一、索引简介
1. 为什么要使用索引
查询高效
2. 什么样的信息能成为索引
主键,唯一键,普通键等
二、优化你的索引
1. 二叉查找树
二叉查找树,也称二叉搜索树,或二叉排序树。其定义也比较简单,要么是一颗空树,要么就是具有如下性质的二叉树:
(1)若任意节点的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
(2) 若任意节点的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
(3) 任意节点的左、右子树也分别为二叉查找树;
(4) 没有键值相等的节点。
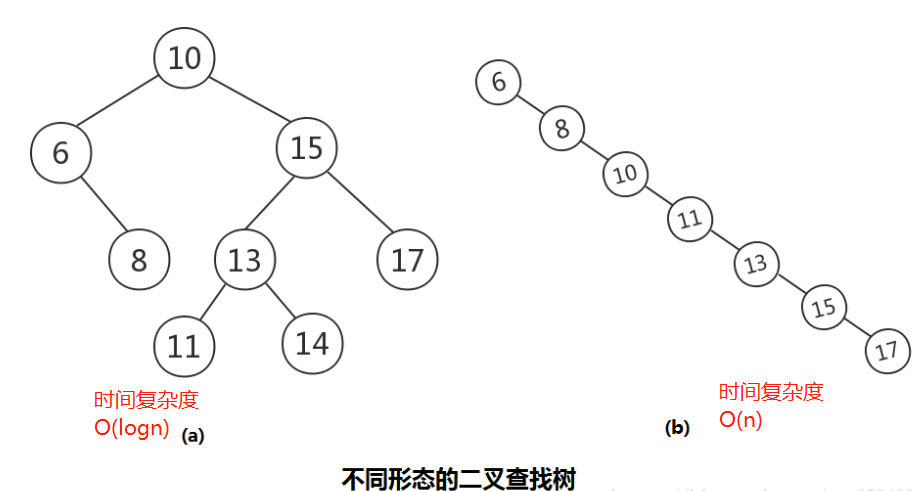
优点:
1.二分查找算法。
缺点:
2.影响数据库查询效率的瓶颈在IO,检索深度每增加 1 ,就会增加 1 次IO。无论是平衡二叉树还是红黑树, 每个节点都只有 2 个孩子,会导致树的深度 很深,影响查询效率。
2. B树
B树也称B-树,它是一颗多路平衡查找树。我们描述一颗B树时需要指定它的阶数,阶数表示了一个结点最多有多少个孩子结点,一般用字母m表示阶数。当m取2时,就是我们常见的二叉搜索树。
一颗m阶的B树定义如下:
1)每个结点最多有m-1个关键字。
2)根结点最少可以只有1个关键字。
3)非根结点至少有Math.ceil(m/2)-1个关键字。
4)每个结点中的关键字都按照从小到大的顺序排列,每个关键字的左子树中的所有关键字都小于它,而右子树中的所有关键字都大于它。
5)所有叶子结点都位于同一层,或者说根结点到每个叶子结点的长度都相同。

上图是一颗阶数为4的B树。在实际应用中的B树的阶数m都非常大(通常大于100),所以即使存储大量的数据,B树的高度仍然比较小。每个结点中存储了关键字(key)和关键字对应的数据(data),以及孩子结点的指针。我们将一个key和其对应的data称为一个记录。但为了方便描述,除非特别说明,后续文中就用key来代替(key, value)键值对这个整体。在数据库中我们将B树(和B+树)作为索引结构,可以加快查询速速,此时B树中的key就表示键,而data表示了这个键对应的条目在硬盘上的逻辑地址。
优点:
不会变成线性,层数少。
3. B+ 树
一种定义方式是关键字个数和孩子结点个数相同。这里我们采取维基百科上所定义的方式,即关键字个数比孩子结点个数小1,这种方式是和B树基本等价的。下图就是一颗阶数为4的B+树。

1)B+树包含2种类型的结点:内部结点(也称索引结点)和叶子结点。根结点本身即可以是内部结点,也可以是叶子结点。根结点的关键字个数最少可以只有1个。
2)B+树与B树最大的不同是内部结点不保存数据,只用于索引,所有数据(或者说记录)都保存在叶子结点中。
3) m阶B+树表示了内部结点最多有m-1个关键字(或者说内部结点最多有m个子树),阶数m同时限制了叶子结点最多存储m-1个记录。
4)内部结点中的key都按照从小到大的顺序排列,对于内部结点中的一个key,左树中的所有key都小于它,右子树中的key都大于等于它。叶子结点中的记录也按照key的大小排列。
5)每个叶子结点都存有相邻叶子结点的指针,叶子结点本身依关键字的大小自小而大顺序链接。
优点:
1. B+ 树 可以存储更多的关键字
结论
B+ 树更适合用来存储索引
1. B+ 树的磁盘读写代价更低,内部节点只存索引,不存数据,内部节点更小,一次性读到内存中的索引更多。
2. B+ 树查询效率更稳定。稳定的O(logn),从根节点到叶子节点的层级一样。
3. B+ 树更有利于对数据库的扫描。只需要遍历叶子节点就能实现对全部关键字的扫描,范围查询又很好的性能。
Hash结构
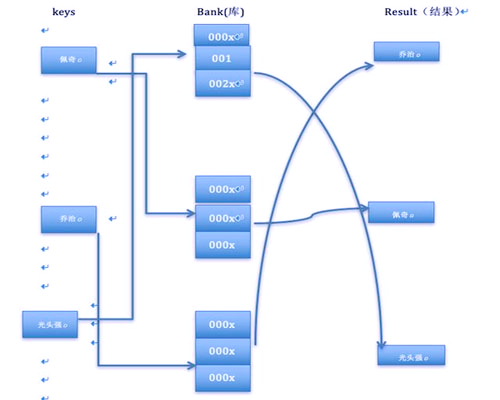
上图说明:当我们在搜索 “佩奇”作为键值,然后所谓的Hash索引就会在图片库中找到标识符也为“佩奇”的编码,然后就可以搜索出佩奇的数据了。所以它不属于范围搜索。
哈希索引的应用场景和不适合场景:
- 支持等值查询:前提条件没有过多重复的键值,如果存在的话,会降低哈希索引的效率,发生哈希碰撞问题。
- 范围查询则不合适哈希索引
- 哈希索引不能被用来避免数据排序操作
- 哈希索引不支持最左匹配规则,因为键值更换成哈希值是单向的
三、密集索引和稀疏索引

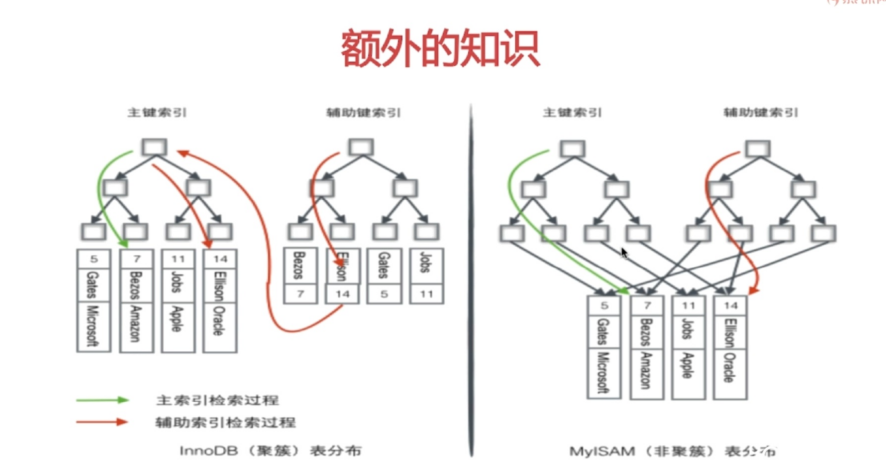
1. InnoDB 数据和索引是存储在一个地方的。 .ibd文件
2. MyISAM 数据和索引存储在不同地方。
四、索引产生的问题
1.如何定位并优化慢sql?
- 根据慢日志定位慢查询sql
show variables like '%quer%';

show status like '%slow_queries%'

# 将慢查询 sql 记录日志打开 set global slow_query_log = on; # 超过一秒钟。即记录为慢sq set global long_query_time = 1;
- 使用explain等工具分析sql

关键字段
- type 项: index,all 走的全表扫描,需要优化
- extra 项:Using filesort,表示MySQL会对结果适用一个外部索引排序,而不是从表里按照索引次序读到相关内容,可能在内存或者磁盘上进行排序。MySQL中无法使用索引完成排序的操作被称为“文件排序” 、
Using temporary ,表示MySQL在对查询结果排序时,使用临时表。常见于排序order by和分组查询group by。
- 修改sql或者尽量让sql走索引
- 这里要注意特定场景,密集索引可能有时候执行的比稀疏索引慢。可以使用fore index(primary)来对比,sql优化器和自己指定走哪个索引的时间对比。
2.联合索引的最左匹配原则的成因?
最左匹配原则:
1. 最左优先,以最左边的为起点任何连续的索引都能匹配上。同时遇到范围查询(>、<、between、like)就会停止匹配。
例如:比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,因为c字段是一个范围查询,它之后的字段会停止匹配。
2. = 和 in 可以乱序,如 a = 1 and b = 2 and c = 3 建立 (a, b ,c )索引可以任意顺序,MySQL查询优化器可以帮你优化为索引能识别的形式。
最左匹配原则原理:
最左匹配原则都是针对联合索引来说的,所以我们有必要了解一下联合索引的原理。了解了联合索引,那么为什么会有最左匹配原则这种说法也就理解了。
我们都知道索引的底层是一颗B+树,那么联合索引当然还是一颗B+树,只不过联合索引的健值数量不是一个,而是多个。构建一颗B+树只能根据一个值来构建,因此数据库依据联合索引最左的字段来构建B+树。
例子:假如创建一个(a,b)的联合索引,那么它的索引树是这样的
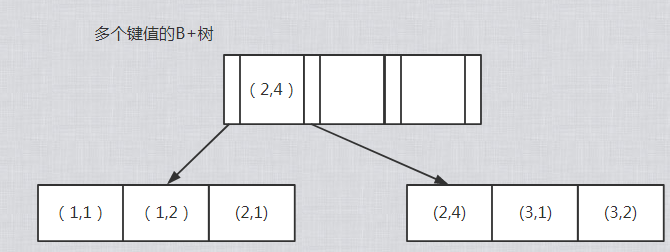
可以看到a的值是有顺序的,1,1,2,2,3,3,而b的值是没有顺序的1,2,1,4,1,2。所以b = 2这种查询条件没有办法利用索引,因为联合索引首先是按a排序的,b是无序的。
同时我们还可以发现在a值相等的情况下,b值又是按顺序排列的,但是这种顺序是相对的。所以最左匹配原则遇上范围查询就会停止,剩下的字段都无法使用索引。例如a = 1 and b = 2 a,b字段都可以使用索引,因为在a值确定的情况下b是相对有序的,而a>1and b=2,a字段可以匹配上索引,但b值不可以,因为a的值是一个范围,在这个范围中b是无序的。
3.索引是建立的越多越好吗?
- 数据量小的表不需要建立索引,建立会增加额外的索引开销。
- 数据变更需要维护索引,因此更多的索引意为着更多的维护成本。
- 更多的索引意为着也需要更多的空间。
参考:
https://www.cnblogs.com/nullzx/p/8729425.html
https://blog.csdn.net/MuErHuoXu/article/details/85264634
http://developer.51cto.com/art/201904/594333.htm
最左匹配原则都是针对联合索引来说的,所以我们有必要了解一下联合索引的原理。了解了联合索引,那么为什么会有最左匹配原则这种说法也就理解了。
我们都知道索引的底层是一颗B+树,那么联合索引当然还是一颗B+树,只不过联合索引的健值数量不是一个,而是多个。构建一颗B+树只能根据一个值来构建,因此数据库依据联合索引最左的字段来构建B+树。
例子:假如创建一个(a,b)的联合索引,那么它的索引树是这样的
可以看到a的值是有顺序的,1,1,2,2,3,3,而b的值是没有顺序的1,2,1,4,1,2。所以b = 2这种查询条件没有办法利用索引,因为联合索引首先是按a排序的,b是无序的。
同时我们还可以发现在a值相等的情况下,b值又是按顺序排列的,但是这种顺序是相对的。所以最左匹配原则遇上范围查询就会停止,剩下的字段都无法使用索引。例如a = 1 and b = 2 a,b字段都可以使用索引,因为在a值确定的情况下b是相对有序的,而a>1and b=2,a字段可以匹配上索引,但b值不可以,因为a的值是一个范围,在这个范围中b是无序的。