CVR进行测量,将CVR作为中间变量进行处理;因为CTR和CTCVR的测量覆盖了整个曝光的样本空间,所以在对CVR进行测量的时候也就解决了SSR和DS两个传统模型解决受限的问题。
实验
模型
BASE:共享嵌入层。

DIVISION:
P(z=1|y=1,x)=\frac{P(y=1,z=1|x)}{P(y=1|x)}
但除法无法保证CVR一定在[0,1]之间。
AMAN:应用负采样策略并且最佳结果出现在采样率为{10%,20%,50%,100%}的时候。
OVERSPAMPLING:复制正样本来减少数据的稀疏性
ESMM-NS:低级的ESMM,嵌入层不共享。
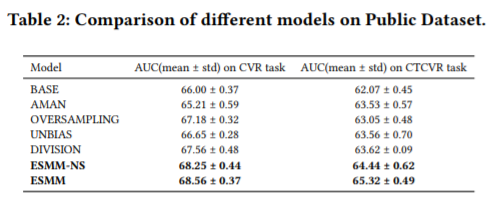

数据集
来源:淘宝推荐系统的交易日志。
Pubilc Dataset:公开的1%部分
Product Dataset:完整的交易数据。

度量
AUC:表示预测为正的概率值大于预测为负的概率值大的可能性。AUC越大表示分类器的效果越好
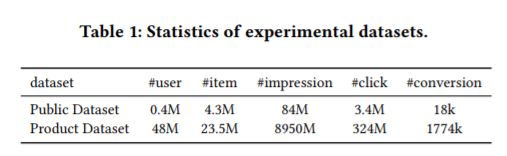
Result ON PublicSet:
-
在三个Base Model中,AMAN表现较差,可能是由于对采样率敏感导致的。
-
DIVISION和ESMM-NS都是在整个数据空间中进行采样的所以表现效果较好,但ESMM-NS表现更好,因为DIVISION有可能会出现除法溢出。
-
ESMM表现更优于ESMM-NS,
Result On ProductSet:
-
BASE MODEL 除了AMSN都被新模型打败。
-